3 Chapter 3: Phonetics (The Sounds of Speech)
Learning Outcomes
After studying this chapter, you should be able to discuss:
- the three aspects of speech that make up phonetics
- the International Phonetic Alphabet
- the theories of speech perception
Introduction
Think about how you might describe the pronunciation of the English word cat (cat pictured below). If you had to tell someone what’s the first sound of the word, what would you tell them?
 Saying “The first sound of cat is a ‘k’ sound” will not be sufficient. Why do you think it’s insufficient? (Hint: can you think of other English words that are written with a “k” but don’t have this same sound? Can you think of other English words that have this sound but aren’t written with a “k”?)
Saying “The first sound of cat is a ‘k’ sound” will not be sufficient. Why do you think it’s insufficient? (Hint: can you think of other English words that are written with a “k” but don’t have this same sound? Can you think of other English words that have this sound but aren’t written with a “k”?)
Read this poem out loud:
“Hints on pronunciation for foreigners”
by Anonymous (see note)
I take it you already know
of tough and bough and cough and dough.
Others may stumble, but not you,
On hiccough, thorough, lough* and through.
Well done! And now you wish, perhaps,
To learn of less familiar traps.
Beware of heard, a dreadful word
That looks like beard and sounds like bird.
And dead-it’s said like bed, not bead.
For goodness sake, don’t call it deed!
Watch out for meat and great and threat.
They rhyme with suite and straight and debt.
A moth is not a moth in mother,
Nor both in bother, broth in brother,
And here is not a match for there,
Nor dear and fear for pear and bear.
And then there’s dose and rose and lose
Just look them up–and goose and choose.
And cork and work and card and ward.
And font and front and word and sword.
And do and go, then thwart and cart.
Come, come I’ve hardly made a start.
A dreadful language? Man alive,
I’d mastered it when I was five!
*Laugh has been changed to lough, which is pronounced “lock” and is suggested as the original spelling here.
NOTE: For interesting tidbits about the origins of this poem, see the comments on this blog post.
What does this poem show us about the need for phonetic description?
In addition to variations of pronunciation of the same groupings of letters, the same word, with the same spelling, can have different pronunciations by different people (for example, because of different dialects). The point here is that English spelling does not clearly and consistently represent the sounds of language. In fact, English writing is infamous for that problem.There are lots of subtle differences between pronunciations, and these can’t always be explained with traditional casual ways of explanation. We need a very systematic and formal way to describe how every sound is made. That’s what phonetics is for.
What is Phonetics?
Phonetics looks at human speech from three distinct but interdependent viewpoints:
- Articulatory phonetics (The Production of Speech)…studies how speech sounds are produced.
- Auditory phonetics (The Perception of Speech)…studies the way in which humans perceive sounds.
- Acoustic phonetics (The Physics of Speech)…studies the physical properties of speech sounds.
Articulatory Phonetics
When people play a clarinet or similar instrument, they can make different sounds by closing the tube in different places or different ways. Human speech works the same way: we make sound by blowing air through our tube (from the lungs, up the throat, and out the mouth and/or nose), and we change sounds by changing the way the air flows and/or closing the tube in different places or in different ways.
There are three basic ways we can change a sound, and they correspond to three basic phonetic “features”. (The way I am categorizing features here may be different than what’s presented in some readings; there are lots of different theories about how to organize phonetic features.) They are as follows:
- We can change the way the air comes out of our lungs in the first place, by letting our vocal folds vibrate or not vibrate. This is called voicing. (Voicing is also closely related to aspiration, although they are realized in different ways. The complex relationship between voicing and aspiration is beyond the scope of this subject; for our purposes, you can just treat them as the same thing, and you can use the terms “voiced” and “unaspirated” interchangeably, and use the terms “voiceless” and “aspirated” interchangeably.)
- We can change the way that we close the tube—for example, completely closing the tube will create a one kind of sound, whereas than just narrowing it a little to make the air hiss will create a different kind of sound. This aspect of how we make sound is called manner of articulation.
- We can change the place that we close the tube — for example, putting our two lips together creates a “closure” further up the tube than touching our tongue to the top of our mouth does. This aspect of how we make sound is called place of articulation (“articulation” means movement, and we close our tube by moving something—moving the lips to touch each other, moving the tip of the tongue to touch the top of the mouth, etc.—, so “place of articulation” means “the place that you move to close your mouth).
