7 CHAPTER 7
Evaluating Inductive Arguments and Analogies
As we saw in chapter 1, an inductive argument is an argument whose conclusion is supposed to follow from its premises with a high level of probability, rather than with certainty. This means that although it is possible that the conclusion does not follow from its premises, it is unlikely that this is the case. Since we use inductive arguments frequently in our day to day lives, it is important for us to think carefully about them.
7.1 Inductive Arguments And Statistical Generalizations
|
Watch and Learn |
|
For an introduction to inductive arguments, watch the Critical Thinking Academy’s video, What is an Inductive Argument? |
In chapter 1, we said that inductive arguments are “defeasible,” meaning that we could turn a strong inductive argument into a weak inductive argument simply by adding further premises to the argument. In contrast, deductive arguments that are valid can never be made invalid by adding further premises. Recall our “Tweets” argument:
Tweets is a healthy, normally functioning bird
Most healthy, normally functioning birds fly
Therefore, Tweets probably flies
Without knowing anything else about Tweets, it is a good bet that Tweets flies. However, if we were to add that Tweets is 6 ft. tall and can run 30 mph, then it is no longer a good bet that Tweets can fly (since in this case Tweets is likely an ostrich and therefore cannot fly). The second premise, “most healthy, normally functioning birds fly,” is a statistical generalization. Statistical generalizations are generalizations arrived at by empirical observations of certain regularities. Statistical generalizations can be either universal or partial. Universal generalizations assert that all members (i.e., 100%) of a certain class have a certain feature, whereas partial generalizations assert that most or some percentage of members of a class have a certain feature. For example, the claim that “67.5% of all prisoners released from prison are rearrested within three years” is a partial generalization that is much more precise than simply saying that “most prisoners released from prison are rearrested within three years.” In contrast, the claim that “all prisoners released from prison are rearrested within three years” is a universal generalization. As we can see from these examples, deductive arguments typically use universal statistical generalizations whereas inductive arguments typically use partial statistical generalizations. Since statistical generalizations are often crucial premises in both deductive and inductive arguments, being able to evaluate when a statistical generalization is good or bad is crucial for being able to evaluate arguments. What we are doing in evaluating statistical generalizations is determining whether the premise in our argument is true (or at least well-supported by the evidence). For example, consider the following inductive argument, whose premise is a (partial) statistical generalization:
70% of voters say they will vote for candidate X
Therefore, candidate X will probably win the election
This is an inductive argument because even if the premise is true, the conclusion could still be false (for example, an opponent of candidate X could systematically kill or intimidate those voters who intend to vote for candidate X so that very few of them will actually vote). Furthermore, it is clear that the argument is intended to be inductive because the conclusion contains the word “probably,” which clearly indicates that an inductive, rather than deductive, inference is intended. Remember that in evaluating arguments we want to know about the strength of the inference from the premises to the conclusion, but we also want to know whether the premise is true! We can assess whether or not a statistical generalization is true by considering whether the statistical generalization meets certain conditions. There are two conditions that any statistical generalization must meet in order for the generalization to be deemed “good.”
Adequate sample size: the sample size must be large enough to support the generalization.
Non-biased sample: the sample must not be biased.
A sample is simply a portion of a population. A population is the totality of members of some specified set of objects or events. For example, if I were determining the relative proportion of cars to trucks that drive down my street on a given day, the population would be the total number of cars and trucks that drive down my street on a given day. If I were to sit on my front porch from 12-2 pm and count all the cars and trucks that drove down my street, that would be a sample. A good statistical generalization is one in which the sample is representative of the population. When a sample is representative, the characteristics of the sample match the characteristics of the population at large. For example, my method of sampling cars and trucks that drive down my street would be a good method as long as the proportion of trucks to cars that drove down my street between 12-2 pm matched the proportion of trucks to cars that drove down my street during the whole day. If for some reason the number of trucks that drove down my street from 122 pm was much higher than the average for the whole day, my sample would not be representative of the population I was trying to generalize about (i.e., the total number of cars and trucks that drove down my street in a day). The “adequate sample size” condition and the “non-biased sample” condition are ways of making sure that a sample is representative. In the rest of this section, we will explain each of these conditions in turn.
It is perhaps easiest to illustrate these two conditions by considering what is wrong with statistical generalizations that fail to meet one or more of these conditions. First, consider a case in which the sample size is too small (and thus the adequate sample size condition is not met). If I were to sit in front of my house for only fifteen minutes from 12:00-12:15 and saw only one car, then my sample would consist of only 1 automobile, which happened to be a car. If I were to try to generalize from that sample, then I would have to say that only cars (and no trucks) drive down my street. But the evidence for this universal statistical generalization (i.e., “every automobile that drives down my street is a car”) is extremely poor since I have sampled only a very small portion of the total population (i.e., the total number of automobiles that drive down my street). Taking this sample to be representative would be like going to Flagstaff, AZ for one day and saying that since it rained there on that day, it must rain every day in Flagstaff. Inferring to such a generalization is an informal fallacy called “hasty generalization.” One commits the fallacy of hasty generalization when one infers a statistical generalization (either universal or partial) about a population from too few instances of that population. Hasty generalization fallacies are very common in everyday discourse, as when a person gives just one example of a phenomenon occurring and implicitly treats that one case as sufficient evidence for a generalization. This works especially well when fear or practical interests are involved. For example, Jones and Smith are talking about the relative quality of Fords versus Chevys and Jones tells Smith about his uncle’s Ford, which broke down numerous times within the first year of owning it. Jones then says that Fords are just unreliable and that that is why he would never buy one. The generalization, which is here ambiguous between a universal generalization (i.e., all Fords are unreliable) and a partial generalization (i.e., most/many Fords are unreliable), is not supported by just one case, however convinced Smith might be after hearing the anecdote about Jones’s uncle’s Ford.
The non-biased sample condition may not be met even when the adequate sample size condition is met. For example, suppose that I count all the cars on my street for a three-hour period from 11-2 pm during a weekday. Let us assume that counting for three hours straight give us an adequate sample size. However, suppose that during those hours (lunch hours) there is a much higher proportion of trucks to cars, since (Let us suppose) many work trucks are coming to and from worksites during those lunch hours. If that were the case, then my sample, although large enough, would not be representative because it would be biased. In particular, the number of trucks to cars in the sample would be higher than in the overall population, which would make the sample unrepresentative of the population (and hence biased).
Another good way of illustrating sampling bias is by considering polls. So, consider candidate X who is running for elected office and who strongly supports gun rights and is the candidate of choice of the NRA.
