11 Tracking the Source of Viral Content
In the examples we’ve seen so far, it’s been straightforward to find the source of the content. The Blaze story, for example, clearly links to the Daily Dot piece so that anyone reading their summary is one click away from confirming it with the source. The New York Times makes apparent that the syndicated content is from the Associated Press, so checking the credibility of the source is readily available to you.
This is good internet citizenship. Articles on the web that repurpose other information or artifacts should state their sources, and, if appropriate, link to them. This matters to creators, because they deserve credit for their work. But it also matters to readers who need to check the credibility of the original sources.
Unfortunately, many people on the web are not good citizens. This is particularly true with material that spreads quickly as hundreds or thousands of people share it–so-called “viral” content.
When that information travels around a network, people often fail to link it to sources, or hide them altogether. For example, here is an interesting claim that two million bikers are going to show up for President-elect Trump’s inauguration. Whatever your political persuasion, that would be a pretty amazing thing to see.
But the source of the information, Right Alerts Polls, is not linked.
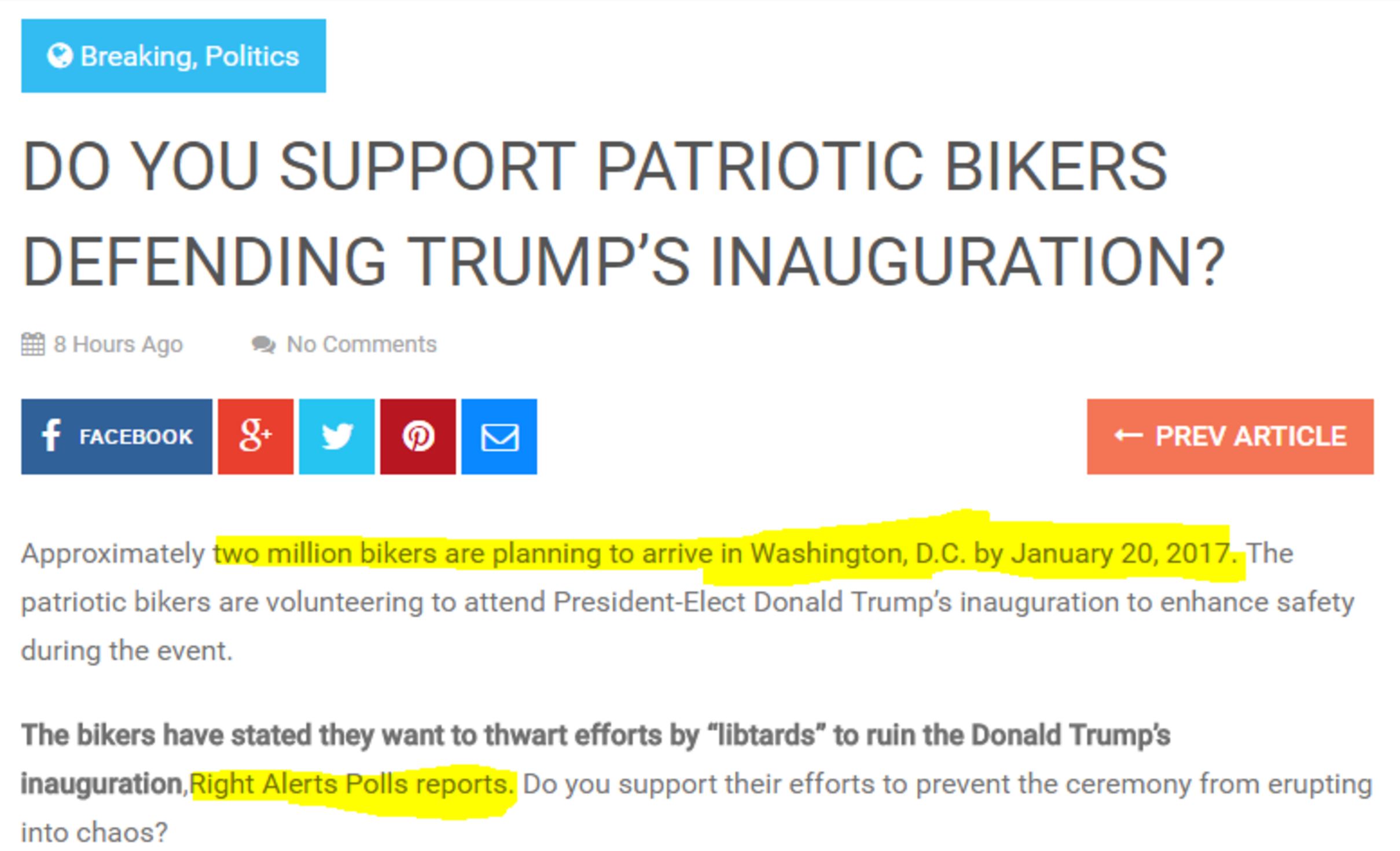
Here’s where we show our first trick. Using the Chrome web browser, select the text “Right Alerts Polls.” Then right-click your mouse (control-click on a Mac), and choose the option to search Google for the highlighted phrase.