Articulatory phonetics investigates how speech sounds are produced. This involves some basic understanding of
- The anatomy of speech i.e. the lungs, the larynx and the vocal tract;
- Airstream mechanisms, that is, the mechanisms involved in initiating and producing the types of airstreams used for speech.
Adopting anatomical and physiological criteria, phoneticians define segmental (i.e. the sounds of speech) and suprasegmental (e.g. tonal phenomena).
The Anatomy of Speech
Three central mechanisms are responsible for the production of speech:
- Respiration: The lungs produce the necessary energy in form of a stream of air.
- Phonation: The larynx serves as a modifier to the airstream and is responsible for phonation.
- Articulation: The vocal tract modifies and modulates the airstream by means of several articulators.
Respiration
Before any sound can be produced at all, there has to be some form of energy. In speech, the energy takes the form of a stream of air normally coming from the lungs. Lung air is referred to as pulmonic air.
The respiratory system is used in normal breathing and in speech and is contained within the chest or thorax. Within the thoracic cavity are the lungs, which provide the reservoir for pulmonic airflow in speech.
The lungs are connected to the trachea, by two bronchial tubes which join at the base of the trachea. At the lower end of the thoracic cavity we find the dome-shaped diaphragm which is responsible for thoracic volume changes during respiration. The diaphragm separates the lungs from the abdominal cavity and lower organs.
Phonation
The larynx consists of a number of cartilages which are interconnected by complex joints and move about these joints by means of muscular and ligamental force. The larynx has several functions:
- the protective function
- the respiratory function
- the function in speech
The primary biological function of the larynx is to act as a valve, by closing off air from the lungs or preventing foreign substances from entering the trachea. The principal example of this protective function of the larynx is the glottal closure, during which the laryngeal musculature closes the airway while swallowing.
During respiration, the larynx controls the air-flow from subglottal to supraglottal regions. Normally, humans breathe about 15 times per minute (2 sec. inhaling, 2 sec. exhaling). Breathing for speech has a different pattern than normal breathing. Speaking may require a deeper, more full breath than regular inhalation and such inhalation would be done at different intervals. A speaker’s breathing rate is no longer a regular pattern of fifteen to twenty breaths a minute, but rather is sporadic and irregular, with quick inhalation and a long, drawn out, controlled exhalation (exhaling can last 10 to 15 seconds).In speech production, the larynx modifies the air-flow from the lungs in such a way as to produce an acoustic signal. The result are various types of phonation.
- No voice
- Normal voice
- Whisper
- Breathy
- Creaky
- Falsetto
The most important effect of vocal fold action is the production of audible vibration – a buzzing sound, known as voice or vibration. Each pulse of vibration represents a single opening and closing movement of the vocal folds. The number of cycles per second depends on age and sex. Average male voices vibrate at 120 cycles per second, women’s voices average 220 cycles per second.
Articulation
Once the air passes through the trachea and the glottis, it enters a long tubular structure known as the vocal tract. Here, the airstream is affected by the action of several mobile organs, the active articulators. Active articulators include the lower lip, tongue, and glottis. They are actively involved in the production of speech sounds.
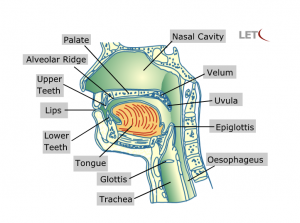
The active articulators are supported by a number of passive articulators, i.e. by specific organs or locations in the vocal tract which are involved in the production of speech sounds but do not move. These passive articulators include the palate, alveola, ridge, upper and lower teeth, nasal cavity, velum, pharynx, epiglottis, and trachea.
The production of speech sounds through these organs is referred to as articulation.
Articulation of Consonants in North American English
Introduction to Articulatory Phonetics licensed CC BY.
Articulation of Vowel Sounds in North American English
Introduction to Articulatory Phonetics licensed CC BY.