Suppose an organization runs a poll to determine how candidate X is faring against candidate Y, who is actively anti-gun rights. But suppose that the way the organization administers the poll is by polling subscribers to the magazine, Field and Stream. Suppose the poll returned over 5000 responses, which, let us suppose, is an adequate sample size and out of those responses, 89% favored candidate X. If the organization were to take that sample to support the statistical generalization that “most voters are in favor of candidate X” then they would have made a mistake. If you know anything about the magazine Field and Stream, it should be obvious why. Field and Stream is a magazine whose subscribers who would tend to own guns and support gun rights. Thus we would expect that subscribers to that magazine would have a much higher percentage of gun rights activists than would the general population, to which the poll is attempting to generalize. But in this case, the sample would be unrepresentative and biased and thus the poll would be useless. Although the sample would allow us to generalize to the population, “Field and Stream subscribers,” it would not allow us to generalize to the population at large.
Let us consider one more example of a sampling bias. Suppose candidate X were running in a district in which there was a high proportion of elderly voters. Suppose that candidate X favored policies that elderly voters were against. For example, suppose candidate X favors slashing Medicare funding to reduce the budget deficit, whereas candidate Y favored maintaining or increasing support to Medicare. Along comes an organization who is interested in polling voters to determine which candidate is favored in the district. Suppose that the organization chooses to administer the poll via text message and that the results of the poll show that 75% of the voters favor candidate X. Can you see what’s wrong with the poll—why it is biased? You probably recognize that this polling method will not produce a representative sample because elderly voters are much less likely to use cell phones and text messaging and so the poll will leave out the responses of these elderly voters (who, we have assumed make up a large segment of the population). Thus, the sample will be biased and unrepresentative of the target population. As a result, any attempt to generalize to the general population would be extremely ill-advised.
Before ending this section, we should consider one other source of bias, which is a bias in the polling questionnaire itself (what statisticians call the “instrument”). Suppose that a poll is trying to determine how much a population favors organic food products. We can imagine the questionnaire containing a choice like the following:
Which do you prefer?
products that are expensive and have no FDA proven advantage over the less expensive products
products that are inexpensive and have no FDA proven disadvantage over more expensive products
Because of the phrasing of the options, it seems clear that many people will choose option “b.” Although the two options do accurately describe the difference between organic and non-organic products, option “b” sounds much more desirable than option “a.” The phrasing of the options is biased insofar as “a” is a stand-in for “organic” and “b” is stand-in for “non-organic.” Even people who favor organic products may be more inclined to choose option “b” here. Thus, the poll would not be representative because the responses would be skewed by the biased phrasing of the options. Here is another example with the same point:
Which do you favor?
Preserving a citizen’s constitutional right to bear arms
Leaving honest citizens defenseless against armed criminals
Again, because option “b” sounds so bad and “a” sounds more attractive, those responding to a poll with this question might be inclined to choose “a” even if they do not really support gun rights. This is another example of how bias can creep into a statistical generalization through a biased way of asking a question.
Random sampling is a common sampling method that attempts to avoid any kinds of sampling bias by making selection of individuals for the sample a matter of random chance (i.e., anyone in the population is as likely as anyone else to be chosen for the sample). The basic justification behind the method of random sampling is that if the sample is truly random (i.e., anyone in the population is as likely as anyone else to be chosen for the sample), then the sample will be representative. The trick for any random sampling technique is to find a way of selecting individuals for the sample that does not create any kind of bias. A common method used to select individuals for a random sample (for example, by Gallup polls) is to call people on either their landline or cell phones. Since most voting Americans have either a landline or a cell phone, this is a good way of ensuring that every American has an equal chance of being included in the sample. Next, a random number generating computer program selects numbers to dial. In this way, organizations like Gallup are able to get something close to a random sample and are able to represent the whole U.S. population with a sample size as small as 1000 (with a margin of error of +/- 4). As technology and social factors change, random sampling techniques have to be updated. For example, although Gallup used to call only landlines, eventually this method became biased because many people no longer owned landlines, but only cell phones. If some new kind of technology replaces cell phones and landlines, then Gallup will have to adjust the way it obtains a sample in order to reflect the changing social reality.
7.2 Inference To The Best Explanation And The Seven Explanatory Virtues
Explanations help us to understand why something happened and not simply that something happened. However, there is a common kind of inductive argument that takes the best explanation of why x occurred as an argument for the claim that x occurred. For example, suppose that your car window is broken and your iPod (which you left visible in the front seat) is missing. The immediate inference you would probably make is that someone broke the window of your car and stole your iPod. What makes this a reasonable inference? What makes it a reasonable inference is that this explanation explains all the relevant facts (broken window, missing iPod) and does so better than any other competing explanation. In this case, it is perhaps possible that a stray baseball broke your window, but since (let us suppose) there is no baseball diamond close by, and people do not play catch in the parking garage you are parked in, this seems unlikely. Moreover, the baseball scenario does not explain why the iPod is gone. Of course, it could be that some inanimate object broke your window and then someone saw the iPod and took it. Or perhaps a dog jumped into the window that was broken by a stray baseball and ate your iPod. These are all possibilities, but they are remote and thus much less likely explanations of the facts at hand. The much better explanation is that a thief both broke the window and took the iPod. This explanation explains all the relevant facts in a simple way (i.e., it was the thief responsible for both things) and this kind of thing is (unfortunately) not uncommon—it happens to other people at other times and places. The baseball-dog scenario is not as plausible because it does not happen in contexts like this one (i.e., in a parking garage) nearly as often and it is not as simple (i.e., we need to posit two different events that are unconnected to each other—stray baseball, stray dog—rather than just one—the thief). Inference to the best explanation is a form of inductive argument whose premises are a set of observed facts, a hypothesis that explains those observed facts, and a comparison of competing explanations, and whose conclusion is that the hypothesis is true. The example we have just been discussing is an inference to the best explanation. Here is its form:
Observed facts: Your car window is broken and your iPod is gone.
Explanation: The hypothesis that a thief broke the window and stole your iPod provides a reasonable explanation of the observed facts.
Comparison: No other hypothesis provides as reasonable an explanation.
Conclusion: Therefore, a thief broke your car window and stole your iPod.
Notice that this is an inductive argument because the premises could all be true and yet the conclusion false. Just because something is reasonable, does not mean it is true. After all, sometimes things happen in the world that defy our reason. So perhaps the baseball-dog hypothesis was actually true. In that case, the premises of the argument would still be true (after all, the thief hypothesis is still more reasonable than the baseball-dog hypothesis) and yet the conclusion would be false. But the fact that the argument is not a deductive argument is not a defect of the argument, because inference to the best explanation arguments are not intended to be deductive arguments, but inductive arguments. As we saw in chapter 1, inductive arguments can be strong even if the premises do not entail the conclusion. That is not a defect of an inductive argument, it is simply a definition of what an inductive argument is!
