The Singing Voice
“Should someone want to change his own type, just as having a bass voice naturally and because lacking the soprano he would imitate the voice called falsetto, it would be possible by making the movement of the air faster, to produce it in its place”. Giovanni Maffei, 1562.
“It would be a blessing if the term ‘boy voice’ could be abolished entirely. . . The boy’s voice is plastic; it is capable of marvellous development;” George Stubbs 1894.
Introduction: is there a “singing voice”?
Hitherto we have devoted significant space to the relationship between boys’ speaking voices and their growth during puberty. Voices deepen first steadily and then rapidly as as a consequence of puberty. Longitudinal measurements of speaking voice pitch can usefully tell us whether and how a boy is progressing through puberty and the same measurements correlate well with longitudinal measurements of height.
Belief in a “singing voice” is widespread, as is the tendency of empiricists to equate this with a so-called “head voice” in boy choristers. Roy Massey described to me how he used to assess the suitability of new recruits to his Hereford choir:
The first thing I had to do was to discover whether you could find a head voice because by and large if you say to a boy sing a note he goes ‘ahhhh’ like this and so one had to discover whether you could find a head voice and sort out ways of producing that, even from the most unlikely material, not everybody can do it of course but by and large the average boy can be taught to use his voice in a way different from the football field. (Massey in Ashley, 2008: 111).
Leon Thurman, however, suggests an alternative scientific view in which there is only one voice, found neither in the head nor the chest [or on the football field] (Thurman et al 2004). Thurman and his colleagues continue by questioning the commonly encountered term “singing voice”. We probably know what people mean by this, but they state that scientifically “this type of distinction is not used in any other area of human neuromuscular activity. We do not say that we have walking legs and running legs or pushing arms and pulling arms. . .” (ibid. 49).
In this chapter, I shall take the scientific view that there is only one voice, originating in the larynx and developed by the tract, but that once puberty begins, boys can use it in many different ways with varying degrees of skill.
Ages at peak performance
We looked in the previous chapter at the extent to which there have been any trends or tendencies for puberty and consequently voice change to advance in timing. In 2013 I published a cross-sectional study of 150 boy choristers. Five cathedrals and two Oxbridge collegiate choirs were visited. Boys were seen individually and completed a shortened version of the voice protocol designed for my longitudinal studies. Puberty stages were estimated through SF0, total singing range and lift points within glides. The results are summarised in the bar chart below.
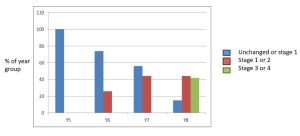
That any choristers at all might be at stage 4 may surprise some, but it is quite possible for teenage boys in middle adolescence to produce a strong and sometimes beautiful tone in the soprano range. Occasionally, the technique is maintained into late adolescence and very occasionally even adulthood. The historical significance of this is considerable and will occupy discussion in later chapters. So also is the current cultural and social significance. We shall examine that question in another chapter through interviews with living boys who are experiencing voice change.
In this chapter we are going to explore purely the technical questions. We will need to look at:
- How the soprano voice is retained during puberty;
- Why only some boys can do this;
- Why doing so is considered undesirable by some singing teachers and phoniatricians.
We will also need to look at the alternative. Commonly referred to by such terms as “cambiata” or “emerging baritone” the new voice of the young man from puberty stage 3 or 4 onward takes time to develop into a full tenor or bass voice. The interim voice will be weaker and duller in timbre than either the soprano/treble voice that came before it or the tenor or bass voice that will come after it. This is an issue that any mid-adolescent boy with an interest in singing is going to have to confront.
The table below has been constructed from my longitudinal studies. It shows the percentage of boys at each of the four phases identified in Chapter 3 who left their choir because of a “broken voice”. It also shows the percentage at each phase who gave their “peak performance” as a soprano/treble. “Peak performance” was defined as the performance given during a CD recording, concert appearance or solo of particular importance. The longitudinal study allowed the peak performance to be located within the history of physical development for each boy and compared with performances given before and after the “peak”.
Phase reached by peak performance and choir dispensation
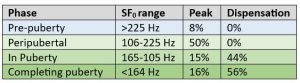
From this we can see that the peripubertal phase is the key one for currently living boys. Half the sample gave their peak performance during this time and none was dispensed from his choir before actual pubertal onset. The peripubertal phase is most common during Y7 (ages 11 – 12, US grade 6). Y7 was described by David Flood as the “golden year” for the choristers of Canterbury Cathedral when interviewed for my 2014 book. This can be compared with Andrew Nethsinga’s experience that around Y8 (ages 12 – 13) is “when boys’ voices begin to peak”.
The age common to Flood and Nethsinga’s experience is twelve, which of course crosses the Y7/8 boundary. There is, of course, no direct relationship between puberty phase and school year. As we have seen a peripubertal or even prepubertal boy could be in Y8, whilst another boy could be completing puberty during Y7. Moreover, as almost any teacher of that age group will testify, there are for some uncanny reason “good years” and “bad years” and “tall years” and “short years”, so we must allow some leeway.
What matters more is that 56% of boys left their choirs once they had begun the completing puberty phase whilst 44% remained in their choirs after pubertal onset. Looked at another way, 44% of the boys were still singing with the treble section of their choir after their voices had, in popular parlance, “broken”. Some, as we shall soon see, might have been doing little more than miming, but 16% actually gave their peak performance during this time.
