9 Chapter 9: Bias
Chapter 9: Bias
Objectives
After completing this module, you should be able to:
Define bias and describe its role in epidemiology.
Describe the difference between selection bias and information bias.
Describe types of selection and information bias.
Discuss potential biases in study findings and study proposals.
9.1. Introduction
In epidemiology, when we calculate a measure of association (odds ratio, risk ratio, etc.), we ask whether the observed association is valid or whether it is attributed (at least partially) to chance, bias, or confounding. In epidemiology, bias is defined as the “systematic deviation of an observed measure or an observed association from the truth” (Porta, 2008; Rothman, 2002). Being systematic, bias is any inaccuracy that occurs due to the way in which study participants are selected (known as selection bias) and the way in which measurements are made (known as information bias).
9.2. Types of Bias
9.2.1 Selection Bias
Selection bias is a “distortion [of an observed measure or an observed association from the truth] that results from procedures used to select subjects and from factors that influence participation in a study” (Porta, 2008; Rothman, 2002). Selection bias “occurs when selection probabilities are influenced by exposure or disease status” (Pai, 2019). When selection bias occurs, certain members in the comparison groups may be over-sampled and their proportion may be larger than the proportion in the reference population, making the measure of association (e.g., the odds ratio) in the study samples (i.e., the study results) larger than the actual odds ratio from the reference population (Figure 9.2.1.1).