As we have seen, in order to make a strong inference to the best explanation, the favored explanation must be the best (or the most reasonable). But what makes an explanation reasonable? There are certain conditions that any good explanation must meet. The more of these conditions are met, the better the explanation. The first, and perhaps most obvious condition, is that the hypothesis proposed must actually explain all the observed facts. For example, if, in order to explain the facts that your car window was broken and your iPod was missing, someone were to say offer the hypothesis that a rock thrown up from a lawnmower broke the window of your car, then this hypothesis would not account for all the facts because it would not explain the disappearance of your iPod. It would lack the explanatory virtue of explaining all the observed facts. The baseball-dog hypothesis would explain all the observed facts, but it would lack certain other explanatory virtues, such as “power” and “simplicity.” In the remainder of this section, I will list the seven explanatory virtues and then I will discuss each one in turn. The seven explanatory virtues are:
Explanatoriness: Explanations must explain all the observed facts.
Depth: Explanations should not raise more questions than they answer.
Power: Explanations should apply in a range of similar contexts, not just the current situation in which the explanation is being offered.
Falsifiability: Explanations should be falsifiable—it must be possible for there to be evidence that would show that the explanation is incorrect.
Modesty: Explanations should not claim any more than is needed to explain the observed facts. Any details in the explanation must relate to explaining one of the observed facts.
Simplicity: Explanations that posit fewer entities or processes are preferable to explanations that posit more entities or processes. All other things being equal, the simplest explanation is the best. This is sometimes referred to as “Ockham’s razor” after William of Ockham (1287-1347), the medieval philosopher and logician.
Conservativeness: Explanations that force us to give up fewer well-established beliefs are better than explanations that force us to give up more well-established beliefs.
Suppose that when confronted with the observed facts of my car window being broken and my iPod missing, my colleague Jeff hypothesizes that my colleague, Paul Jurczak did it. However, given that I am friends with Paul, that Paul could easily buy an iPod if he wanted one, and that I know Paul to be the kind of person who has probably never stolen anything in his life (much less broken a car window), this explanation would raise many more questions than it answers. Why would Paul want to steal my iPod? Why would he break my car window to do so? Etc. This explanation raises as many questions as it answers and thus it lacks the explanatory virtue of “depth.”
Consider now an explanation that lacks the explanatory virtue of “power.” A good example would be the stray baseball scenario, which is supposed to explain, specifically, the breaking of the car window. Although it is possible that a stray baseball broke my car window, that explanation would not apply in a range of similar contexts since people do not play baseball in or around parking garages. So not many windows broken in parking garages can be explained by stray baseballs. In contrast, many windows broken in parking garages can be explained by thieves. Thus, the thief explanation would be a more powerful explanation, whereas the stray baseball explanation would lack the explanatory virtue of power.
Falsifiability can be a confusing concept to grasp. How can anything having to do with being false be a virtue of an explanation? An example will illustrate why the possibility of being false is actually a necessary condition for any good empirical explanation. Consider the following explanation. My socks regularly disappear and then sometime reappear in various places in the house. Suppose I were to explain this fact as follows. There is an invisible sock gnome that lives in our house. He steals my socks and sometimes he brings them back and sometimes he does not. This explanation sounds silly and absurd, but how would you show that it is false? It seems that the hypothesis of the sock gnome is designed such that it cannot be shown to be false—it cannot be falsified. The gnome is invisible, so you can never see it do its thing. Since there is no way to observe it, it seems you can never prove nor disprove the existence of the sock gnome. Thus, you can neither confirm nor disconfirm the hypothesis. But such a hypothesis is a defective hypothesis. Any empirical hypothesis (i.e., a hypothesis that is supposed to explain a set of observed facts) must at least be able to be shown false. The sock gnome hypothesis lacks this virtue—that is, it lacks the explanatory virtue of being falsifiable. In contrast, if I were to hypothesize that our dog, Violet, ate the sock, then this hypothesis is falsifiable. For example, I could perform surgery on Violet and see if I found remnants of a sock. If I did not, then I would have shown that the hypothesis is false. If I did, then I would thereby have confirmed the hypothesis. So the “dog ate the sock” hypothesis is falsifiable, and this is a good thing. The different between a true hypothesis and a false one is simply that the true hypothesis has not yet been shown to be false, whereas the false one has. Falsifiability requires only that it be possible to show that the hypothesis is false. If we look for evidence that would show that the hypothesis is false, but we will not find that evidence, then we have confirmed that hypothesis. In contrast, an unfalsifiable hypothesis cannot be confirmed because we cannot specify any evidence that would show it was false, so we cannot try to look for such evidence (which is what a rigorous scientific methodology requires).
Suppose, to return to my broken window/missing iPod scenario, that my friend Chris hypothesized that a 24 year old Chinese man with a Tweety Bird tattoo on his left shoulder broke the window of my car and stole the iPod. This explanation would lack the explanatory virtue of “modesty.” The problem is that the hypothesis is far more specific than it needs to be in order to explain the relevant observed facts. The details in any explanation should be relevant to explaining the observed facts. However, there is no reason to include the details that the thief was 24 years old, Chinese, and had a Tweety Bird tattoo on his left shoulder. How do those details help us to understand why the observed facts occurred? They do not. It would be just as explanatory to say, simply, that it was a thief rather than to include all those details about the thief, which do not help us to understand or explain any of the observed facts.
The explanatory virtue of “simplicity” tells us that all other things being equal, the simplest explanation is the better explanation. More precisely, an explanation that posits fewer entities or processes in order to explain the observed facts is better than an explanation that posits more entities and processes to explain that same set of observed facts. Here is an example of an explanation that would lack the virtue of simplicity. Suppose that all three of our cars in our driveway were broken into one night and that the next morning the passenger’s side rear windows of each car were broken out. If I were to hypothesize that three separate, unrelated thieves at three different times of the night broke into each of the cars, then this would be an explanation that lacks the virtue of simplicity. The far simpler explanation is that it was one thief (or one related group of thieves) that broke into the three cars at roughly the same time. In the domain of science, upholding simplicity is often a matter of not positing new entities or laws when we can explain the observed facts in terms of existing entities and laws. My earlier example of the sock gnome stealing the socks vs. our dog Violet taking the socks is a good example to illustrate this. Sock gnomes would be a new kind of entity that we do not have any independent reason to think exists, but our dog Violet clearly already exists and since the observed facts can be explained by VioLet usactions rather than that of a sock gnome, the Violet explanation possesses the explanatory virtue of simplicity, whereas the sock gnome explanation lacks the explanatory virtue of simplicity. However, sometimes science requires that we posit new kinds of entities or processes, as when Copernicus and Galileo suggested that the sun, rather than the earth, was at the center of the “solar system” in order to explain certain astronomical observations. In physics new entities are often posited in order to explain the observations that physicists make. For example, the elementary particle dubbed “the Higgs boson” was hypothesized by Peter Higgs (and others) in 1964 and was confirmed in 2012. Much earlier, in 1897, J.J. Thompson and his collaborators, drawing on the work of earlier German physicists, discovered the electron—one of the first elementary particles to be discovered. So there is nothing wrong with positing new laws or entities—that is how science progresses. Simplicity does not say that one should never posit new entities; that would be absurd. Rather, it tells us that if the observed facts can be explained without having to posit new entities, then that explanation is preferable to an explanation that does posit new entities (all other things being equal). Of course, sometimes the observations cannot be explained without having to change the way we understand that world. This is when it is legitimate to posit new entities or scientific laws.