Technique, not testosterone
One of the earliest and most celebrated “peak performances” to be captured by recording is that of Ernest Lough who recorded Mendelssohn’s Hear My Prayer at the age of fourteen and a half in 1927. The recording, the first to sell over a million discs, became so popular that Lough had to record it twice more. Wax discs in those days had a limited life span and wore out after so many pressings. Consequently he was aged nearly sixteen by the time of the final version. He described this voice as “fruitier” when interviewed many years later as an adult and continued singing soprano until his voice supposedly “broke” at age seventeen.
We do not know when pubertal onset occurred for Lough, nor when he reached PHV (see chapter 3), but it should be clear from the previous chapter that the “fruity” soprano voice was that of a young man who almost certainly had reached PHV if not passed beyond it. The soprano voice, in other words, was not the product of any delay in the production of testosterone, but in the way he had been trained to use his voice.
The years after the Lough era saw a fundamental change in the approach to boys’ singing. Edward Bairstow wrote disparagingly of the kind of regime under which Lough and his contemporaries had been trained.
The old idea of starting boys with head notes was silly and unnatural. A boy has a middle voice like a woman, not head and chest notes only. His chest notes are rarely used. The old way gave boys a weak artificial tone in the very part of their compass they used most frequently. (Bairstow, undated).
The views of George Malcolm are often cited. Malcolm was an early exponent of historically informed performance and an enthusiast for period instruments. He believed that he had found a more authentic approach to the music of the renaissance by encouraging a more “natural” tone in boys through the use of the voice with which with which they “talk, or laugh, or cheer at a football match” (Malcolm 1967). Benjamin Britten’s patronage and preference for this “ragazzo” sound is well known and examined in depth by Coyle (2020).
It may well be that Malcolm was correct in his analysis and prescription of voices needed for renaissance polyphony. This is something we are going to have to consider later when we look at the use of boys in historically informed performance. However, one physiological consequence of the Malcolm approach is that boys’ voices appear to “break” at younger ages. This younger age of “break” at any age between twelve and fourteen has become somewhat the norm since Bairstow’s day and there is rather more to it than a fatalistic submission to “puberty coming sooner”. As we saw in the previous chapter, puberty is not coming that much sooner. When we take account of the considerable range in the tempo of the development of living boys, there will be no shortage of thirteen-year–olds alive to day who are physically less developed than some thirteen year olds alive in the 1930s.
Registration and the “head voice”
A commonly encountered explanation for the ragazzo sound is that Malcolm introduced the “chest voice” to chorister singing. According to this explanation, choristers had sung previously only with the “head voice”. This is at best an over-simplification and certainly out of step with the direction of modern voice science. We are going to need to devote the best part of this chapter to deconstructing some of the ideas that have grown up around “chest voice”, “head voice” and “falsetto”.
Adult male classical singers devote much effort in their training to the production of continuous, even tone throughout their range. Readily perceptible changes in tone are due to registration breaks and these may be of two kinds, acoustic and laryngeal. Acoustic registration breaks are due to the voice “turning over” when rising pitch causes harmonics to catch up with or overtake formants. The phenomenon is explained extremely well by Kenneth Bozeman is his book Practical Vocal Acoustics (Bozeman, 2013). Laryngeal registration breaks are often more obvious and result from abrupt changes in the balance of antagonistic action of the principal muscles of the larynx responsible for pitch, the thyroarytenoids (TA) and the crycothyroids (CT). This was demonstrated in an interesting and convincing way back in 1999 by Švec et al who compared a cadaver with two live singers.
The 1970s were a watershed that saw a concerted attempt to break from the idea of a “chest” and “head” voice, culminating with the CoMeT international committee on vocal registers proposing numbered register designations (most commonly now M0 – M3) that avoid the misleading terms “head” and “chest”. In Hirano’s classic (1973) model the two main modes of phonation for most singing, at least as far as dead composers are concerned, are the M1 and the M2. Of these, the M1 is the most used. TA and CT muscles act antagonistically throughout the range, though the TA muscles are dominant in “chest” and the CT progressively more dominant as the voice moves towards “head”. The main laryngeal registration event occurs when the TA muscles become flaccid and tension in the vocal folds is achieved by the CT only.
The voice has then moved to M2, which is commonly called “falsetto” in males. The reader requiring a more detailed explanation of this is referred to Hirano’s original paper Morphological structure of the vocal cord as a vibrator and its variations (Hirano, 1973). Many modern textbooks on singing currently available give similar accounts. However, understanding has progressed further since then, propelled amongst other things by the problem of “mixing” registers and specifically the voix mixte. How there could be a mixed middle register when only two distinct laryngeal registers had been shown encouraged Michèle Castellengo and colleagues to propose and investigate an acoustic explanation based upon singers’ adjustments of resonance.