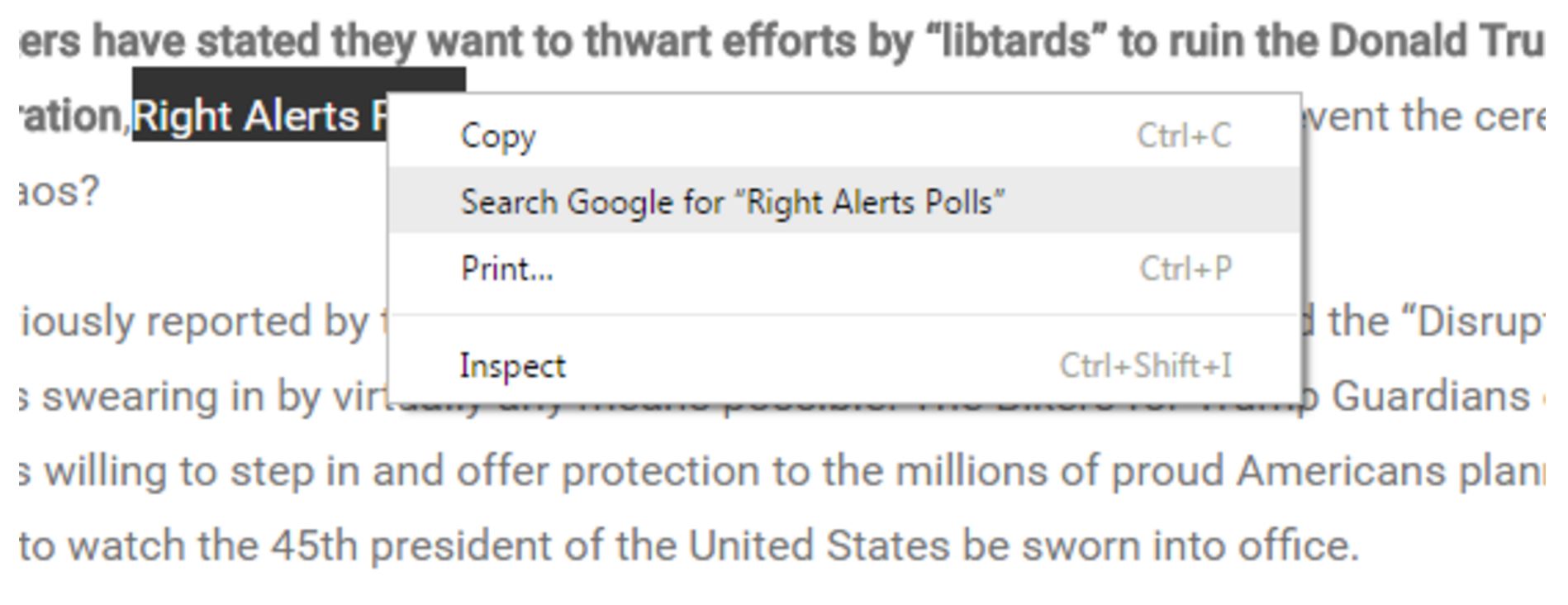
Your computer will execute a search for “Right Alerts Polls.” (Remember this right-click/control-click action–it’s going to be the foundation of a lot of stuff we do.)