The last explanatory virtue—conservativeness—tells us that better explanations are ones that force us to give up fewer well-established beliefs. Like simplicity, conservativeness is an explanatory virtue only when we are considering two explanations that each explain all the observed facts, but where one conflicts with well-established beliefs and the other does not. In such a case, the former explanation would lack the explanatory virtue of conservativeness, whereas the latter explanation would possess the virtue of conservativeness. Here is an example to illustrate the virtue of conservativeness. Suppose that there are some photographs that vaguely seem to indicate a furry, bipedal humanoid creature that does not look human. My friend Chris offers the following explanation: the creature in those photos is Bigfoot, or Sasquatch. In contrast, I maintain that the creature in the photos is a person in a Bigfoot suit. Given just this evidence (the blurry photos), Chris’s explanation lacks the virtue of conservativeness since his explanation requires the existence of Bigfoot, which is contrary to well-established beliefs that Bigfoot is merely folklore, not a real creature. In contrast, my explanation possesses the virtue of conservativeness since there is nothing about someone dressing up in a costume and being caught on camera (or even someone doing so to play a practical joke or to perpetuate a false belief in a certain population) that conflicts with well-established beliefs. My explanation does not require the existence of Bigfoot, but just the existence of human beings dressed up to look like Bigfoot.
It should be stated that some of the examples I have given could illustrate more than one explanatory virtue. For example, the example of the invisible sock gnome hypothesis could illustrate either lack of falsifiability or lack of simplicity. In identifying which explanatory virtues a particular explanation may lack, what is important is that you give the correct reasoning for why the explanation lacks that particular virtue. For example, if you say that the explanation is not falsifiable, then you need to make sure you give the right explanation of why it is not falsifiable (i.e., that there is no evidence that could ever show that the hypothesis is false). In contrast, if the explanation lacks simplicity, you would have to say that there is another explanation that can equally explain all the observed facts but that posits fewer entities or processes.
7.3 Analogical Arguments
Another kind of common inductive argument is an argument from analogy. In an argument from analogy, we note that since something x shares similar properties to something y, then since y has characteristic A, x probably has characteristic A as well. For example, suppose that I have always owned Subaru cars in the past and that they have always been reliable and I argue that the new car I have just purchased will also be reliable because it is a Subaru. The two things in the analogy are 1) the Subarus I have owned in the past and 2) the current Subaru I have just purchased. The similarity between these two things is just that they are both Subarus. Finally, the conclusion of the argument is that this Subaru will share the characteristic of being reliable with the past Subarus I have owned. Is this argument a strong or weak inductive argument? Partly it depends on how many Subarus I have owned in the past. If I have only owned one, then the inference seems fairly weak (perhaps I was just lucky in that one Subaru I have owned). If I have owned ten Subarus then the inference seems much stronger. Thus, the reference class that I am drawing on (in this case, the number of Subarus I have previously owned) must be large enough to generalize from (otherwise we would be committing the fallacy of “hasty generalization”). However, even if our reference class was large enough, what would make the inference even stronger is knowing not simply that the new car is a Subaru, but also specific things about its origin. For example, if I know that this particular model has the same engine and same transmission as the previous model I owned and that nothing significant has changed in how Subarus are made in the intervening time, then my argument is strengthened. In contrast, if this new Subaru was made after Subaru was bought by some other car company, and if the engine and transmission were actually made by this new car company, then my argument is weakened. It should be obvious why: the fact that the car is still called “Subaru” is not relevant establishing that it will have the same characteristics as the other cars that I have owned that were called “Subarus.” Clearly, what the car is called has no inherent relevance to whether the car is reliable. Rather, what is relevant to whether the car is reliable is the quality of the parts and assembly of the car. Since it is possible that car companies can retain their name and yet drastically alter the quality of the parts and assembly of the car, it is clear that the name of the car is not itself what establishes the quality of the car. Thus, the original argument, which invoked merely that the new car was a Subaru is not as strong as the argument that the car was constructed with the same quality parts and quality assembly as the other cars I’d owned (and that had been reliable for me). What this illustrates is that better arguments from analogy will invoke more relevant similarities between the things being compared in the analogy. This is a key condition for any good argument from analogy: the similar characteristics between the two things cited in the premises must be relevant to the characteristic cited in the conclusion.
Here is an ethical argument that is an argument from analogy. Suppose that Bob uses his life savings to buy an expensive sports car. One day Bob parks his car and takes a walk along a set of train tracks. As he walks, he sees in the distance a small child whose leg has become caught in the train tracks. Much to his alarm, he sees a train coming towards the child. Unfortunately, the train will reach the child before he can (since it is moving very fast) and he knows it will be unable to stop in time and will kill the child. At just that moment, he sees a switch near him that he can throw to change the direction of the tracks and divert the train onto another set of tracks so that it will not hit the child. Unfortunately, Bob sees that he has unwittingly parked his car on that other set of tracks and that if he throws the switch, his expensive car will be destroyed. Realizing this, Bob decides not to throw the switch and the train strikes and kills the child, leaving his car unharmed. What should we say of Bob? Clearly, that was a horrible thing for Bob to do and we would rightly judge him harshly for doing it. In fact, given the situation described, Bob would likely be criminally liable. Now consider the following situation in which you, my reader, likely find yourself (whether you know it or not—well, now you do know it). Each week you spend money on things that you do not need. For example, I sometimes buy $5 espressos from Biggby’s or Starbuck’s. I do not need to have them, and I could get a much cheaper caffeine fix, if I chose to (for example, I could make a strong cup of coffee at my office and put sweetened hazelnut creamer in it). In any case, I really do not need the caffeine at all! And yet I regularly purchase these $5 drinks. (If $5 drinks are not the thing you spend money on, but in no way need, then fill in the example with whatever it is that fits your own life.) With the money that you could save from forgoing these luxuries, you could, quite literally, save a child’s life. Suppose (to use myself as an example) I were to buy two $5 coffees a week (a conservative estimate). That is $10 a week, roughly $43 a month and $520 a year. If donated that amount (just $40/month) to an organization such as the Against Malaria Foundation, I could save a child’s life in just six years. Given these facts, and comparing these two scenarios (Bob’s and your own), the argument from analogy proceeds like this:
Bob chose to have a luxury item for himself rather than to save the life of a child.
“We” regularly choose having luxury items rather than saving the life of a child.