Castellengo had studied Garcia’s writings in depth and, whilst recognising his genius, was troubled by what she saw as his weakness and inconsistency in proposing a “falsetto-head register” (Castellengo, 2005). She later claimed to have demonstrated that a voix mixte can be produced equally by either M1 or M2 phonation through singer control of intensity. A reduction in intensity at the higher end of the M1, or a corresponding “imitation of M1 quality” by the M2 through timbre enrichment resulting from increased loudness both resulted in a voix mixte spectrum. Titze had already suggested a that progressive changes in acoustic spectra may occur as a result of either an adductory change or a loudness change (Titze, 2000). These papers present an attractive explanation in that I have found evidence in my work with boys when asking them to sing the same note in “falsetto” and “normal voice” that they instinctively adjust loudness with consequent effects on the acoustic spectrum produced (see p 116). Unfortunately, Castellengo’s paper has been questioned more recently by Herbst (2021) who cites evidence that her position may be inconsistent with recent evidence from high-speed-video recording and electroglottography. The field of knowledge is still developing. All we can do is remain alert to developments that may affect our understanding of how boys sing.
There is no shortage of texts that set out current theories of the “power-source-filter” theory of voice production in detail. Singing and Teaching Singing by Janice Chapman with chapters by Ron Morris remains one of the most reliable and comprehensive (Chapman and Morris, 2021). The one thing that none of these texts deal with is the boy singer. A consequence has been a tendency to assume that what is written about adult voices largely applies to boys’ voices. However, I made the point earlier that boys are not miniature men and nowhere is this the case more than when it comes to vocal registration. It was a relief to read in Trollinger (2007) that Thurman is quite correct to question the term “singing voice”. She wrote that “telling children not to use the modal or speech adjustment is out-of-date and incorrect” for the simple reason that a child “has only one voice and only one vocal register”. Pathologies such as pressed phonation in speech can result from the false dichotomy of speaking and singing voice (Trollinger, 2007: 21).
Boys do not begin to experience laryngeal registration changes until they are some way through puberty. This simple fact eluded me for many years and I spent many fruitless and frustrating hours trying to understand why I could see no laryngeal breaks in the many recordings of vocal glides by boy choristers I had made. The key word here is “child”. No “head or “chest” quality in the unchanged voice of a boy child can be ascribed to register change in a continuous voice that has no laryngeal breaks. Small acoustic breaks can be detected, certainly. These would seem to exist in inverse proportion to the degree of training and experience (Weinrich et al, 2020). Moreover, TA dominant singing by boys can be harsh and strained towards the top of the range where gentle downward vocalisations from the high end of the range will encourage a longer lasting more CT dominant production that sounds more “choiry”. We will need to examine this later.
The position begins to change at some point midway through puberty. John Cooksey’s work is particularly helpful as an introduction to this topic but we will not understand how boys and men differ until we stop using the archaic terms “head voice” and “chest voice”. In order for distinct M1 and M2 registers to appear, a vocal ligament that functions in the way adult ligaments do is likely to be necessary. It is well established that the vocal ligament does not fully mature until as late as sixteen years of age. Trollinger is one of the few writers to have directly stated that the lack of a mature ligament accounts for the absence of laryngeal registration in young voices:
The lack of a functional vocal ligament means that children do not have the registration events we associate with singing. Without a functioning vocal ligament, children produce most pitches for singing and speech by lengthening and thickening their vocal bands with their larynx in rest position. Since the bands are fairly short, they are limited to how much they can stretch, which results in a small pitch range for singing. (Trollinger, 2007: 20).
Skelton (2007) speculates on whether training in any way hastens the development of the ligament:
Yet exactly how “immature” is the vocal ligament at ages twelve and sixteen? More importantly, does the vocal ligament “mature” as a result of physical growth alone? Or, does this “maturity” of the vocal ligament stem from voice use? Considering the level of vocal control some children around the age of ten attain, I would suggest that voice training (rather than vocal growth alone) can have a significant impact on a young singer’s capability for regulating vocal parameters (Skelton, 2007: 540).
It is certainly true as Trollinger observes that children’s voices have smaller ranges of both pitch and dynamics than adult voices but there is a potential difficulty here with the fact that trained boy trebles can have somewhat larger ranges than untrained child singers of similar age. Welch et al have shown how the range expands throughout the primary school years from G3 – C5 at age seven+ to F3 – Eb5 at age ten+ (Welch et al, 2009:34). These are actually quite large ranges, achieved during the years when there was government support for primary school singing in the form of the Sing Up initiative. F5+ (as identified by Cooksey) or G5+ are more likely terminal pitches for child choristers. The role of ligament maturation, if any, in the expansion of range up until the point at which separate M1 and M2 registers appear is unclear.
What we do know is that adult vocal folds have three distinct tissue layers. These are the innermost thyroarytenoid muscle, a middle layer of collagen fibres comprising the ligament, and an outer layer of mucosal tissue comprising the epithileum. This laminate structure is not present during the early years. Until the age of about seven, it is difficult to detect a three-layered structure. Hirano et al (1981) concluded that the vocal ligaments reach mature structure between 12 and 16 years. Thirteen is commonly quoted for the appearance of adult like properties in which a maturing ligament begins to result in stiffening, increased tensile strength and greater elasticity.
Whether greater range is purely the result of training and intensive daily singing seems likely but has not to my knowledge been demonstrated. Michael Fuchs and colleagues produced a potentially useful tool for doing this. Their aim was to develop and validate a reliable and valid means of classifying the intensity of voice use that could be used to compare outcomes for vocal parameters and pathologies. Extensive work was carried out with physicians/logopaedists, choir trainers/singing teachers, music teachers and lay people to establish the reliability and consistency of the classifications. Allocation to classes was carried out by a validated interview protocol.
