Conception
La réalisation d’une architecture réseau répond à une organisation, mais également à deux éléments majeurs que sont le besoin de sûreté de fonctionnement et la performance. Par performance, il faut comprendre la capacité à répondre à un besoin immédiat et la capacité à évoluer sans pour autant faire baisser la performance de l’ensemble au fur et à mesure de l’adjonction de nouveaux éléments sur l’infrastructure réseau. Ce dernier point couvre la gestion de la capacité ou « Capacity Planning ».
Depuis très longtemps, les architectures réseaux s’inspirent du modèle appelé « Three-Tier Architecture » ou architecture à trois niveaux. Ce modèle est composé des niveaux : « Core », « Distribution » et « Access ». Les fermes de serveurs ne sont qu’un cas particulier de niveau « Access ». Les niveaux « Distribution » et « Access » forment des « Building Blocks » qui sont concentrés sur le niveau « Core ». L’objectif est de dimensionner des « Building Blocks » qui ne grossiront pas au delà d’un seuil établi à l’avance, et l’augmentation de la taille du réseau passe par l’adjonction de « Building Blocks ». Les dimensionnements des « Building Blocks » et des liaisons entre toutes les couches de l’architecture font appel à la notion appelée « oversubscription ».
Dans le domaine de la planification de la capacité de réseau ou « Capacity Planning », les considérations statistiques jouent un rôle clé. Il est intuitivement évident que, dans le pire des cas, les résultats du provisionnement engendrent du gaspillage et des dépenses inutiles. Il est également intuitivement évident que dans un réseau avec oversubscription il y a un risque de ne pas être en mesure de fournir les services adéquats aux utilisateurs si le ratio utilisé est trop agressif.
Le « Capacity Planning » de réseau est un domaine souvent basée sur des observations empiriques, des tendances, des modèles et des prévisions sur l’utilisation du réseau. Dans un domaine soumis au trafic en rafale, il est difficile de déduire des paramètres précis de dimensionnement des liens et il est fréquent de voir des réseaux conçus pour les pires scénarios d’utilisation. Cependant, c’est précisément la nature en rafale du trafic qui permet d’utiliser une approche statistique dans la planification des capacités. En d’autres termes, nous exploitons le fait que tout le monde n’est pas connecté en même temps pour prendre nos décisions de dimensionnement du réseau.
Comme proposé dans [8], il est possible d’approcher le sujet sous un angle statistique. Supposons un nombre [latex]n[/latex] de sources de trafic de type « on/off » pouvant utiliser les liaisons du réseau. Chaque source génère une rafale de trafic pouvant aller jusqu’à [latex]R[/latex] (bits par seconde) dans un intervalle de temps de [latex]T[/latex] secondes durant sa période « on », puis cette source passe à « off » pendant une autre période de [latex]T[/latex] secondes, et enfin le cycle se répète. Notons que la source envoie [latex]RT[/latex] bits pendant la période « on » et que le nombre de bits par période est aléatoire.
Les différentes sources ne sont pas synchronisées dans le temps (elles peuvent passer à « on » et « off » indépendamment les unes des autres) et leurs trafics agrégés sont traités par les liens du réseau.
Nous pouvons calculer l’oversubscription statistique pour une moitié des sources actives en même temps, à l’aide de la formule suivante : [latex]C=\frac{R}{2}n+C_{\epsilon}S_{max}\sqrt{n}[/latex]
Dans laquelle :
- [latex]C[/latex] est la capacité du lien à prévoir en bits/s, si la moitié des sources sont « on » en même temps.
- [latex]nR[/latex] correspond au trafic maximum en bits/s, si toutes les sources sont « on » en même temps.
- [latex]\frac{R}{2}n[/latex] correspond au trafic moyen en bits/s, de toutes les sources agrégées en partant de l’hypothèse que seulement la moitié sont « on » à la fois.
- [latex]C_{\epsilon}[/latex] correspond au niveau de QoS qui reflète l’intervalle de confiance avec lequel on peut déclarer que la capacité résultante ne sera pas dépassée par la charge de trafic.
- [latex]\epsilon=0,01[/latex] correspond à un intervalle de confiance de [latex]99\%[/latex] soit [latex]1-\epsilon[/latex], qui donne [latex]C_{\epsilon}=2,575829303549[/latex] selon la table de la Loi Normale.