International Phonetic Alphabet (IPA)
The International Phonetic Alphabet (IPA) is an alphabetic system of phonetic notation based primarily on the Latin script. It was devised by the International Phonetic Association in the late 19th century as a standardized representation of speech sounds in written form. The IPA is used by lexicographers, foreign language students and teachers, linguists, speech–language pathologists, singers, actors, constructed language creators and translators.
The IPA is designed to represent those qualities of speech that are part of sounds in oral language: phones, phonemes, intonation, and the separation of words and syllables.
IPA symbols are composed of one or more elements of two basic types, letters and diacritics. For example, the sound of the English letter ⟨t⟩ may be transcribed in IPA with a single letter, [t], or with a letter plus diacritics, [t̺ʰ], depending on how precise one wishes to be. Slashes are used to signal phonemic transcription; thus /t/ is more abstract than either [t̺ʰ] or [t] and might refer to either, depending on the context and language.

Introduction to Articulatory Phonetics licensed CC BY.
This website shows the sounds from American English represented with the IPA. In addition, you can type in any English word and get the phonetic conversion!
Exercise
Suprasegmental Features
Vowels and consonants are the basic segments of speech. Together, they form syllables, larger units, and eventually utterances. Superimposed on the segments are a number of additional features known as suprasegmental or prosodic features. They do not characterize a single segment but a succession of segments. The most important suprasegmental features are:
- loudness
- pitch
- length
In a spoken utterance the syllables are never produced with the same intensity. Some syllables are unstressed (weaker), others stressed (stronger).
A stressed syllable is produced by an increase in respiratory activity, i.e. more air is pushed out of the lungs.
Activity 1
The video below suggests that chimpanzees can speak. Is that true? HInt: Think about anatomical reasons that chimpanzees may or may not be able to speak.
Auditory Phonetics
Auditory phonetics investigates the processes underlying human speech perception. The starting point for any auditory analysis of speech is the study of the human hearing system i.e. the anatomy and physiology of the ear and the brain.
Since the hearing system cannot react to all features present in a sound wave, it is essential to determine what we perceive and how we perceive it. This enormously complex field is referred to as speech perception.
This area is not only of interest to phonetics but is also the province of experimental psychology.
The Auditory System
The auditory system consists of three central components:
- The outer ear – modifies the incoming sound signal and amplifies it at the eardrum.
- The middle ear – improves the signal and transfers it to the inner ear.
- The inner ear – converts the signal from mechanical vibrations into nerve impulses and transmits it to the brain via the auditory nerve.
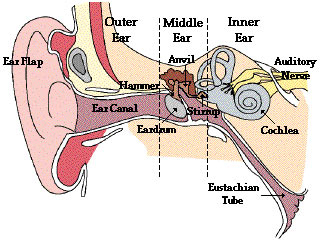
Outer Ear
The outer ear consists of the visible part, known as the auricle or pinna, and of the interior part.
The auricle helps to focus sound waves into the ear, and supports our ability to locate the source of a sound.
From here, the ear canal, a 2.5 cm long tube, leads to the eardrum.The main function of the ear canal is to filter out tiny substances that might approach the eardrum. Furthermore, it amplifies certain sound frequencies(esp.between 3, 000 and 4, 000 Hz) and protects the eardrum from changes in temperature as well as from damage.
Middle Ear
Behind the eardrum lies the middle ear, a cavity which is filled with air via the Eustachian tube (which is linked to the back of the nose and throat).
The primary function of the middle ear is to convert the sound vibrations at the eardrum into mechanical movements. This is achieved by a system of three small bones, known as the auditory ossicles. They are named after their shape:
- the malleus (hammer)
- the incus (anvil)
- the stapes (stirrup)
When the eardrum vibrates due to the varying air pressure caused by the sound waves, it causes the three small bones, the so-called ossicles, to move back and forth. These three bones transmit the vibrations to the membrane-covered oval opening of the inner ear. Together, the ossicles function as a kind of leverage system, amplifying the vibrations by a factor of over 30 dB by the time they reach the inner ear.
Inner Ear
The inner ear contains the vestibular organ with the semi-circular canals, which control our sense of balance, and the cochlea, a coiled cavity about 35 mm long, resembling a snail’s shell. The cochlea is responsible for converting sounds which enter the ear canal, from mechanical vibrations into electrical signals. The mechanical vibrations are transmitted to the oval window of the inner ear via the stapes (stirrup). The conversion process, known as transduction, is performed by specialized sensory cells within the cochlea. The electrical signals, which code the sound’s characteristics, are carried to the brain by the auditory nerve.