What Bob did was morally wrong.
Therefore, what we are doing is morally wrong as well.
The two things being compared here are Bob’s situation and our own. The argument then proceeds by claiming that since we judge what Bob did to be morally wrong, and since our situation is analogous to Bob’s in relevant respects (i.e., choosing to have luxury items for ourselves rather than saving the lives of dying children), then our actions of purchasing luxury items for ourselves must be morally wrong for the same reason.
One way of arguing against the conclusion of this argument is by trying to argue that there are relevant disanalogies between Bob’s situation and our own. For example, one might claim that in Bob’s situation, there was something much more immediate he could do to save the child’s life right then and there. In contrast, our own situation is not one in which a child that is physically proximate to us is in imminent danger of death, where there is something we can immediately do about it. One might argue that this disanalogy is enough to show that the two situations are not analogous and that, therefore, the conclusion does not follow. Whether or not this response to the argument is adequate, we can see that the way of objecting to an argument from analogy is by trying to show that there are relevant differences between the two things being compared in the analogy. For example, to return to my car example, even if the new car was a Subaru and was made under the same conditions as all of my other Subarus, if I purchased the current Subaru used, whereas all the other Subarus had been purchased new, then that could be a relevant difference that would weaken the conclusion that this Subaru will be reliable.
So, we have seen that an argument from analogy is strong only if the following two conditions are met:
The characteristics of the two things being compared must be similar in relevant respects to the characteristic cited in the conclusion.
There must not be any relevant disanalogies between the two things being compared.
Arguments from analogy that meet these two conditions will tend to be stronger inductive arguments.
7.4 Causal Reasoning
|
Watch and Learn |
|
To learn more about using analogies in arguments, watch two videos produced by the Center for Innovation in Legal Education: |
When I strike a match, it will produce a flame. It is natural to take the striking of the match as the cause that produces the effect of a flame. But what if the matchbook is wet? Or what if I happen to be in a vacuum in which there is no oxygen (such as in outer space)? If either of those things is the case, then the striking of the match will not produce a flame. So it is not simply the striking of the match that produces the flame, but a combination of the striking of the match together with a number of other conditions that must be in place in order for the striking of the match to create a flame. Which of those conditions we call the “cause” depends in part on the context? Suppose that I am in outer space striking a match (suppose I am wearing a space suit that supplies me with oxygen but that I am striking the match in space, where there is no oxygen). I continuously strike it, but no flame appears (of course). But then someone (also in a space suit) brings out a can of compressed oxygen that they spray on the match while I strike it. All of a sudden, a flame is produced. In this context, it looks like it is the spraying of oxygen that causes flame, not the striking of the match. Just as in the case of the striking of the match, any cause is more complex than just a simple event that produces some other event. Rather, there are always multiple conditions that must be in place for any cause to occur. These conditions are called background conditions. That said, we often take for granted the background conditions in normal contexts and just refer to one particular event as the cause. Thus, we call the striking of the match the cause of the flame. We do not go on to specify all the other conditions that conspired to create the flame (such as the presence of oxygen and the absence of water). But this is more for convenience than correctness. For just about any cause, there are a number of conditions that must be in place in order for the effect to occur. These are called necessary conditions (recall the discussion of necessary and sufficient conditions from chapter 2, section 2.7). For example, a necessary condition of the match lighting is that there is oxygen present. A necessary condition of a car running is that there is gas in the tank. We can use necessary conditions to diagnose what has gone wrong in cases of malfunction. That is, we can consider each condition in turn in order to determine what caused the malfunction. For example, if the match does not light, we can check to see whether the matches are wet. If we find that the matches are wet then we can explain the lack of the flame by saying something like, “dropping the matches in the water caused the matches not to light.” In contrast, a sufficient condition is one which if present will always bring about the effect. For example, a person being fed through an operating woodchipper is sufficient for causing that person’s death (as was the fate of Steve Buscemi’s character in the movie Fargo).
Because the natural world functions in accordance with natural laws (such as the laws of physics), causes can be generalized. For example, any object near the surface of the earth will fall towards the earth at 9.8 m/s unless impeded by some contrary force (such as the propulsion of a rocket). This generalization applies to apples, rocks, people, woodchippers and every other object. Such causal generalizations are often parts of explanations. For example, we can explain why the airplane crashed to the ground by citing the causal generalization that all unsupported objects fall to the ground and by noting that the airplane had lost any method of propelling itself because the engines had died. So, we invoke the causal generalization in explaining why the airplane crashed. Causal generalizations have a particular form:
For any x, if x has the feature(s) F, then x has the feature G
For example:
For any human, if that human has been fed through an operating woodchipper, then that human is dead.
For any engine, if that engine has no fuel, then that engine will not operate.
For any object near the surface of the earth, if that object is unsupported and not impeded by some contrary force, then that object will fall towards the earth at 9.8 m/s.
Being able to determine when causal generalizations are true is an important part of becoming a critical thinker. Since in both scientific and everyday contexts we rely on causal generalizations in explaining and understanding our world, the ability to assess when a causal generalization is true is an important skill. For example, suppose that we are trying to figure out what causes our dog, Charlie, to have seizures. To simplify, Let us suppose that we have a set of potential candidates for what causes his seizures. It could be either:
eating human food,
the shampoo we use to wash him,
his flea treatment,
not eating at regular intervals,
or some combination of these things. Suppose we keep a log of when these things occur each day and when his seizures (S) occur. In the table below, I will represent the absence of the feature by a negation. So in the table below, “~A” represents that Charlie did not eat human food on that day; “~B” represents that he did not get a bath and shampoo that day; “~S” represents that he did not have a seizure that day. In contrast, “B” represents that he did have a bath and shampoo, whereas “C” represents that he was given a flea treatment that day. Here is how the log looks:
|
Day 1 |
~A |
B |
C |
D |
S |
|
Day 2 |
A |
~B |
C |
D |
~S |
|
Day 3 |
A |
B |
~C |
D |
~S |
|
Day 4 |
A |
B |
C |
~D |
S |
|
Day 5 |
A |
B |
~C |
D |
~S |
|
Day 6 |
A |
~B |
C |
D |
~S |
How can we use this information to determine what might be causing Charlie to have seizures? The first thing we would want to know is what feature is present every time he has a seizure. This would be a necessary (but not sufficient) condition. And that can tell us something important about the cause. The necessary condition test says that any candidate feature (here A, B, C, or D) that is absent when the target feature (S) is present is eliminated as a possible necessary condition of S. In the table above, A is absent when S is present, so A cannot be a necessary condition (i.e., day 1). D is also absent when S is present (day 4) so D cannot be a necessary condition either. In contrast, B is never absent when S is present—that is every time S is present, B is also present. That means B is a necessary condition, based on the data that we have gathered so far. The same applies to C since it is never absent when S is present. Notice that there are times when both B and C are absent, but on those days the target feature (S) is absent as well, so it does not matter.