For example, in a hypothetical case-control study on the association between pancreatic cancer and pre-hospitalization coffee consumption, in a region where coffee consumption is very high (Feinstein et al., 1981), the odds of coffee consumption among cases are not different from the odds of coffee consumption among non-cases in the base population that gave rise to the cases (Figure 9.2.1.2); thus, an unbiased study would show that there was almost no association between pancreatic cancer and coffee consumption. However, the association appeared stronger when the non-cases were selected from outpatients in the gastrointestinal clinic of the same hospital who did not have pancreatic cancer. This distortion in the odds ratio — the odds being higher than the true value — happened because patients with digestive tract problems (the non-cases) are often advised by their doctors not to drink coffee. In addition, the symptoms of the existing gastrointestinal illnesses in the non-cases might have made it difficult for the non-cases to continue to drink coffee, so they became non-coffee drinkers. Hence the odds of coffee drinkers in the non-cases became lower than the odds in the base population — i.e., the denominator became lower than the true value, pushing the odds ratio to be greater than the true value (Figure 9.2.1.2)
Figure 9.2.1.1. Schematic diagrams for unbiased sampling and one possible scenario of selection bias arising from over-sampling of non-exposed non-cases
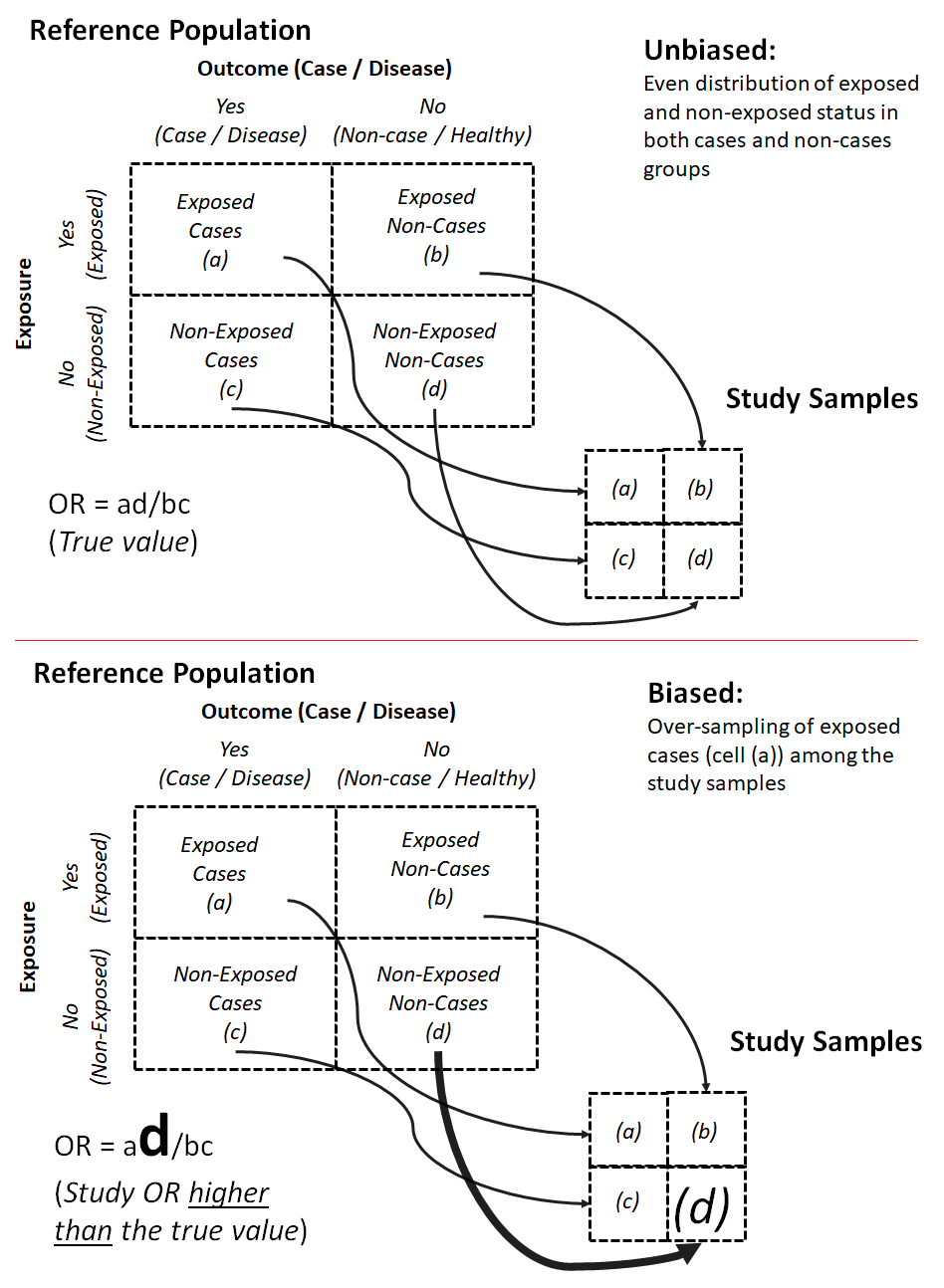
Adapted from Szklo & Nieto, 2019
Figure 9.2.1.2. Examples of unbiased vs. biased sampling when the controls (non-cases) in a case-control study were selected from the base population that gave rise to the cases (unbiased sampling) vs. from hospital patients (biased sampling).
