Chapter 4: Speech Sounds in the Mind
Check Yourself
1. Which phonological rule accurately represents the process, “vowels become nasalized before a nasal consonant”?
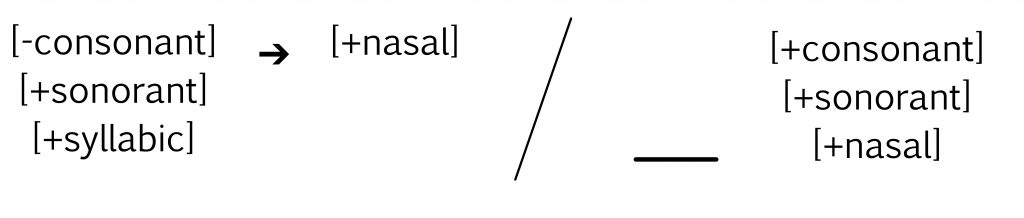
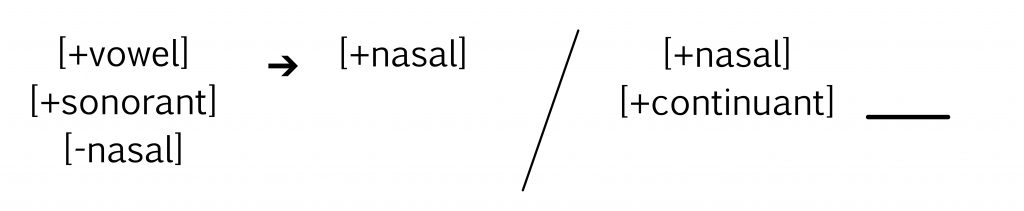
2. Which sentence accurately describes the process depicted in this phonological rule?

- Voiceless fricatives become voiced between voiced sonorants.
- Voiceless stop consonants become voiced before or after a voiced sonorant.
3. Which sentence accurately describes the process depicted in this phonological rule?

- The segment [ə] is deleted in the environment of a strident consonant.
- The segment [ə] is epenthesized following a strident consonant.
Video Script
Earlier in this chapter, we talked about the difference between phonemic and phonetic representations. Remember that when we talk about a phonemic representation, we’re referring to how a sound or a word is represented in our mind. At the phonemic level, the mind stores segmental information, but not details about allophonic variation. But the phonetic representation is how we actually speak words, and because of coarticulation and various articulatory processes, when we speak a given phoneme, it gets produced as the particular allophone that’s conditioned by the surrounding environment. For example, the word clean is represented phonemically like this /klin/ in our minds but when we speak, these particular phonetic details [khl̥in] are part of what we say. We speak in allophones but we hear in phonemes.
The systematic, predictable relationship between the phonemic and phonetic representations is part of the mental grammar of every fluent speaker of a language. Phonologists have developed a notation for depicting this relationship, which is sometimes known as a derivation or a rule. Remember of course that when we talk about rules in linguistics, we don’t mean those prescriptive rules that your high school English teacher wanted you to follow. We mean the principles that our mental grammar uses to link the underlying phonemic representation to the surface form. Our mental grammar keeps track of every predictable phonetic change that happens to a given natural class of sounds in a given phonetic environment.
Let’s think about that now familiar process of liquid devoicing. We’ve seen lots of English examples like clean where the voiced [l] becomes voiceless following the voiceless [kh] because of perseveratory assimilation. In fact, we’ve seen enough data from English to observe that this doesn’t just happen to one segment; it happens to the natural class of liquids in the environment of another natural class: voiceless stops.
The way that we write a derivation takes a particular form that looks like this. This notation is read as “A becomes B in the environment between X and Y”. The left side represents the phonetic change that happens: a particular phoneme or natural class of phonemes becomes a given allophone or undergoes a change to one or more features. The right-hand side shows the phonetic environment that the change occurs in.
So how would we use this notation to represent the predictable process of liquid devoicing? Let’s start by describing the pattern in words. The change happens to the liquids [l] and [ɹ]. What happens to them is that they go from voiced to voiceless. And where it happens is following voiceless stops. So now let’s describe the pattern using a feature matrix.
We start with the feature matrix for the liquids. They’re consonants that are sonorant but not nasal and by default, they’re [+voice]. The change that happens is that their voice feature goes from plus to minus. The other features stay the same so we don’t list them in the feature matrix that describes the change.
Now we have to say where this change happens. The big slash just means “in the environment” and we know that this change happens following something, so we put the horizontal line that indicates the location of the change following the feature matrix that represents the environment and then we fill in the details of the particular environment. Voiceless stops are consonants that are [-continuant] and [-voice].
We could say that [l] becomes voiceless [l] in the environment following [p] or [k] and [ɹ] becomes voiceless [ɹ] in the environment following [p] or [t] or [k] but using feature matrices captures the broader generalization that this allophonic variation happens to an entire natural class in the environment of another natural class.