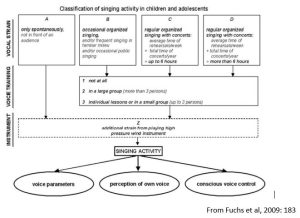
A B2 classification might describe boys who join a school choir or community choir that rehearses weekly or less and performs perhaps once a term in a concert. The activity level of most cathedral choristers would be much higher at D3 on this scale. They spend more than 6 hours per week on regular rehearsal and performance and almost all have individual lessons and/or instruction in small groups. That the average age of thirteen coincides with John Cooksey’s identification of the first possible laryngeal registration event in a young singer seems unlikely to be pure coincidence. It is time to scrutinise what John Cooksey had to say on the matter.
The Midvoice
“Midvoice” was the term devised by Cooksey to describe voices that were undergoing the earlier changes, losing their childhood quality but not deep enough to reach the critical C3 (tenor C) of which adult singers are capable. He recognised three stages of Midvoice; Midvoice I (“stage 1”) Midvoice II (“stage 2”), and Midvoice IIa (“stage 3”). His original (1977) publication agreed with the principle that there are no adult registers. Of the unchanged voice, he wrote:
Only modal sound of soprano-like quality throughout the range. No lift points apparent yet (Cooksey, 1977c: 6).
Cooksey is referring here to the single child register as “modal”. Later, he found it necessary to clarify the term “lift point”. A “lift point” is not a laryngeal register break. In 1992 he wrote that boys with unchanged voices “may sing too heavily in the lower range, and, therefore, shift quite noticeably when going to higher pitches” (Cooksey, 1992: 55). Faults such as this were described as “pitch breaks” by Weinrich et al (op. cit.) who identified them as perceptual events, not M1 – M2 shifts in vocal mechanism. They found that such pitch breaks were more common in the unchanged voices of the “elite” Cincinnati Boychoir than in the Midvoice Is of that choir, and attributed the difference to relative levels of experience and training. There is a clear case here for comparative studies using the method proposed by Fuchs.
The earliest hint of discrete M1 and M2 phonation was identified by Cooksey as a defining characteristic of Midvoice II. In 1977 he wrote that “register differentiation becomes apparent as the falsetto register emerges around b, c1, d1 area in treble clef [i.e. B4 – D5] (ibid, 7). In 1992 he confirmed the existence of a “transition zone (passagio) between modal and falsetto registers was F4 – C5” with falsetto beginning at G4 – D5, and A4 for the majority. It is at this point that the desirability of the scientific register designations M0 – M3 becomes apparent. When Cooksey employs the term “falsetto” he means M2. This is not “head voice”.
The adult “head voice” is the lighter, upper end of the M1. In most boys the M2, when it first appears, is thin, scratchy, liable to “crack” back into M1, and totally devoid of any expressive capacity (or beauty). It should come as no surprise if the previous chapters have been studied that the chronological age for this condition is wide ranging. It might be found in a boy of ten, or could be yet to develop in a boy of fourteen. Laryngeal registration breaks are easy to spot through acoustic spectrography. The example below is of a boy aged twelve years and five months who had reached this point:
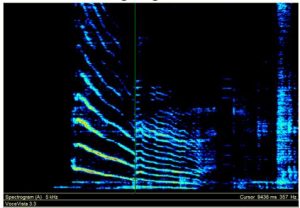
To single out any one school year as “golden” is perhaps optimistic. The above would not be a “golden” voice. However, if we refer back to the peak performance table, we will see that 68% of boys gave their peak performance before this condition, whilst 31% gave their peak performance after it. The matter is far from simple and we would do well to note that were Lough’s Hear My Prayer to be added to the table, it is the latter percentage that would be boosted at the expense of the former.
A likely explanation for this is found in Cooksey’s analysis of what happens beyond the midvoice. The stage 4 (“new baritone”) voice, unlike those of earlier stages, shows a discrete M1 and M2 register quite clearly. There is quite often a complete phonational gap between the two (see Willis and Kenny, 2008) where no notes will sound. Cooksey identified this as likely to occur around E4, with most boys being securely into M2 by G4. If the ideal in classical singing is a seamless passagio, a complete change in timbre after a missed out note is the antithesis of that. An adolescent member of the Stockholm Voicebreak Choir identified E4/F4 as the “devil’s note”, a term that seems so apt I have taken to using it myself (Stahl, 2021).
There are different schools of thought regarding what should be done about this. Probably the more dominant one at the present time is that of Irvine Cooper, who devised the cambiata system. Cooper advocated that during middle adolescence only the M1 voice should be used. Ventures across the gap to M2 are best left until later stages of maturity. McClung (undated) has updated Cooper’s work to bring it more into line with Cooksey’s (Cooksey was a student of Cooper). OUP’s Emerging Voices series that I edit employs this principle, though this does not mean it carries my unqualified endorsement. Cooksey did not say that a boy should not use his falsetto, only that he will find it easier to do so as his voice matures across stage 4 into stage 5.