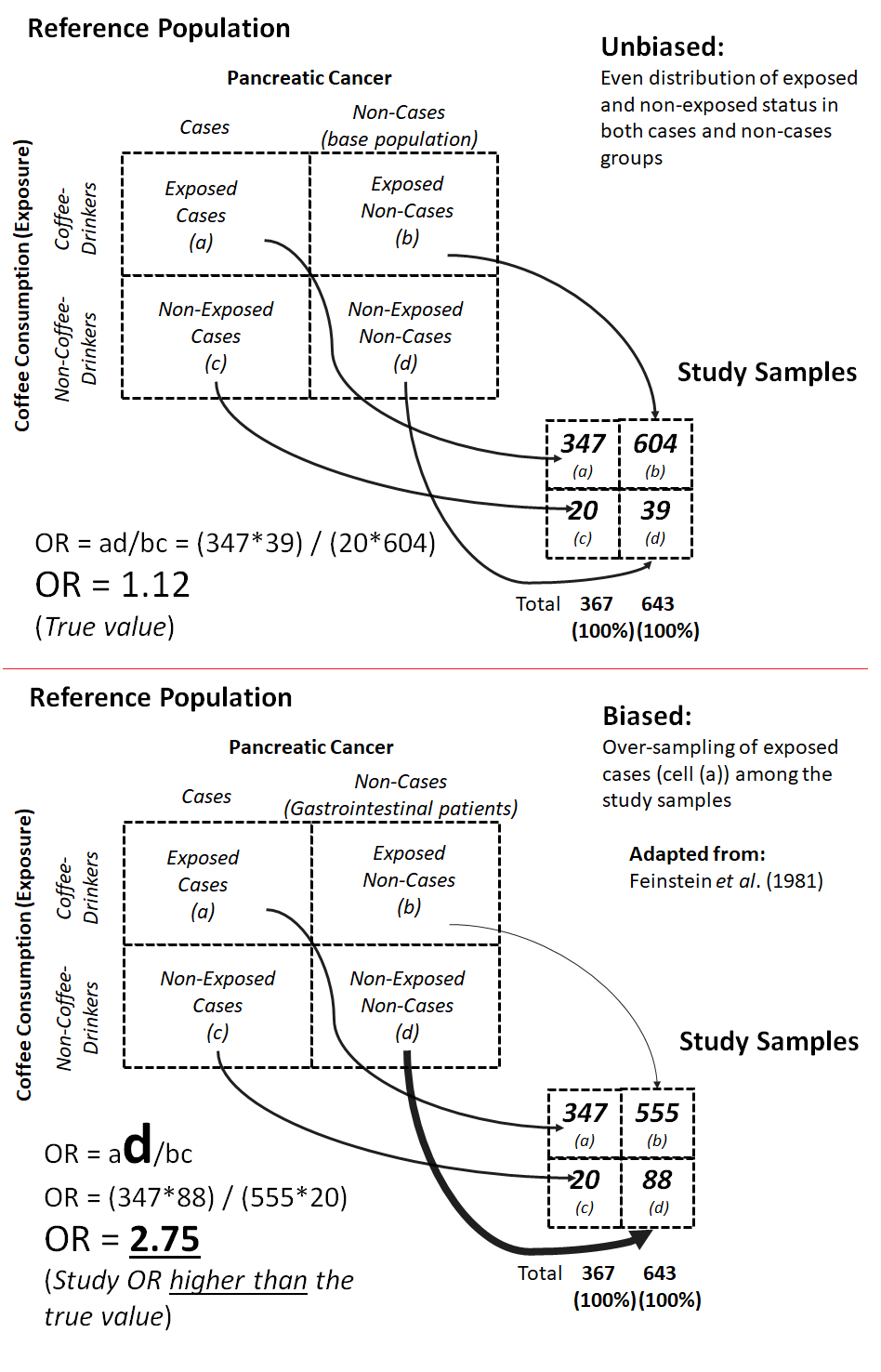
Adapted from Feinstein et al., 1981
9.2.2 Information Bias
We have covered selection bias, which is bias that arises from the way in which participants are selected for the study. Bias can also arise from the way in which we obtain information from participants. If there is a systematic tendency for participants in a study to be misclassified by their exposure or outcome status, information bias may arise.
Recall Bias
A common type of bias due to the misclassification of exposure status is called recall bias. Recall bias is particularly common in case-control studies and arises when the ability to recall or report past exposure is stronger among the cases compared to the control — if the cases have a strong belief that the exposure of interest could be associated with (or could be the cause of) their illness (Figure 9.2.2.1).
For example, in a case-control study on the association between skin cancer and a history of skin tanning after exposure to sunlight, newly diagnosed cases (incident cases) of skin cancer may be more prone to recall that they experienced skin tanning after exposure to sunlight than the control group participants. Participants in the case group may also become more likely to recall a history of tanning when they did not actually tan to a significant extent. The number of unexposed cases could be misclassified as exposed cases, and the odds of exposure among the cases would thus become stronger than it would have been had recall bias not occurred. The varying recall ability among the cases compared to the controls then introduced recall bias into the study findings and biased the odds ratio away from the null value (Figure 9.2.2.2).