- [latex]S_{max}=\frac{R}{2\sqrt{3}}[/latex] correspond à l’écart type en bits/s pour une source de trafic, sachant que l’écart type correspond à [latex]\sqrt{variance}[/latex].
Prenons un exemple dans lequel [latex]n=100[/latex], [latex]R=1.000.000\,bit/s[/latex], [latex]T=1\,sec[/latex] et [latex]\epsilon=0,01[/latex].
- [latex]C_{max}=nR=100\times1.000.000\,bits/s=100\,Mbits/s[/latex]
- [latex]S_{max}=\frac{R}{2\sqrt{3}}=\frac{1.000.000\,bits/s}{3,46}=289.017\,bits/s[/latex]
- [latex]C_{stat}=\frac{1.000.000\,bits/s}{2}\times100+2,58\times289.017\,bits/s\times10=50\,Mbits/s+7,5\,Mbits/s=57,5\,Mbits/s[/latex]
Dans cet exemple, nous pouvons constater que dans le pire cas de provision, la liaison nécessiterait 100 Mbits/s de capacité, alors qu’un lien d’une capacité d’environ 60 Mbits/s suffirait pour supporter le volume de trafic, avec un niveau de confiance de 99% (c’est à dire que nous sommes convaincus que 99% du temps, le volume total du trafic ne dépassera pas 60 Mbits/s).
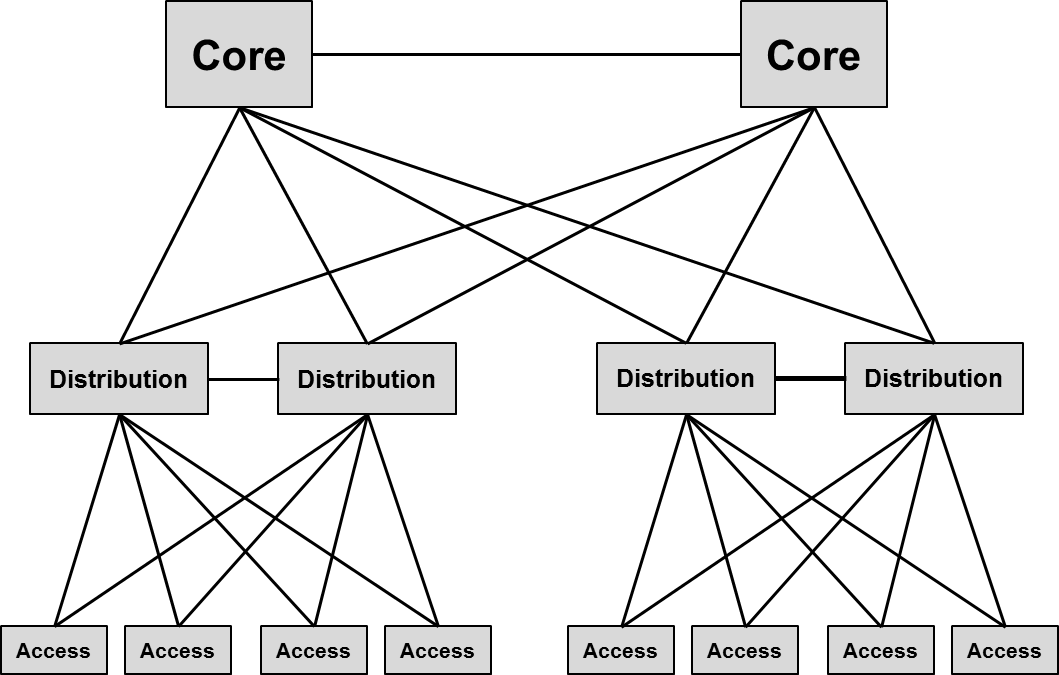
De façon plus rapide et pragmatique, les bonnes pratiques proposent des ratios d’oversubscription de 20:1 pour les liens entre le niveau « Access » et le niveau « Distribution », de 4:1 pour les liens entre le niveau « Distribution » et le niveau « Core » et 1:1 pour les liens entre le niveau « Access » des fermes de serveurs et le niveau « Core ». Si des congestions doivent se produire sur les liens d’interconnexion, les trames sont mises en files d’attentes et c’est la QoS qui peut prendre le relais afin de prioriser les flux critiques.