Fewer people, probably, will be acquainted with the late George Bragg of the Texas Boys Choir (founded 1946). Bragg advocated due caution during the most difficult time of mutation (now recognised as stage 3) but once this had passed, the boy could if he wished, enjoy a glorious soprano swansong. He wrote
Once he is over this hurdle, there is a period of approximately one year which can, by all standards and results, be the most wonderful year of all his choir days. It is a time when he can assert his authority as never before because of his advanced experience. It is a time when he can assert himself vocally with assurance (cited in Beet, 2023)
Four such “swansongs” are described in Ashley (2018) and constitute the 16% of boys who gave their peak performance during the completing puberty phase. I have no shortage of examples of other mid-adolescent baritones who can produce with their M2 a pure sounding soprano voice but choose not to. The example below is of one who chose otherwise, singing the Duruflé Requiem well after “voice break” at age 13:07.
Duruflé Pie Jesu
Perhaps better known than Bragg is Henry Leck. Leck has successfully shown that it is quite possible to eliminate the devil’s note and any laryngeal “clunk”. In this, he is following Frederick Swanson, who stressed that both modal and falsetto portions of the voice could be used to achieve an expanded range during the months or years of transition. Describing himself as a practitioner (a highly skilled one according to others’ judgements) he wrote in the empirical tradition:
Then, lo and behold, a miracle happened. I discovered that if a boy sings from his high voice to his low range consistently and continues to sing in the old voice whilst developing the new, the break eventually disappears (Leck, 2009).
His methods are described in Leck (2009).
Making the audible visible
The dynamic between empirical knowledge derived from observation of practice (which includes listening!) and scientific knowledge derived from measurement that was introduced in Chapter 2 should be a familiar theme by now. Whilst it is possible up to a point to identify Cooksey stages by observation, Cooksey himself provided measurements that introduce objectivity and precision that take us beyond perception. His last significant publication reproduces a definitive series of narrowband spectrograms (Cooksey, 2000: 728). Those defining the unchanged and stage 1 (midvoice I) voice are reproduced below.

The task of discriminating between an accomplished unchanged and midvoice 1 singer, particularly when heard in the flattering acoustic of a large church, is one that would defeat many listeners, but the spectrograms brook no argument. The voice on the right that has begun to change has lost intensity in its higher partials, a process that is going to continue and reach its nadir at stage 3. The absence of a full set of higher partials together with an increase in air turbulence (heard by some as “breath noise”) define this as a midvoice I more than the opinions of any listener.
In spite of this, perceptually based studies have continued to dominate the literature. The ability to distinguish between an unchanged voice and one that merely sounds unchanged on account of singing at the same pitch range is clearly an important one that teachers and conductors should possess. The question, from a practical point of view, was investigated by Wayman (2009). Wayman prefaced his investigation thus:
Previous research indicates that the unchanged voice and the falsetto voice share similar qualities, yet represent very different parts of the maturation process, possibly leading to some unsuccessful educational situations in the choral classroom (Killian & Wayman, 2010).
He wrote that a boy’s voice is not considered changed until it reaches a stage of development sufficient to reveal an audible change. In theory, this should be midvoice I, as soon as change begins and decreased upper partial strength and air turbulence begin to appear in spectrograms. Yet many listeners do not detect such an audible change, particularly when boys are singing in chorus in resonant acoustics. Wayman’s study was perceptual. Four expert listeners were engaged to hear 31 boys in Y7 – 9 (US grades 6 – 8) perform a 1-5-4-3-2-1 vocalise at all available pitches in their ranges. An expert male vocalist singing the vocalise in falsetto was used as a stimulus. The expert ratings were then used to compile a bank of eight recordings to play to the 61 pre-service music educator test subjects. The four most obviously unchanged and falsetto voices each singing the vocalise beginning on E4, F4, and F#4 (C#5 therefore being the highest note heard) were used.
In brief summary of some detailed and carefully analysed results, unchanged voices were identified more accurately than falsetto voices, and male students did better than female in identifying falsetto. The table below is an extract from a more detailed tabulation in the thesis to show the perceptual qualities most frequently identified by the most successful listeners on completion of test and retest procedures.
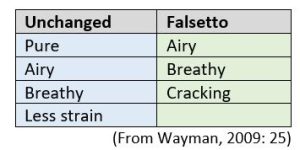
The inclusion of “breathy” in the unchanged column is notable. It is possible that some of the “unchanged” voices may have been midvoice I, a factor that did not appear to be controlled in the study. We can be confident that the expert listeners’ perceptual judgements were correct because they had the advantage of hearing the boys sing notes too low for unchanged voices. The test subjects did not hear these. A key significance of this study is the question of how well English choir directors and music teachers working regularly with young adolescent boys would perform on the same test. I have been struck in the past, on the one hand, by how some expert singing teachers readily identify falsetto in a chorister’s “treble” and on the other hand how oblivious some working mainly with church choirs are to the fact that some of their boys have at least reached Midvoice II (Stage 2) or even Stage 3.
Cooksey wrote that experienced judges can readily identify perceptually the onset of voice change. In this passage he writes of the agreement between his sonographic evidence and experienced perception:
With the onset of voice transformation, however (Midvoice I) the sonograms of F0s at C5 and above showed high ratios of air-turbulence noise, and the judges perceived the tone qualities as effortful, strained and breathy (Cooksey, 2000: 727).