The cochlea is divided into three chambers by the basilar membrane. The upper chamber is the scala vestibuli and the bottom chamber is the scala tympani. They are both filled with a clear viscous fluid called perilymph. Between these two chambers is the cochlea duct, which is filled with endolymph.
On the basilar membrane rests the organ of Corti which contains a systematic arrangement of hair cells which pick up the pressure movements along the basilar membrane where different sound frequencies are mapped onto different membrane sites from apex to base.
The hair cells bend in wave-like actions in the fluid and set off nerve impulses which then pass through the auditory nerve to the hearing center of the brain. Short hair cell fibres respond to high frequencies and longer fibres respond to lower frequencies.
Speech Perception
Since the hearing system cannot react to all features present in a sound wave, it is essential to determine what we perceive and how we perceive it. This enormously complex field is referred to as speech perception. Two questions have dominated research:
- Acoustic cues: Does the speech signal contain specific perceptual cues?
- Theories of Speech Perception: How can the process of speech perception be modeled?
A further important issue in speech perception, which is also the province of experimental psychology, is whether it is a continuous or – as often assumed – a categorical process.
Acoustic Cues
The speech signal presents us with far more information than we need in order to recognize what is being said. Yet, our auditory system is able to focus our attention on just the relevant auditory features of the speech signal – features that have come to be known as acoustic cues:
- Voice Onset Time (VOT): the acoustic cue for the voiceless/voiced distinction
- F2-transition : the acoustic cue for place of articulation
- Frequency cues
The importance of these small auditory events has led to the assumption that speech perception is by and large not a continuous process, but rather a phenomenon that can be described as discontinuous or categorical perception.
Voice Onset Time
The voice onset time (VOT) is the point when vocal fold vibration starts relative to the release of a closure, i.e.the interval of voicing prior to a voiced sound. It is crucial for us to discriminate between clusters such as [ pa ] or [ ba ]. It is a well-established fact that a gradual delay of VOT does not lead to a differentiation between voiceless and voiced consonants. Rather, a VOT-value of around 30 msecs serves as the key factor. In other words:
- If VOT is longer than 30 msecs, we hear a voiced sound, such as [ ba ],
- If VOT is shorter than 30 msecs, the perceptual result is [ pa ].
F2 Transition
The formant pattern of vowels in isolation differs enormously from that of vowels embedded in a consonantal context. If a consonant precedes a vowel, e.g. ka/ba/etc, the second formant (F2) seems to emerge from a certain frequency region, the so-called F2-locus. It seems that speech perception is sensitive to the transition of F2 and that F2-transition is an important cue in the perception of speech. In other words, the F2 frequency of the vowel determines whether or not the initial consonant sound is clear.
Frequency Cues
The frequency of certain parts of the sound wave helps to identify a large number of speech sounds. Fricative consonants, such as [s], for example, involve a partial closure of the vocal tract, which produces a turbulence in the air flow and results in a noisy sound without clear formant structure spreading over a broad frequency range. This friction noise is relatively unaffected by the context in which the fricative occurs and may thus serve as a nearly invariant cue for its identification.
However, the value of frequency cues is only relative since the perception of fricatives is also influenced by the fricative’s formant transitions.
Theories of Speech Perception
Speech perception begins with a highly complex, continuously varying, acoustic signal and ends with a representation of the phonological features encoded in that signal. There are two groups of theories that model this process:
- Passive theories: This group views the listener as relatively passive and speech perception as primarily sensory. The message is filtered and mapped directly onto the acoustic-phonetic features of language.
- Active theories: This group views the listener as more active and postulates that speech perception involves some aspects of speech production; the signal is sensed and analysed by reference to how the sounds in the signal are produced.
Passive Theories
Passive theories of speech perception emphasize the sensory side of the perceptual process and relegate the process of speech production to a minor role. They postulate the use of stored neural patterns which may be innate. Two influential passive theories have emerged:
- The Theory of Template Matching
Templates are innate recognition devices that are rudimentary at birth and tuned as language is acquired.