Si ces règles ne sont pas respectées, les algorithmes utilisés par le protocole TCP peuvent voir des pertes de segments qui ne leur permettront pas de tirer pleinement parti des débits à disposition.
S’il a toujours était relativement évident que les liens d’interconnexion entre le niveau « Access » et « Distribution » étaient au niveau 2, les liens entre le niveau « Distribution » et le niveau « Core » pouvaient être au niveau 2 ou au niveau 3. L’intérêt de mettre en place du routage était de faire en sorte que tous les liens soient utilisés en parallèle en cherchant le plus court chemin ou en répartissant la charge sur tous les chemins de coûts équivalents. Dans ce cas, la mise en place de réseaux virtuels de niveau 2 au travers de l’architecture était moins facile à réaliser, bien que pas impossible. L’utilisation du niveau 2 pour les liens entre le niveau « Distribution » et le niveau « Core » rendait l’architecture plus simple, mais ne permettait pas d’utiliser tous les liens en mode actif, puisqu’un protocole d’évitement de boucle Ethernet, tel que le « Spanning Tree » allait désactiver les liaisons correspondantes aux chemins redondants.
L’arrivée de l’agrégation du « Control Plane » entre plusieurs commutateurs (stacking, virtualisation, …) a changé la vision de l’architecture à trois niveaux, dans laquelle le protocole « Spanning Tree » ne voit plus de chemin redondant. Les liaisons doublées remontant sur deux commutateurs, dont le « Control Plane » est fusionné, sont agrégées ensemble à l’aide du protocole LACP IEEE 802.3ad.
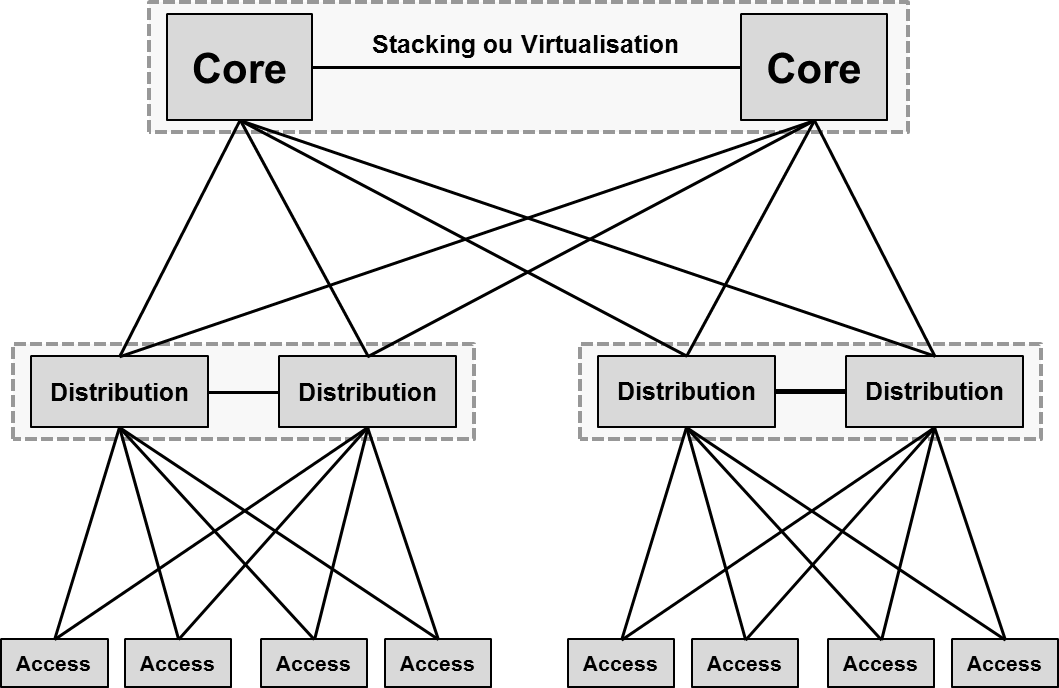
Non seulement toutes les liaisons sont actives, ce qui augmente les débits et favorise les ratios d’oversubscription, mais en cas de perte de l’une d’elle, les temps de reconvergence de l’architecture sont inférieurs à la seconde. Cette architecture « Subsecond Convergence » est plus adaptée au transport des flux UDP à fortes contraintes comme la voix.