The Cincinnati Boychoir study (Weinrich et al 2020), referred to briefly above, was also perceptual. This was one of the more significant studies of recent times and was predicated on the observation that “the relationship between perception and acoustic measures has not been documented in the literature” (Weinrich et al, 2020: 141). The authors compared the unchanged and midvoice I voices of the Cincinnati Boychoir.
Fifteen singers at the unchanged stage from the Cincinnati Boychoir were compared with thirteen singers at midvoice I from the same choir, described by the authors as “elite”. Boys in the most experienced treble section attend two main rehearsals per week, totalling 3.5 hours – less intensive than an elite German or English choir, though more intensive than most school choirs. Each boy sang in an anechoic chamber provided by the Cincinnati Children’s Hospital. They performed glides across the intervals of 1-3-1, 1-5-1 and 1-8-1 from four different starting notes (G3, C4, F4 and A4) and sang the Star-Spangled Banner (SSB), which has a range of a twelfth, typically from A3 – E5 for children’s voices. A panel of experienced expert listeners rated the SSB as “yes” or “no” for perceived pitch break. Pitch break was defined as a “a characteristic perceptual change that indicates a young man may be transitioning through puberty” (Weinrich et al, 2020: 142).
A 14.5 cm visual analogue scale (VAS) was used for the perceptual qualities of breathiness (none – severe), timbre (dark – bright), voice quality (simple/light-hooty/round) and overall vocal quality (poor – exceptional). The unchanged boys exhibited more pitch breaks in all tests than the midvoice I boys. The latter exhibited no pitch breaks at all on the 1-3-1 glide beginning on G3, C4 and F4 whereas pitch breaks were detected in this glide at all pitches for unchanged. No significant difference in the four perceptual qualities was found between unchanged and midvoice 1 with the exception of breathiness. This increased from unchanged to midvoice, and continued to increase thereafter in those boys who were studied up to the new baritone stage (mean VAS increase 4.6cm between stage 0 and 4). The authors attributed the greater occurrence of pitch breaks in unchanged voices to untrained vocal musculature associated with the length of experience.
Valuable though both these studies are, we are left with a degree of guesswork and speculation about “untrained vocal musculature” in the latter case or the “airy” and “breathy” qualities identified in both unchanged and falsetto voices in the former. Arguably, such doubts might be reduced or removed altogether were objective visualisation to supplement or replace perceptual methods. Barlow and Brereton (2008) examined the possibility of realtime visual feedback in vocal pedagogy with children. They identified what has long been the Achilles heel of empiricism:
Singing teachers often use visual and mental imagery to communicate improvements, requiring the student to translate before he/she can modify performance behaviour, leading to considerable opportunities for misinterpretation and misunderstanding between teacher and learner (Barlow and Brereton 2008: 1).
They pointed out that measuring instruments used in vocal clinics investigating pathologies are too intrusive in the teaching of singing. Garcia’s original dental mirror would be a case in point, though much the same can still be said of modern electronic laryngoscopes. However, with modern computing, relatively inexpensive tools such as the Voce Vista ® system are regularly used in adult vocal pedagogy. Voce Vista is now a powerful system that can display acoustic information about the vocal tract and voice source information about the larynx.
Real time visual feedback as a means of improving children’s singing has been a subject of interest for some time but has yet to be adopted to any significant extent by those who teach singing to children or adolescents. Software such as Sing and See ® has the potential to improve intonation and the pitching of intervals but Barlow and Brereton report that programmes that display only one parameter result in improvements in that parameter only and neglect of or regression in other aspects of singing when used by children. As a tool for seeing and measuring what is happening in a child’s voice, a programme such as Voce Vista that can display real time acoustic and voice source data can liberate us from the traditional constraints of our ears, however practised these might be. I describe here the principles and methods which are used in the case studies in the following chapter.
Acoustic data are displayed in the form of a spectrogram and a power spectrum. The spectrogram displays time, frequency, and intensity. Time is the horizontal axis whilst frequency appears as bands on the vertical axis. Intensity is indicated by the hue of the frequency bands. Extraneous noise such as air turbulence will also appear as random “white noise”, which is particularly useful for the assessment of changing voices. The ear may not always hear it, but the spectrogram will see it. A power spectrum displays the intensity of each harmonic as vertical peaks, and formants can be identified where harmonics are strong and clustered together. The power spectrum, which is produced by a Fourier transformation, does not show time. A long-term average spectrum (LTAS) can be generated by averaging successive frames.
The spectrograph below shows an eleven year old chorister singing an ascending scale to G5.
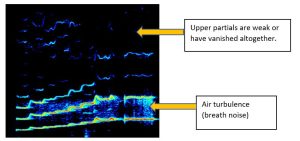
The spectrum is simple and the number of harmonics is small, indicating that this is a treble voice (more harmonics are available to resonate at pitches an octave lower). Breath noise can be seen to increase with pitch whilst higher partials in the 4 – 5 kHz band fade away towards the G5. From this, we might deduce that the boy is a midvoice I (stage 1 of change).
The power spectrum below, generated by the Praat software, shows a strong unchanged voice singing the word “me” on the note C#5.