To find the story, add “bikers” to the end of the search:
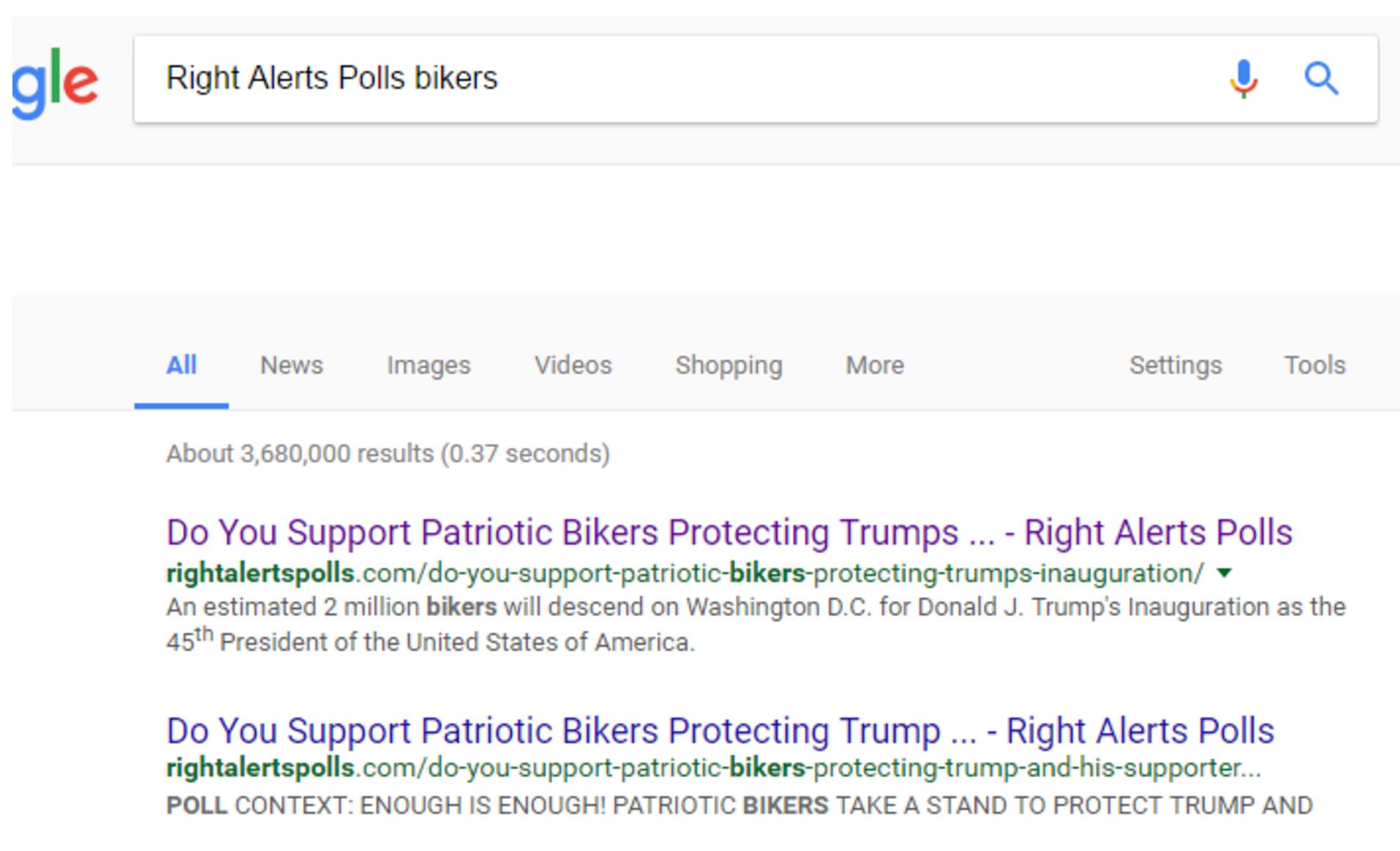
We find our upstream article right at the top. Note that if you do not use Chrome, there are analogues of this method in other browsers as well. Right-clicking in Internet Explorer will allow you to search Bing, for example. If you want, you can always do this the slightly longer way by going to Google and typing in the search terms.