Figure 9.2.2.1. Schematic diagrams for where recall bias could occur in a case-control study
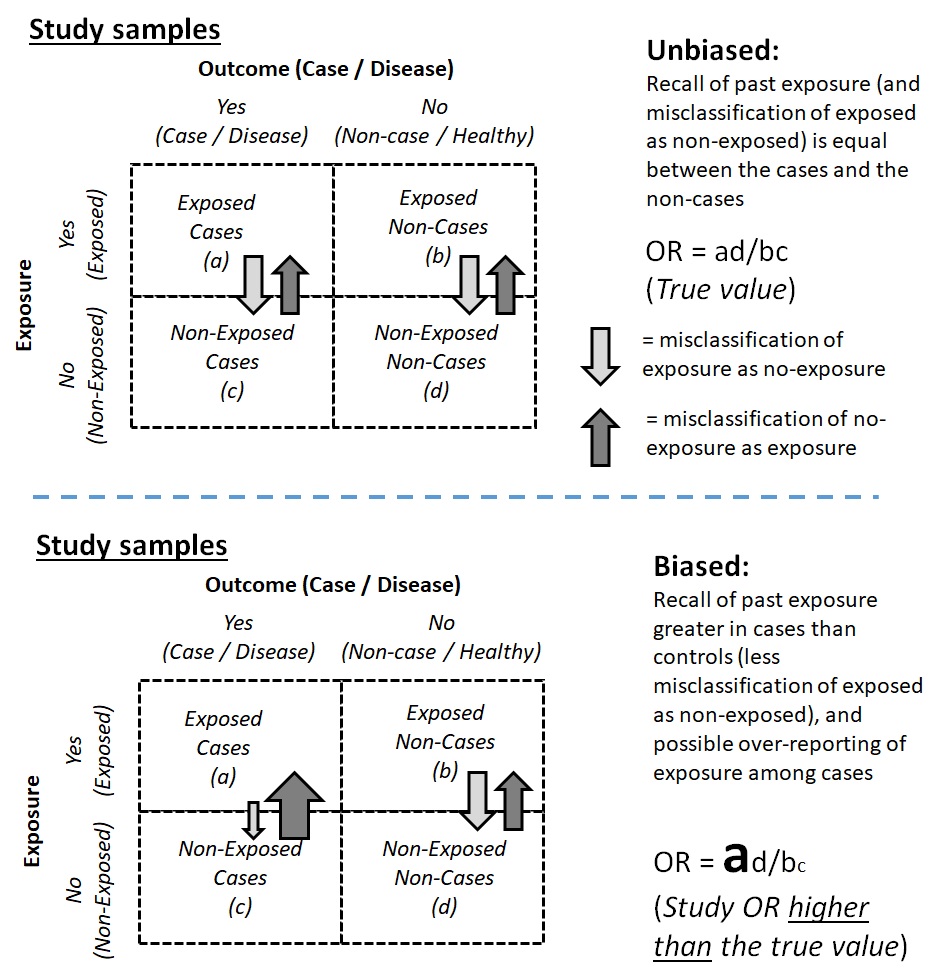
Figure 9.2.2.2. Examples of unbiased vs. biased estimates in a case-control study on the association between skin cancer and tanning ability
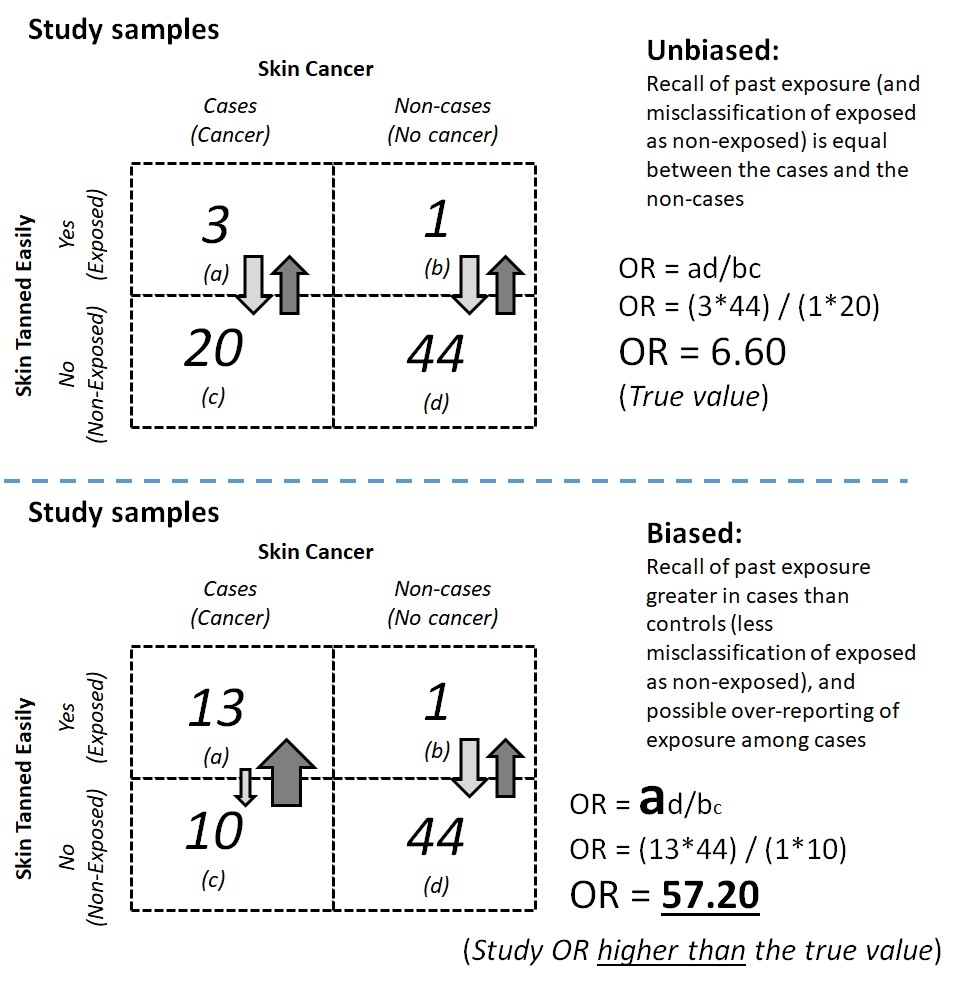
Based on the aforementioned scenarios, how do we overcome recall bias? One possible solution is to verify or triangulate information about the exposure. For example, in a case-control study on skin cancer and the history of tanning after sunlight exposure, investigators can interview friends and family of the cases and verify the information. Investigators can also ask for more information about individuals’ tanning history, such as the intensity and frequency of tanning, in order to measure the exposure in a more complete manner and contextualize the recalled information. Furthermore, the investigators can request access to the participants’ medical history files and look for information regarding treatment for sunburn or other symptoms associated with a history of severe tanning.
Social Desirability Bias
Another common type of information bias is social desirability bias. Social desirability bias is bias from the tendency (or lack thereof) among study participants in each group to give socially desirable answers with regards to the exposure or the outcome. Social desirability bias is common in studies where the nature of the exposure (or outcome) is culturally, morally, or legally sensitive, such as sexual activity and drug use. When social desirability bias occurs, exposed status may be misclassified as non-exposed, or individuals with the outcome may be classified as non-outcome.
For example, the use of heroin or other injectable drugs with shared needles may be associated with HIV infection. In a case-control study on HIV infection, participants were asked about their history of heroin use with shared needles. However, heroin is a Class 1 narcotic, and users may face a prison sentence. The legal risk made heroin use a socially undesirable behavior; thus, instead of telling the truth (Figure 9.2.2.3a), participants who used heroin with shared needles were likely to deny the behavior. If the extent of the under-reporting of drug use (exposure misclassification) was the same among the cases and the control, the misclassification would be non-differential misclassification, which would bias the association toward the null (Figure 9.2.2.3b). If exposure misclassification was different between cases and the controls (for example, the controls were more likely than the cases to deny heroin use), the classification would be differential misclassification, which could bias the association either toward the null or away from the null (Figure 9.2.2.3c).