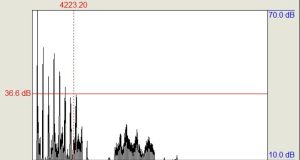
Here we can see resonance in the 4 – 5 kHz band, which Howard et al (2014) suggest is a child’s equivalent of the singers’ formant. There is also a boost of partials in the 7.5 – 11 kHz region. Such resonances are not often found in a boy’s voice, suggesting that this one has “ring”. The sample was taken from the dry voice only track of a Decca recording, so the voice had clearly been judged an exceptional one.
The two spectrograms below show the note D5 sung by an ex-chorister aged just fifteen whose voice as far as the choir was concerned had not yet “broken”.
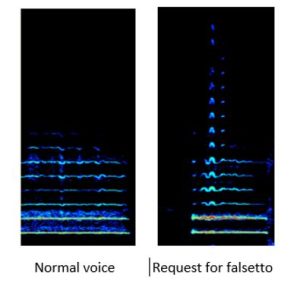
On the left, the boy simply sang the note in his regular “singing voice”. He was asked whether he could sing it again in falsetto and the result is on the right. The normal voice has air turbulence and weak higher partials. On the right, the air turbulence disappears whilst the high partials appear stronger with a hint of vibrato which is not what we would expect from a boy breaking into falsetto. There is no change in the frequency distribution of the partials and no indication of any shift in laryngeal registration. A possible explanation is that, when asked to sing “falsetto”, the boy presses his vocal folds more tightly and/or increases sub-glottal pressure. Clearly he cannot choose at will an M1 or M2 mechanism for the same note. This more likely shows how he produces a voix mixte effect (see above). We can learn a lot from a spectrogram, though we cannot learn everything.
Voice source data are displayed non-intrusively by an electroglottogram. This at first sounds a little alarming as it requires two electrodes to be placed on the boy’s neck. It is however entirely non-intrusive and perfectly comfortable (provided the neck strap is properly adjusted). A trace is obtained by passing a harmless high frequency current through the larynx across the vocal folds. Little current flows when the folds are apart and varying degrees of increased current flow in correspondence to the contact status of the folds.
The figure below shows how this appears on an EGG display. Points A represent the beginning of two successive glottal cycles. The near vertical part of the trace represents the rapid “snapping together” of the vocal folds or closing of the glottis. This is largely complete by point B. The gentler downward slope results from the “peeling apart” action as the folds open again, this time more slowly and creating the resultant mucosal wave beginning in the lower portion of the folds. Point C is considered significant. It is where a distinct “knee” can be seen. This generally only appears at lower frequencies in M1 phonation. M2 phonation in an adult male voice will have a more sinusoidal shape with opening and closing slopes of similar steepness.
The higher pitched voices of boys also show a sinusoidal shape because the higher frequency wave peaks are closer together and it is therefore difficult to tell M1 and M2 phonation apart by this means only. It is also necessary to know the closed quotient or CQ, probably the most important piece of information to be derived from the EGG. Point E represents the time at which this analysis system considers the closed phase to be ended, a judgement rather than absolute measure (see below). From there until the next point A, the glottis is fully open. Breath is flowing and no audio pulse is created. The horizontal green line represents the criterion level (CL). Operator judgment or an algorithm in the system judge its position. Above this line the glottis is closed and below it, open.
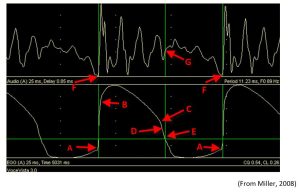
If the audio signal is now examined, it will be seen that the points F coincide with the points A of the glottal cycle. It is important to understand that it is the rapid closure of the air stream that produces the audio pulse which then resonates throughout the closed portion until it dies away from point G onwards when the glottis is open.
It will be seen that the display is recording a Closed Quotient, CQ, of 54%. The segments demarcated by the vertical green lines are approximately equal. The CQ is almost certainly the most important piece of voice source information we can obtain from an EGG, and it is very important in the overall scheme of things. Donald Miller (creator of Voce Vista) makes the following key points about its importance:
- A large CQ enables increased glottal resistance, allowing the singer to build higher subglottal pressure, and with it a higher sound pressure level (SPL).
- The vocal tract with the glottis closed is a better resonator than with it open. A larger CQ increases he resonance.
- A larger CQ boosts the higher frequency components of the sound output of the vocal tract in the singers formant region. (Miller, undated).
Several workers, summarised in Barlow and Brereton (op. cit). have shown a relationship between CQ and level of training in young singers. Trained singers maintained a higher CQ against rising pitch than untrained. Their research showed a marked decline of CQ against rising pitch in boys voices that they deemed to be unchanged. They did not, however, identify how they judged the voices to be unchanged. It is possible that their sample included both stage 0 and stage 1 voices in the unchanged category, in which case lower CQ would be expected with the increasing breathiness and decreasing harmonic content of the stage 1 “unchanged” voices.
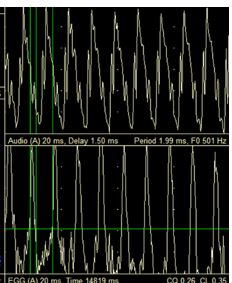
In boys at stage 3 and beyond, low CQ is associated with poor, breathy tone quality and lack of expressive control. The EGG display below is the falsetto speaking voice of a stage 3 boy aged 13:04. It will be seen that the CQ is very low at 26%. The waves appear sinusoidal, but this could be due simply to the frequency. It is the relatively long open phase between each successive wave that confirms this voice as falsetto. If we see a similar pattern in singing, the voice will be falsetto no matter what our ears, deceived by a resonant acoustic, might tell us. However, intensively trained boys at stage 3 have been shown to be able to maintain a higher CQ, which is what makes their voices sound like “head voice” (Morris, 2011). This is a form of hybrid phonation different to the pure M2 voice of of stage 4 boy and as we shall now see an inefficient form of singing that risks a catastrophic “crack” in performance.