So are we done here? Have we found the source?
Nope. When we click through to the supposed source article, we find that this article doesn’t tell us where the information is coming from either. However, it does have an extended quote from one of the “Two Million Bikers” organizers:
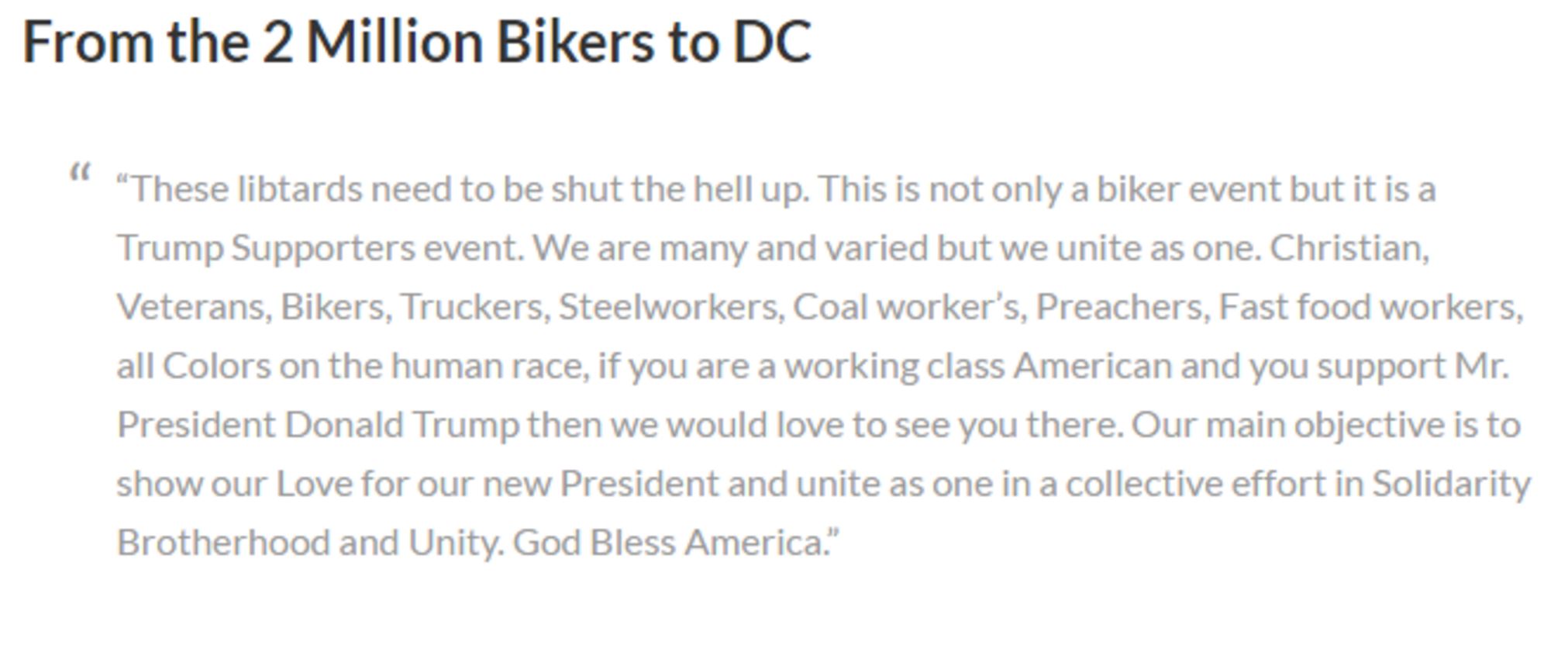
So we just repeat our technique here, and select a bit of text from the quote and right-click/control-click. Our goal is to figure out where this quote came from, and searching on this small but unique piece of it should bring it close to the top of the Google results.