The next thing we would want to know is which feature is such that every time it is present, Charlie has a seizure. The test that is relevant to determining this is called the sufficient condition test. The sufficient condition test says that any candidate that is present when the target feature (S) is absent is eliminated as a possible sufficient condition of S. In the table above, we can see that no one candidate feature is a sufficient condition for causing the seizures since for each candidate (A, B, C, D) there is a case (i.e. day) where it is present but that no seizure occurred. Although no one feature is sufficient for causing the seizures (according to the data we have gathered so far), it is still possible that certain features are jointly sufficient. Two candidate features are jointly sufficient for a target feature if and only if there is no case in which both candidates are present and yet the target is absent. Applying this test, we can see that B and C are jointly sufficient for the target feature since any time both are present, the target feature is always present. Thus, from the data we have gathered so far, we can say that the likely cause of Charlie’s seizures is giving him a bath that is followed up with a flea treatment. Every time those two things occur, he has a seizure (sufficient condition); and every time he has a seizure, those two things occur (necessary condition). Thus, the data gathered so far supports the following causal conditional:
Any time Charlie is given a shampoo bath and a flea treatment, he has a seizure.
Although in the above case, the necessary and sufficient conditions were the same, this need not always be the case. Sometimes sufficient conditions are not necessary conditions. For example, being fed through a woodchipper is a sufficient condition for death, but it certainly is not necessary! (Many people die without being fed through a woodchipper, so it cannot be a necessary condition of dying.) In any case, determining necessary and sufficient conditions is a key part of determining a cause.
When analyzing data to find a cause it is important that we rigorously test each candidate. Here is an example to illustrate rigorous testing. Suppose that on every day we collected data about Charlie he ate human food but that on none of the days was he given a bath and shampoo, as the table below indicates.
|
Day 1 |
A |
~B |
C |
D |
~S |
|
Day 2 |
A |
~B |
C |
D |
~S |
|
Day 3 |
A |
~B |
~C |
D |
~S |
|
Day 4 |
A |
~B |
C |
~D |
S |
|
Day 5 |
A |
~B |
~C |
D |
~S |
|
Day 6 |
A |
~B |
C |
D |
S |
Given this data, A trivially passes the necessary condition test since it is always present (thus, there can never be a case where A is absent when S is present). However, in order to rigorously test A as a necessary condition, we have to look for cases in which A is not present and then see if our target condition S is present. We have rigorously tested A as a necessary condition only if we have collected data in which A was not present. Otherwise, we do not really know whether A is a necessary condition. Similarly, B trivially passes the sufficient condition test since it is never present (thus, there can never be a case where B is present, but S is absent). However, in order to rigorously test B as a sufficient condition, we have to look for cases in which B is present and then see if our target condition S is absent. We have rigorously tested B as a sufficient condition only if we have collected data in which B is present. Otherwise, we do not really know whether B is a sufficient condition or not.
In rigorous testing, we are actively looking for (or trying to create) situations in which a candidate feature fails one of the tests. That is why when rigorously testing a candidate for the necessary condition test, we must seek out cases in which the candidate is not present, whereas when rigorously testing a candidate for the sufficient condition test, we must seek out cases in which the candidate is present. In the example above, A is not rigorously tested as a necessary condition and B is not rigorously tested as a sufficient condition. If we are interested in finding a cause, we should always rigorously test each candidate. This means that we should always have a mix of different situations where the candidates and targets are sometimes present and sometimes absent.
The necessary and sufficient conditions tests can be applied when features of the environment are wholly present or wholly absent. However, in situations where features of the environment are always present in some degree, these tests will not work (since there will never be cases where the features are absent and so rigorous testing cannot be applied). For example, suppose we are trying to figure out whether CO2 is a contributing cause to higher global temperatures. In this case, we cannot very well look for cases in which CO2 is present but high global temperatures are not (sufficient condition test) since CO2 and high temperatures are always present to some degree. Nor can we look for cases in which CO2 is absent when high global temperatures are present (necessary condition test), since, again, CO2 and high global temperatures are always present to some degree. Rather, we must use a different method, the method that J.S. Mill called the method of concomitant variation. In concomitant variation we look for how things vary vis-à-vis each other. For example, if we see that as CO2 levels rise, global temperatures also rise, then this is evidence that CO2 and higher temperatures are positively correlated. When two things are positively correlated, as one increases, the other also increases at a similar rate (or as one decreases, the other decreases at a similar rate). In contrast, when two things are negatively correlated, as one increases, the other decreases at similar rate (or vice versa). For example, if as a police department increased the number of police officers on the street, the number of crimes reported decreases, then number of police on the street and number of crimes reported would be negative correlated. In each of these examples, we may think we can directly infer the cause from the correlation—the rising CO2 levels are causing the rising global temperatures and the increasing number of police on the street is causing the crime rate to drop. However, we cannot directly infer causation from correlation. Correlation is not causation. If A and B are positively correlated, then there are four distinct possibilities regarding what the cause is:
A is the cause of B
B is the cause of A
Some third thing, C, is the cause of both A and B increasing
The correlation is accidental
In order to infer what causes what in a correlation, we must rely on our general background knowledge (i.e., things we know to be true about the world), our scientific knowledge, and possibly further scientific testing. For example, in the global warming case, there is no scientific theory that explains how rising global temperatures could cause rising levels of CO2 but there is a scientific theory that enables us to understand how rising levels of CO2 could increase average global temperatures. This knowledge makes it plausible to infer that the rising CO2 levels are causing the rising average global temperatures. In the police/crime case, drawing on our background knowledge we can easily come up with an inference to the best explanation argument for why increased police presence on the streets would lower the crime rate—the more police on the street, the harder it is for criminals to get away with crimes because there are fewer places where those crimes could take place without the criminal being caught. Since criminals do not want to risk getting caught when they commit a crime, seeing more police around will make them less likely to commit a crime. In contrast, there is no good explanation for why decreased crime would cause there to be more police on the street. In fact, it would seem to be just the opposite: if the crime rate is low, the city should cut back, or at least remain stable, on the number of police officers and put those resources somewhere else. This makes it plausible to infer that it is the increased police officers on the street that is causing the decrease in crime.
Sometimes two things can be correlated without either one causing the other. Rather, some third thing is causing them both. For example, suppose that Bob discovers a correlation between waking up with all his clothes on and waking up with a headache. Bob might try to infer that sleeping with all his clothes on causes headaches, but there is probably a better explanation than that. It is more likely that Bob’s drinking too much the night before caused him to pass out in his bed with all his clothes on, as well as his headache. In this scenario, Bob’s inebriation is the common cause of both his headache and his clothes being on in bed.