La conséquence de la modification du déploiement des applications, de l’utilisation accrue des machines virtuelles et de la refonte du stockage a entraîné une modification des modèles de trafic dans le « Building Block » particulier des fermes de serveurs, qui passent de majoritairement client/serveur (nord-sud) à un niveau significatif de flux de serveur à serveur (est-ouest). Ces changements dans la matrice des flux a fait renaître, sous le nom de « Leaf-Spine », l’architecture mise au point par Charles Clos au sein des laboratoires Bell dans les années 1950. Dans son document [7], Charles Clos introduit le concept de réseau commuté à plusieurs étages dont l’avantage est de permettre la connexion entre un grand nombre de ports d’entrée et de sortie avec des commutateurs intermédiaires de petite taille. Le modèle mathématique permet de réaliser un réseau totalement non-bloquant comme un commutateur crossbar. La démonstration est généralement réalisée avec un système à trois étages (Ingress Stage ou Input Switches, Middle Stage ou Intermediary Switches et Egress Stage ou Output Switches), mais le modèle « Leaf-Spine » que nous utilisons est représenté sur deux niveaux ou « Two-Tier » (comme le précisait Charles Clos quand les points d’entrées sont aussi des points de sorties), dans lequel l’étage « Spine » est le niveau d’agrégation et l’étage « Leaf » représente le niveau « Access ».
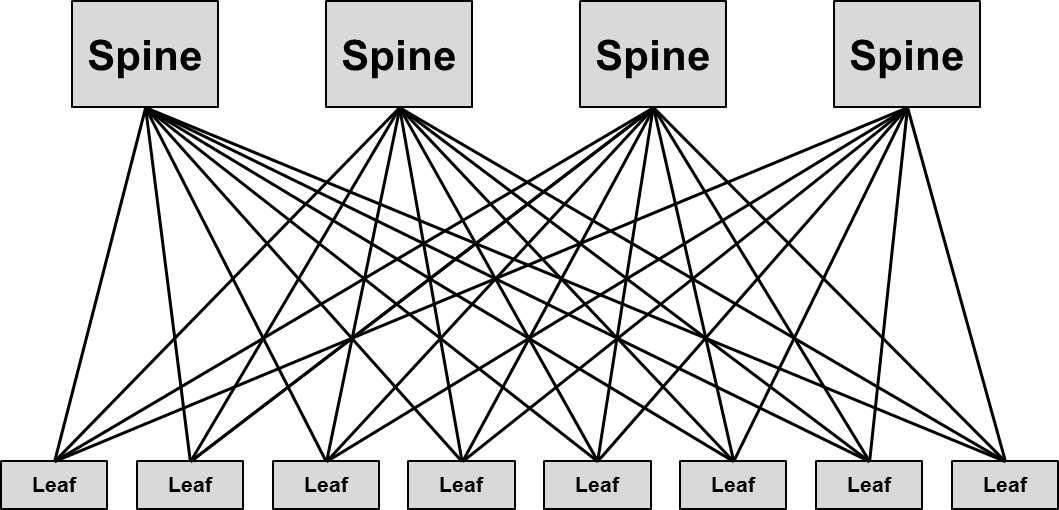
Dans cette architecture, il n’est plus nécessaire de fusionner le « Control Plane » des commutateurs « Spine », mais tous les liens doivent être actifs pour que le modèle fonctionne. Afin de ne pas être soumis à l’utilisation d’un protocole d’évitement de boucle de niveau 2 tel que le « Spanning Tree », un protocole de routage dynamique comme OSPF (Open Shortest Path First) permet de réaliser une architecture dont les liens sont utilisés en ECMP (Equal-Cost MultiPath). Les protocoles de routage tels que IS-IS (Intermediate System to Intermediate System) ou BGP (Border Gateway Protocol) peuvent également être implémentés dans ce genre d’architecture. On retrouve la difficulté de propagation de réseau virtuel de niveau 2 au travers de toute l’architecture, qui est contourné par l’encapsulation des trames Ethernet dans UDP grâce à l’usage du protocole VXLAN (Virtual eXtensible LAN – RFC 7348) qui réalise un tunnel « MAC-in-IP » pour le transport des réseaux virtuels de niveau 2 sur un réseau de niveau 3 (concept appelé « Overlay Network » par opposition au réseau de niveau 3 en support qui se nomme « Underlay Network »). Le protocole NVGRE (Network Virtualization using Generic Routing Encapsulation – RFC 7637) est une autre technologie « Overlay » permettant de construire un réseau de niveau 2 sur une infrastructure configurée en niveau 3.