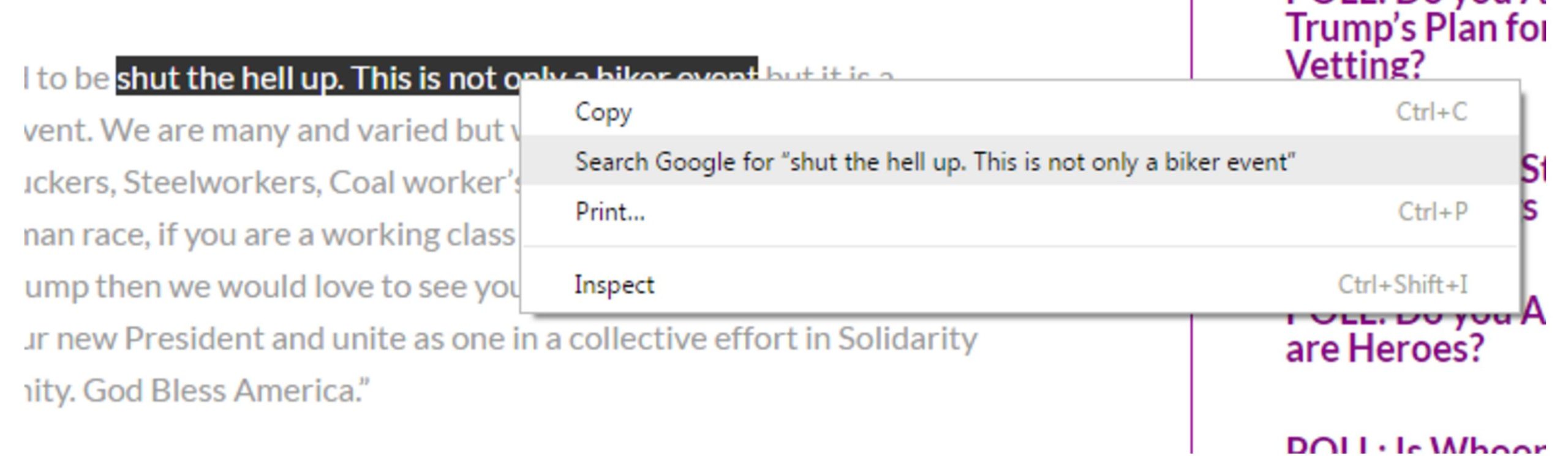
When we search this snippet of the quote, we see that there are dozens of articles covering this story, using the the same quote and sometimes even the same headline. But one of those results is the actual Facebook page for the event, and if we want a sense of how many people are committing, then this is a place to start.