Sometimes correlations are merely accidental, meaning that there is no causal relationship between them at all. For example, Tyler Vigen reports that the per capita consumption of cheese in the U.S. correlates with the number of people who die by becoming entangled in their bedsheets:
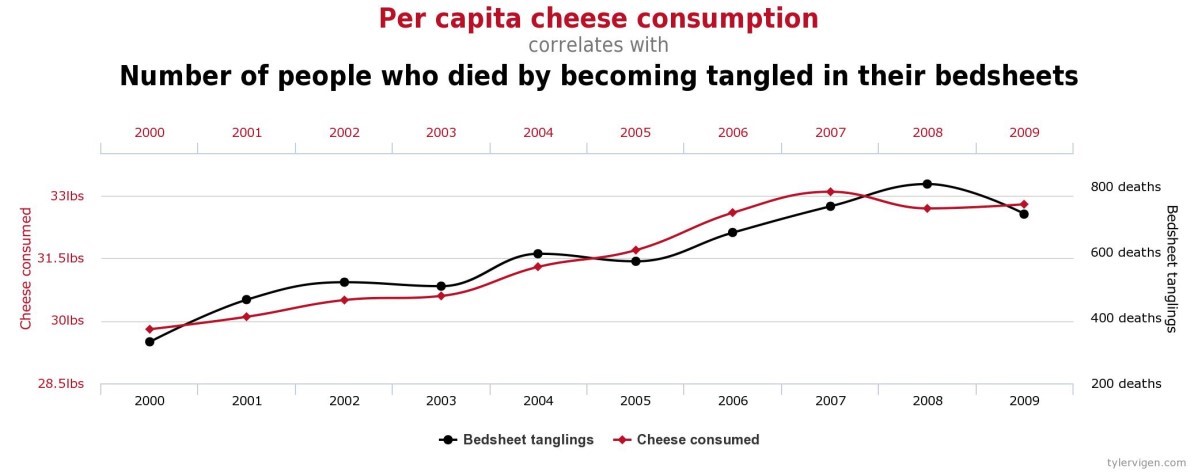
And the number of Mexican lemons imported to the U.S. correlates with the number of traffic fatalities:
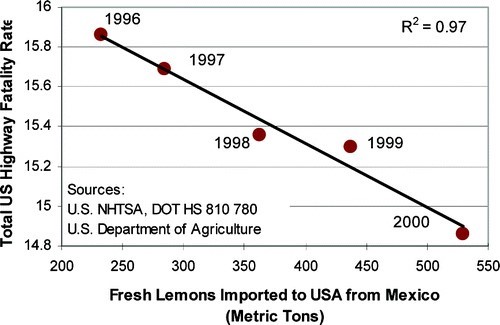
Clearly neither of these correlations are causally related at all—they are accidental correlations. What makes them accidental is that we have no theory that would make sense of how they could be causally related. This just goes to show that it is not simply the correlation that allows us to infer a cause, but, rather, some additional background theory, scientific theory, or other evidence that establishes one thing as causing another. We can explain the relationship between correlation and causation using the concepts of necessary and sufficient conditions (first introduced in chapter 2): correlation is a necessary condition for causation, but it is not a sufficient condition for causation.
Our discussion of causes has shown that we cannot say that just because A precedes B or is correlated with B, that A caused B. To claim that since A precedes or correlates with B, A must therefore be the cause of B is to commit what is called the false cause fallacy. The false cause fallacy is sometimes called the “post hoc” fallacy. “Post hoc” is short for the Latin phrase, “post hoc ergo propter hoc,” which means “before this therefore because of this.” As we have seen, false cause fallacies occur any time someone assumes that two events that are correlated must be in a causal relationship, or that since one event precedes another, it must cause the other. To avoid the false cause fallacy, one must look more carefully into the relationship between A and B to determine whether there is a true cause or just a common cause or accidental correlation. Common causes and accidental correlations are more common than one might think.
7.5 Probability
|
Watch and Learn |
|
To learn more about Probabilities in Reason and Argument, watch the following short videos produced by the Critical Thinking Academy: Critical Thinking About Coincidences (1) Critical Thinking About Coincidences (2) Critical Thinking About Coincidences (3) |
As we have seen, a strong inductive argument is one in which the truth of the premises makes the conclusion highly probable. The distinction between strong inductive arguments and valid (deductive) arguments is that whereas the premises of strong inductive arguments make their conclusions highly probable, the premises of valid arguments make their conclusions certain. We can think of probability as how likely it is that something is (or will be) true, given a particular body of evidence. Using numbers between 0 and 1, we can express probabilities numerically. For example, if I have a full deck of cards and pick one at random, what is the probability that the card I pick is a queen? Since there are 52 cards in the deck, and only four of them are queens, the probability of picking a queen is 4/52, or .077. That is, I have about a 7.7% chance of picking a queen at random. In comparison, my chances of picking any “face” card would be much higher. There are three face cards in each suit and four different suits, which means there are 12 face cards total. So, 12/52 = .23 or 23%. In any case, the important thing here is that probabilities can be expressed numerically. In using a numerical scheme to represent probabilities, we take 0 to represent an impossible event (such as a contradiction) and 1 to represent an event that is certain (such as a tautology).
Probability is important to understand because it provides the basis for formal methods of evaluating inductive arguments. While there is no universally agreed upon method of evaluating inductive arguments in the way there is with deductive arguments, there are some basic laws of probability that it is important to keep in mind. As we will see in the next few sections, although these laws of probability are seemingly simple, we misapply them all the time.
We can think of the rules of probability in terms of some of the truth functional operators, introduced in chapter 2: the probability of conjunctions, the probability of negations, and the probability of disjunctions. The probability of conjunctions is the probability that two, independent events will both occur. For example, what is the probability that you randomly draw a queen and then (after returning it to the pile and reshuffling the deck) you draw another queen? Since we are asking what is the probability that these two events both occur, this is a matter of calculating the probability of a joint occurrence. In the following, “a” and “b” will refer to independent events, and the locution “P(a)” stands for “the probability of a.” Here is how we calculate the probability of conjunctions:
P (a and b) = P(a) × P(b)
So, to apply this to my example of drawing two queens, we have to multiply the probability of drawing one queen, “P(a)” by the probability of drawing yet another queen, “P(b).” Since we have already calculated the probability of drawing a queen at .077, the math is quite simple:
.077 × .077 = .0059
That is, there a less than 1% chance (.59% to be precise) of drawing two queens in this scenario. So, obviously, you would not be wise to place a bet on that happening! Let ustry another example where we have to calculate the probability of a conjunction. Suppose I want to know what the probability that both my father and mother will die of brain cancer. (Macabre, I know.) I’d have to know the probability of dying of brain cancer, which is about 5/100,000. That is, 5 out of every 100,000 people die of brain cancer. That is a very small number: .00005. But the chance of both of them dying of brain cancer is going to be an even smaller number:
.00005 × .00005 = .0000000025
That is almost 1 in a billion chance. So not very likely. Let us consider a final example with more manageable numbers. Suppose I wanted to know the probability of rolling a 12 when rolling two, six-sided dice. Since the only way to roll a 12 is when I roll a 6 on each die, I can compute the probability of rolling a 6 and then the independent probability of rolling another 6 on the other die. The probability of rolling a six on 1 die is just 1/6 = .166. Thus,
.166 × .166 = .028
Thus, you have a 2.8% chance of rolling a 12. We could have also calculated this using fractions instead of decimals:
1/6 × 1/6 = 1/36
Calculating the probability of negations is simply a matter of subtracting the probability that some event, say event a, will occur from 1. The result is the probability that event a will not occur:
P(not-a) = 1 – P(a)
For example, suppose I am playing monopoly I wanted to determine the probability that I do not roll a 12 (since if I roll a 12 I will land on Boardwalk, which my opponent owns with hotels). Since we have already determined that the probability of rolling a 12 is .028, we can calculate the probability of not rolling a 12 thus:
1 – .028 = .972
Thus, I have 97.2% chance of not rolling a 12. So, it is highly likely that I will not.