Les protocoles SPB (Shortest Path Bridging – IEEE 802.1aq) et TRILL (TRansparent Interconnection of Lots of Links – RFC 6325 corrigé par les RFCs 6327, 6439, 7172, 7177, 7357, 7179, 7180, 7455, 7780 et 7783) ont été proposés comme une alternative au « Spanning Tree » pour pouvoir réaliser cette architecture entièrement en niveau 2 avec tous les liens actifs. Des constructeurs permettent de bâtir ce type d’architecture en niveau 2 pour des réseaux de petite à moyenne taille.
Pour que le modèle « Leaf-Spine » soit non-bloquant, il faudrait que pour chaque couple de port, il existe un arrangement de chemin pour connecter le port d’entrée avec le port de sortie, ce qui nécessiterait l’usage d’une grande quantité de nœuds « Spine » et de liens d’interconnexion. Au niveau « Spine », le ratio d’oversubscription est généralement de 1:1, c’est à dire que le débit des liens agrégés d’un commutateur « Leaf » est égal à celui d’un autre commutateur « Leaf » de sorte que tout le trafic reçu peut être renvoyé de façon non-bloquante. Le ratio d’oversubscription d’un commutateur « Leaf » vers un commutateur « Spine » doit, quant à lui, être planifié en fonction des besoins et il est généralement considéré qu’un ratio de 3:1 est acceptable.
L’usage des architectures Ethernet en boucle dans les réseaux métropolitains est plus lié à la topologie physique des fibres optiques qu’à une réalité en matière de planification efficace de la capacité. Que la topologie soit constituée d’un seul anneau ou de plusieurs anneaux avec un ou des points communs, cette architecture est considérée comme étant très résiliente. Pour éviter l’utilisation d’un protocole d’évitement de boucle tel que le « Spanning Tree », dont le temps de convergence est trop lent, des protocoles ont été mis au point. Le plus connu, ERP (Ethernet Ring Protection – ITU-T G.8032), utilisant des mécanisme Ethernet MAC et bridge standards, permet de mettre en place un mécanisme capable de converger en moins de 50 ms. Avant le protocole ERP, une autre approche appelée RPR (Resilient Packet Ring – IEEE 802.17) avait été essayée en introduisant une nouvelle entête MAC, qui n’était pas compatible avec Ethernet, et des algorithmes complexes qui ne rendaient pas viable cette approche sur le plan économique. ERP permet de mettre en place des topologies complexes à plusieurs anneaux pour répondre à des besoins de disponibilité physique des fibres optiques ou à des besoins d’accroissement de bande passante sur un anneau.
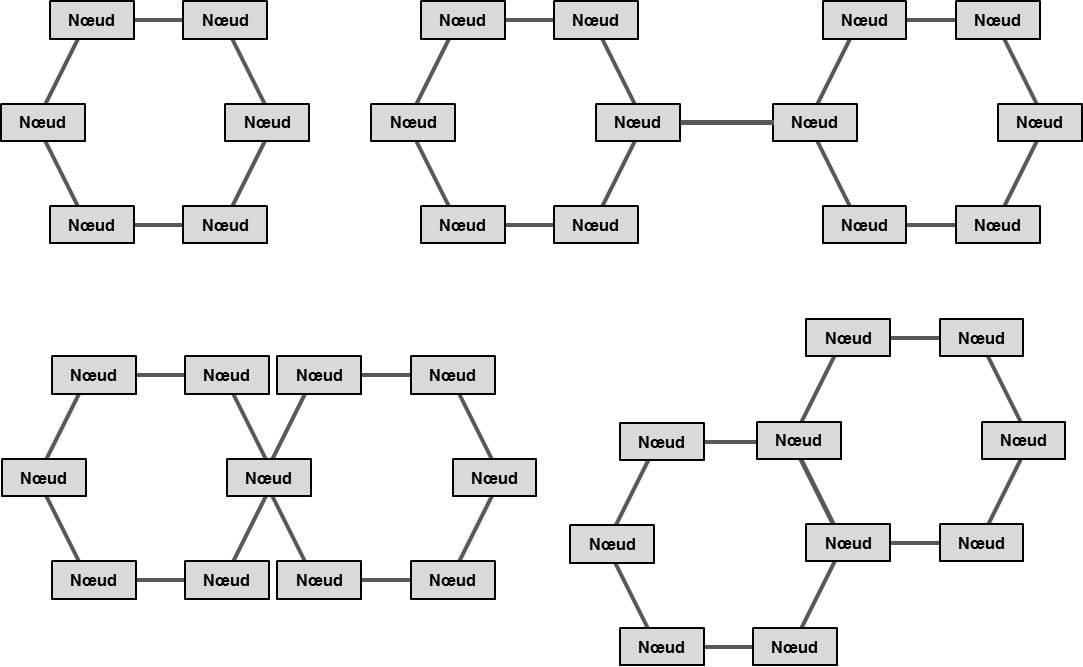
Le fait de cumuler les flux sur une boucle, engendre rapidement des ratios d’oversubscription très élevés. Des mécanismes de gestion de bande passante doivent être mis en place pour pouvoir garantir des niveaux de services aux utilisateurs, d’autant que ce genre de topologies sont souvent utilisées dans le cadre de réseaux opérés. Il faut noter que beaucoup de constructeurs ont développés leur propre protocole propriétaire sur certaines gammes de commutateurs, rendant impossible l’interopérabilité entre différents produits.