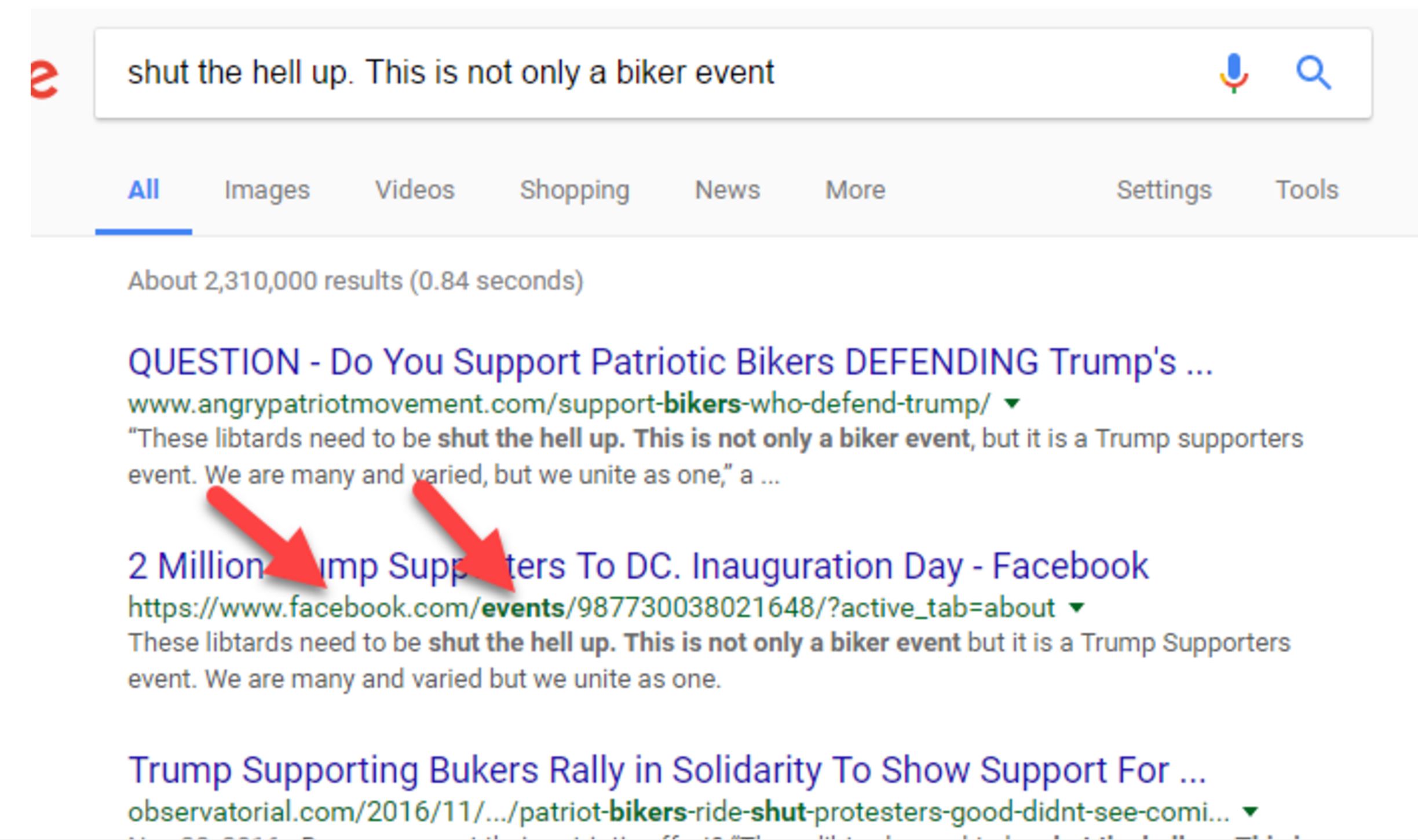
This also introduces us to another helpful practice: when scanning search results, novices scan the titles. Pros scan the URLs beneath the titles, looking for clues as to which sources are best. (Be a pro!)
So we go to the “Two Million Biker” Facebook event page, and take a look. How close are they to getting two million bikers to commit to this?