Here is another example. What are the chances that my daughter does not get into Harvard? Since the acceptance rate at Harvard is about 6% (or .06), I simply subtract that from 1, which yields .94, or 94%. So, my daughter has a 94% chance of not getting into Harvard.
We should pause here to make some comments about probability. The probability of an event occurring is relative to some reference class. So, for example, the probability of getting osteoporosis is much higher if you are a woman over 50 (16%) than if you are a man over 50 (4%). So, if you want accurate data concerning probability, you have to take into account all the relevant factors. In the case of osteoporosis, that means knowing whether you are a woman or a man and are over or under 50. The same kind of point applies to my example of getting into Harvard. Here is an anecdote that will illustrate the point. Some years ago, I agreed to be a part of an interviewing process for candidates for the “presidential scholarship” at the college at which I was teaching at the time. The interviewees were high school students and we could have calculated the probability that any one of them would win the scholarship simply by noting the number of scholarships available and the number of applicants for them. But after having interviewed the candidates I was given to interview, it was very clear to me that one of them easily outshined all the rest. Thus, given the new information I had, it would have been silly for me to assign the same, generic probability to this student winning the award. This student was extremely well-spoken, well-put-together, and answered even my hardest questions (with which other candidates struggled) with an ease and confidence that stunned me. On top of all of that, she was a Hispanic woman, which I knew would only help her in the process (since colleges value diversity in their student population). I recommended her highly for the scholarship, but I also knew that she would end up at a much better institution (and probably with one of their most competitive scholarships). Sometime later, I was wondering where she did end up going to college, so I did a quick search on her name and, sure enough, she was a freshman at Harvard. No surprise to me. The point of the story is that although we could have said that this woman’s chances of not getting into Harvard are about 94%, this would neglect all the other things about her which in fact drastically increase her chances of getting into Harvard (and thus drastically decrease her chances of not getting in).
So, our assessments of probability are only as good as the information we use to assess them. If we were omniscient (i.e., all-knowing), then arguably we could know every detail and would be able to predict with 100% accuracy any event. Since we are not, we have to rely on the best information we do have and use that information to determine the chances that an event will occur.
Calculating the probability of disjunctions is simply a matter of figuring out the probability that either one event or another will occur. To calculate the probability of a disjunction we simply add the probability of the two events together:
P (a or b) = P(a) + P(b)
For example, suppose I wanted to calculate the probability of drawing randomly from a shuffled deck either a spade or a club. Since there are four suits (spades, clubs, diamonds, hearts) each with an equal number of cards, the probability of drawing a spade is ¼ or .25. Likewise the probability of drawing a club is .25. Thus, the probability of drawing either a spade or club is:
.25 + .25 = .50
So, you have a 50% chance of drawing either a spade or a club.
Sometimes events are not independent. For example, suppose you wanted to know the probability of drawing 5 clubs from the deck (which in poker is called a “flush”). This time you are holding on to the cards after you draw them rather than replacing them back into the deck. The probability of drawing the first club is simply 13/52 (or ¼). However, each of the remaining four draws will be affected by the previous draws. If one were to successfully draw all clubs then after the first draw, there would be only 51 cards left, 12 of which were clubs; after the second draw, there would be only 50 cards left, 11 of which were clubs, and so on, like this
13/52 × 12/51 × 11/50 × 10/49 × 9/48 = 33/66,640
As you can see, we have had to determine the probability of a conjunction, since we want card 1 and card 2 and card 3 etc. to all be clubs. That is a conjunction of different events. As you can also see, the probability of drawing such a hand is extremely low—about .0005 or .05%. A flush is indeed a rare hand.
But suppose we wanted to know, not the chances of drawing a flush in a specific suit, but just the chances of drawing a flush in any suit. In that case, we would have to calculate the probability of a disjunction of drawing either a flush in clubs or a flush in spades or a flush in diamonds or a flush in hearts. Recall that in order to calculate a disjunction we must add together the probabilities:
.0005 + .0005 + .0005 + .0005 = .002
So, the probability of drawing a flush in any suit is still only about .2% or one fifth of one percent—i.e., very low.
Let us examine another example before closing this section on probability. Suppose we want to know the chances of flipping at least 1 head in 6 flips of a fair coin. You might reason as follows: There is a 50% chance I flip heads on the first flip, a 50% chance on the second, etc. Since I want to know the chance of flipping at least one head, then perhaps I should simply calculate the probability of the disjunction like this:
.5 + .5 + .5 + .5 + .5 + .5 = 3 (or 300%)
However, this cannot be right, because the probability of any event is between 1 and 0 (including 0 and 1 for events that are impossible and absolutely certain). However, this way of calculating the probability leaves us with an event that is three times more than certain. And nothing is more than 100% certain— 100% certainty is the limit. So, something is wrong with the calculation. Another way of seeing that something must be wrong with the calculation is that it is not impossible that I flip 6 tails in a row (and thus no heads). Since that is a real possibility (however improbable), it cannot be 100% certain that I flip at least one head. Here is the way to think about this problem. What is the probability that I flip all tails? That is simply the probability of the conjunction of 6 events, each of which has the probability of .5 (or 50%):
.5 × .5 × .5 × .5 × .5 × .5 = .015 (or 1.5%)
Then we simply use the rule for calculating the probability of a negation, since we want to know the chances that we do not flip 6 tails in a row (i.e., we flip at least one head):
1 – .015 = .985
So, the probability of flipping at least one head in 6 flips of the coin is 98.5%. (It would be exactly the same probability of flipping at least one tails in 6 flips.)
|
Chapter Review |
|
Review what you have learned in this chapter by watching the Center for Innovation in Legal Education’s video, |