Figure 9.2.2.3. Examples of possible social desirability bias in a case-control study on drug use and HIV infection with A) unbiased estimates; B) bias from non-differential misclassification; C) bias from differential misclassification
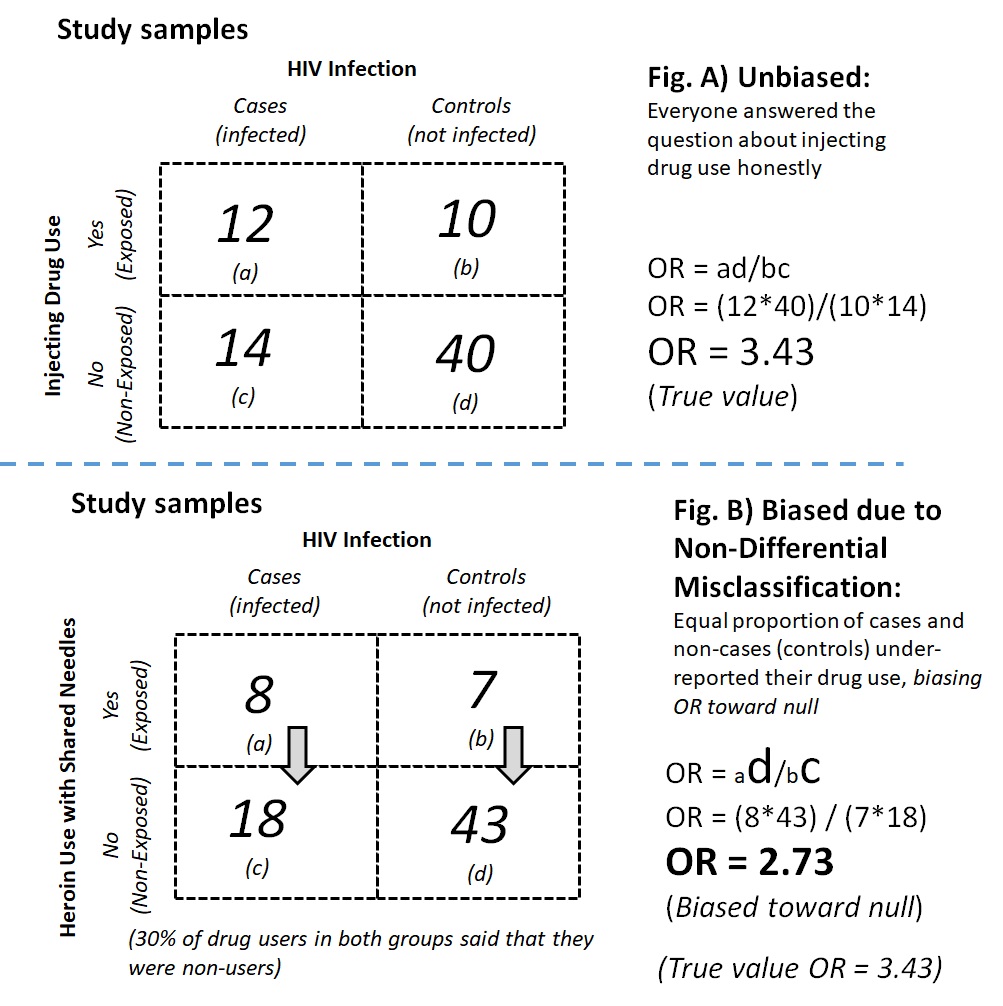

Numbers adapted from a related manuscript (Read et al., 2007).