- The Feature Detector Theory
Feature detectors are specialized neural receptors necessary for the generation of auditory patterns.
Active Theories
Active theories assume that the process of speech perception involves some sort of internal speech production, i.e. the listener applies his articulatory knowledge when he analyzes the incoming signal. In other words: the listener acts not only when he produces speech, but also when he receives it.
Two influential active theories have emerged:
- The Motor Theory of Perception
According to the motor theory, reference to your own articulatory knowledge is manifested via direct comparison with articulatory patterns.
- The Analysis-by-Synthesis Theory
The analysis-by-synthesis theory postulates that the reference to your own articulation is via neurally generated auditory patterns.
The McGurk Effect
The McGurk effect is a perceptual phenomenon that demonstrates an interaction between hearing and vision in speech perception. The illusion occurs when the auditory component of one sound is paired with the visual component of another sound, leading to the perception of a third sound. The visual information a person gets from seeing a person speak changes the way they hear the sound. If a person is getting poor quality auditory information but good quality visual information, they may be more likely to experience the McGurk effect.
Activity 2
You are invited to participate in a little experiment on perception. In the video below you see a mouth speaking four items. Your tasks are the following:
- Watch the mouth closely, but concentrate on what you hear.
- Now close your eyes. Play the clip again.
- What did you perceive when you saw and heard the video clip? What did you perceive when you just heard the items?
Acoustic Phonetics
Acoustic phonetics studies the physical properties of the speech signal. This includes the physical characteristics of human speech, such as frequencies, friction noise, etc.
There are numerous factors that complicate the straightforward analysis of the speech signal, for example, background noises, anatomical and physiological differences between speakers etc.
These and other aspects contributing to the overall speech signal are studied under the heading of acoustic phonetics.
Sound Waves
Sound originates from the motion or vibration of a sound source, e.g. from a tuning fork. The result of this vibration is known as a simple sound wave, which can be mathematically modeled as a sine wave. Most sources of sounds produce complex sets of vibrations. They arise from the combination of a number of simple sound waves.
Speech involves the use of complex sound waves because it results from the simultaneous use of many sound sources in the vocal tract.
The vibration of a sound source is normally intensified by the body around it. This intensification is referred to as resonance. Depending on the material and the shape of this body, several resonance frequencies are produced.
Simple sound waves are produced by a simple source, e.g. the vibration of a tuning fork. They are regular in motion and are referred to as periodic. Two properties are central to the measurement of simple sound waves: the frequency and the amplitude.
Practically every sound we hear is not a pure tone but a complex tone; its wave form is not simple but complex. Complex wave forms are synthesized from a sufficient number of simple sound waves. There are two types of complex wave forms:
- periodic complex sound waves
- aperiodic complex sound waves
Speech makes use of both kinds. Vowels, for example, are basically periodic, whereas consonants range from periodic to aperiodic:
- the vowel [ a ], periodic
- the consonant [ n ], periodic
- the consonant [ s ], aperiodic
- the consonant [ t ], aperiodic
Resonance
The sound wave created by a sound source is referred to as the fundamental frequency or F0 (US: “F zero”).
On a musical instrument, F0 is the result of the vibration of a string or a piece of reed. In speech, it is the result of vocal fold vibration.
In both cases, F0 is a complex sound wave which is filtered (intensified and damped) by numerous parts of the resonating body. The resulting bundles of resonance frequencies or harmonics are multiples of F0. They are called formants and are numbered F1, F2 and so on.
In speech, these formants can be associated with certain parts of the vocal tract, on a musical instrument they are multiples of F0. For example, on an oboe F0 is the result of the vibration of the reed. This fundamental frequency is intensified (and damped) by the resonating body. As a result, a number of harmonics or formant frequencies are created as multiples of the frequency of F0.
Attributions:
Content adapted from the following:
VLC102 – Speech Science
by Jürgen Handke, Peter Franke, Linguistic Engineering Team under CC BY 4.0
“International Phonetic Alphabet” licensed under CC BY SA.
“McGurk Effect” licensed under CC BY SA.
Introduction to Linguistics by Stephen Politzer-Ahles. CC-BY-4.0.

{kind=link}