Measurement in research: phonational efficiency and catastrophe theory
Boys in middle adolescence who have passed beyond stage 3 can for a period employ the M2 voice to sing a soprano that some might even consider preferable to the “treble” of a child, but few do. For the majority, issues of identity trump any lingering attachment to their old voice. I address the sociology of this in some depth in later chapters. Here I look at the consequences of measuring young voices in research, one of which has been a growing wariness among some scientifically informed singing teachers of the boy who sings treble with a deepening speaking voice.
Jenevora Williams is well known and widely respected for her work on vocal health. The origins of this lie in her PhD thesis which examined the voices of boy choristers at a prestigious London cathedral in probably greater depth than any work previously undertaken. Williams discovered and recognised that some of the older boys were continuing to sing treble at stage 3 (midvoice IIa). Given that midvoice IIa is the time of greatest instability, this came initially as a surprise. Williams did not appear at the time to think that this boy was singing falsetto, though neither could she clearly establish that he was singing in an unchanged modal voice. In 2010 she wrote:
The waveform had more similarities with that of an adult female or an adult trained countertenor. It is suggested that the training these boys received as children enabled them to shift into a hybrid form of phonation, seamlessly bridging the gap between child and adult. This finding had important implications for the training of boys during voice change. When they are actually capable of singing both parts, should they sing soprano or baritone? (Williams, 2010: 292).
Since then, she has tended to answer her own question, writing only a year later that “boys sing too high for too long” (Williams, 2011). The waveform to which she refers is not that of the audio signal but that of the EGG (see above). The first of the two figures below show a chorister aged 10:07 singing the note C5 (523.3Hz) during a test piece (the hymn tune St Botolph). At this time, his voice was unchanged. The second shows the same boy singing the same piece nearly three years later at age 13:07. By this time his voice has changed to midvoice IIa (stage 3), though he is still singing treble in his cathedral choir. The wave form is symmetrical or sinusoidal in both cases, and the peaks are the same distance apart as the frequency is the same. However, the peaks in the older voice are a little lower and the slopes less steep. This is confirmed by the superimposed pink line. The lower peaks there indicate that the folds are opening and closing more slowly.
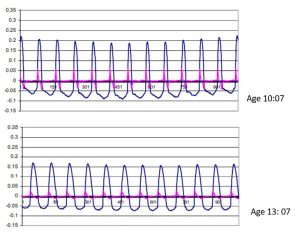
(From Williams 2010: 236)
In a later paper written with two colleagues (Williams, 2020) she revisits this earlier work to demonstrate more explicitly that although experienced choristers can sing treble during stage 3, they do so with demonstrably decreased phonational efficiency. In this paper, she and her colleagues have added catastrophe theory to the analysis and were doubtful of the ability of all cathedral music directors and, perhaps more significantly, singing teachers to make the right judgements. They called for further research into how long it is really appropriate for these boys to maintain a treble, even though they report no “strain or discomfort”. Somewhat in agreement with Janice Chapman’s rejection of English chorister and choral scholar methods, she wrote:
Many choral foundations also employ a singing teacher, in order to guide the boys in the healthiest voice use. However, singing teachers in the UK are not formally trained, licensed or regulated; specific knowledge of children’s voices is generally gained through personal experience rather than formal training. Due to the paucity of formal training in vocal health and singing pedagogy, the level and consistency of training offered to choristers in UK cathedrals is at best, variable. (Williams et al, 2020: 15)
According to catastrophe theory, a boy who is at stage 3 may perform well at rehearsal but then suffer an unfortunate and perhaps humiliating “crack” when under the additional pressure of performance. This is almost certainly what happened to David Hemmings (see Chapter 1) and not long ago it happened to an unfortunate treble during a BBC Radio 3 broadcast of the inevitable Ash Wednesday rendition of the Allegri Miserere.
There is nothing really new in this. George Bragg was careful to stress that:
During this change period the choirboy must be constantly under the surveillance of his choirmaster, mainly for the purpose of seeing that he does not over-use his voice. There are some weeks when the choirboy with the changing voice will be allowed to sing only part of the time. Later, it is possible for him to sing much of the time, and still later, all of the time. It is entirely an individual matter which must be handled with the greatest amount of discretion in order that the choirboy not be made too self-conscious of his momentary flaws (Bragg in Beet, op. cit.)
At our present level of understanding, it would be useful too know
- How some choristers negotiate stage 3 to emerge with a pure sounding and expressive soprano at stage 4
- Why some choristers appear capable of doing this and others do not
- How long the pure sounding soprano of the older boy will last and what event brings about its ending
- The relationship between the purer soprano of some boys and the countertenor timbre of other boys at the same stage of physical development and singing in a similar range.
I cover these and other questions in the next chapter through drawing on a number of my own case studies.