Other Types of Information Bias
In addition to social desirability bias, epidemiological studies that involve data collection from study participants may face issues with other types of potential information bias. These biases can occur in a study of any design. Study participants may be driven by their own need to maintain or enhance self-esteem. Thus, these participants may provide answers that contain self-serving bias and introduce this type of information bias to the study findings. Furthermore, human beings have the tendency to be more agreeable or deferent to those in positions of higher authority. In such circumstances, we may give affirmative answers or agree with given statements in a way that does not align with our actual feelings. When participants do this and the occurrence of this phenomenon systematically distorts the study findings from the truth, the participants introduce potential acquiescence bias to the study findings.
Lastly, in addition to the participants, the investigators can also become a source of bias. This phenomenon is called observer bias. In a case-control study, if a staff member who interviewed a participant knew whether the participant was a case or a control, and the staff member had preconceived ideas about the potential cause(s) of the outcome, the staff member could probe the patient in the case group for details more thoroughly than the control group participants. This difference could inflate the number of cases with the exposure. In a cohort study or an experimental study, if a staff member knew about a participant’s exposure status and had preconceived notions about the association between the exposure and the outcome, the staff member could examine the exposed group patients more thoroughly than patients in the non-exposed group, thus inflating the incidence of the outcome among the exposed. Observer bias can be reduced by designing and imposing strict protocols during data collection to remove subjective inputs from the process.
9.3 Direction of Bias and its Effect on the Validity of the Study Findings
The direction of bias can have implications on the validity of the study findings. Biases toward the null do not threaten the validity of a study’s overall conclusion. Epidemiologists generally are more concerned when the misclassification is differential — when the bias can be either away from the null or toward the null.
When a measure of association (such as an OR) is biased toward the null, if the association is statistically significant, then the bias did not threaten the validity of the study findings. When the bias is toward the null, it is valid to conclude that there was an association between exposure and outcome because the true measure of association is even stronger than the observed value. In other words, the study findings are conservative. However, when a measure of association is biased away from the null, the measure of association is stronger than the true value. It is difficult to conclude whether an association actually existed (although the strength is weaker than the observed value) or whether the observed association did not exist and was simply the product of bias itself.
To answer the extent to which bias affects our interested measure of association and the conclusion of the findings, we can perform sensitivity analyses and draw a more careful conclusion. The method for sensitivity analysis is beyond the scope of this chapter, and readers are encouraged to consult other sources accordingly.
9.4 Conclusion
In epidemiology, bias is defined as the systematic deviation of an observation (a measure or an association) from the truth. Bias can be introduced to studies through the way in which participants are sampled or otherwise become the study participants (known as selection bias), the way in which investigators collect information, or the way in which participants provide information in the study (known as information bias). When assessing the extent to which bias affects the reported measure of association between an exposure and an outcome, investigators need to consider the mechanism through which the bias might have occurred as well as whether the bias moved the observed measure of association away from the null value or toward the null value. When conducting actual research, the true value is often unknown, but the investigators can apply what they know about how bias occurs and then either remark on the extent to which the findings deviate from the truth or perform sensitivity analyses to attempt to correct the biases.
References
Feinstein, A. R., Horwitz, R. I., Spitzer, W. O., & Battista, R. N. (1981). Coffee and pancreatic cancer. The problems of etiologic science and epidemiologic case-control research. JAMA, 246(9), 957–961. https://doi.org/10.1001/jama.246.9.957
Pai, M. (2019). Selection Bias in Epidemiological Studies. https://www.teachepi.org/wp-content/uploads/OldTE/documents/courses/fundamentals/Pai_Lecture6_Selection%20bias.pdf
Porta, M. (Ed.). (2008). A Dictionary of Epidemiology (5th ed.). Oxford University Press.
Read, T. R. H., Hocking, J., Sinnott, V., & Hellard, M. (2007). Risk factors for incident HIV infection in men having sex with men: A case-control study. Sexual Health, 4(1), 35–39. https://doi.org/10.1071/sh06043
Rothman, K. J. (2002). Epidemiology: An Introduction (1st edition). Oxford University Press.
Szklo, M., & Nieto, F. J. (2019). Epidemiology: Beyond the Basics (4th ed.). Jones & Bartlett Learning.