L’adjonction d’une couche WDM (Wavelength Division Multiplexing) permet d’augmenter le nombre de boucles pouvant être réalisées, voire même de changer de topologie, sans nécessiter l’utilisation de fibres optiques supplémentaires. Le multiplexage de longueurs d’ondes est réalisé dans la partie infrarouge du spectre électromagnétique. Le nombre de canaux, appelés circuits lambda, pouvant être multiplexés, ont augmenté avec le temps. On parle de CWDM (Coarse Wavelength-Division Multiplexing) et DWDM (Dense Wavelength-Division Multiplexing) pour positionner la capacité de multiplexage. Le CWDM est généralement limité à huit circuits lambdas, mais peut parfaitement aller au dessus tant que le coût de fabrication du matériel correspond à la logique de positionnement. Le DWDM permet de multiplexer beaucoup plus de circuits lambdas, grâce à l’utilisation d’une technologie plus précise mais plus coûteuse. Chaque circuit lambda permet de transporter un flux Ethernet dont le débit n’est limité que par la technologie Ethernet utilisée.
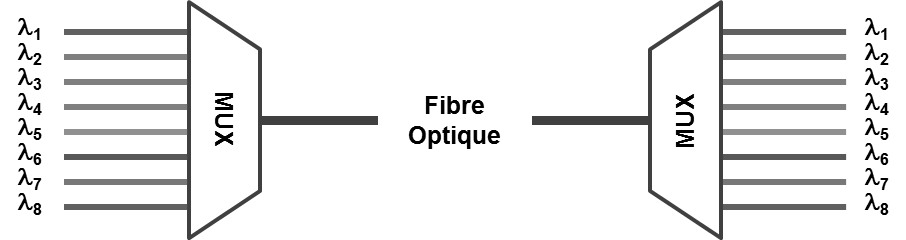
Le circuit lambda est vu comme une liaison physique, si ce n’est que l’émission/réception doit se faire sur une longueur d’onde précise afin d’être multiplexée sur la fibre optique physique. Si le commutateur ne sait pas émettre directement sur une couleur précise, sa lumière grise est prise en charge par un transpondeur dont le rôle sera d’adapter ce signal sur une couleur précise (un circuit lambda) tout en amplifiant le signal résultant. Le multiplexeur se charge de prendre tous les signaux des transpondeurs ou des adaptateurs natifs pour les multiplexer sur la fibre optique physique d’un côté et les démultiplexer à l’autre extrémité.
Lorsqu’il s’agit de s’intéresser à la couche 1 du modèle OSI et plus particulièrement à la fibre optique, il convient de compléter le concept WDM avec le protocole OTN (Optical Transport Network). Souvent qualifié de « Digital Wrapper », OTN est une méthode pour multiplexer différents services sur des chemins optiques. La recommandation ITU G.709 permet d’encapsuler la donnée cliente de façon transparente dans un container afin d’effectuer son transport sur le réseau optique. Si OTN peut être perçu comme un remplaçant de la technologie SONET/SDH, il apporte des améliorations de performance et des capacités de commutation au niveau OTU (Optical Transport Unit).