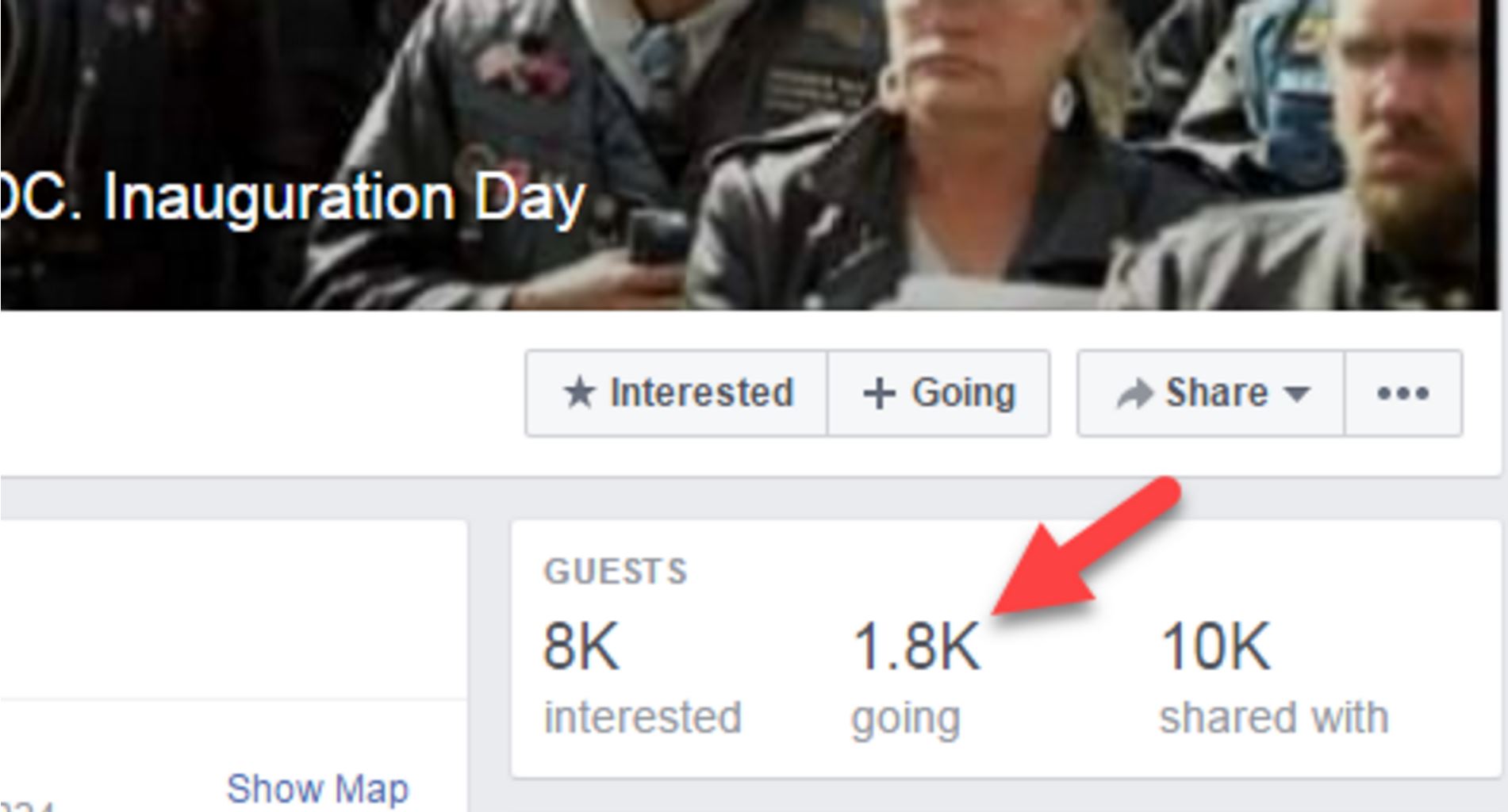
Well…it looks like about 1,800. That’s nothing to sneer at–organizing is hard, and people have lives to attend to. Getting people to give up time for political activity is tough. But it’s pretty short of the “two million bikers” most of these articles were telling us were going to show up.
When we get into how to rate articles on the DigiPo site as true or false, likely or unlikely, we’ll talk a bit about how to write up the evaluation of this claim. Our sense is the rating here is either “Mostly False” or “Unlikely”–there are people planning to go, that’s true, but the importance of the story was based around the scale of attendance, and all indications seem to be that attendance is shaping up to be about a tenth of one percent (0.1%) of what the other articles promised.
Importantly, we would have learned none of this had we decided to evaluate the original page. We learned this by going upstream.
