Ascoltare, parlare e scrivere
30 Parlare di IA: Elaborazione del linguaggio naturale
L’elaborazione del linguaggio naturale è un argomento su cui la ricerca ha lavorato a lungo negli ultimi 50 anni. Ciò ha portato allo sviluppo di molti strumenti che utilizziamo quotidianamente:
- Elaboratori di testi,
- Correzione automatica della grammatica e dell’ortografia,
- completamento automatico,
- Riconoscimento ottico dei caratteri (OCR).
Più di recente, i chatbot, gli assistenti domestici e gli strumenti di traduzione automatica hanno avuto un enorme impatto in tutti i settori.

Per molto tempo, la ricerca e l’industria sono state bloccate dalla complessità intrinseca del linguaggio. Alla fine del XX secolo, le grammatiche di una lingua, scritte da esperti, potevano avere fino a 50.000 regole. Questi sistemi esperti dimostravano che la tecnologia poteva fare la differenza, ma le soluzioni robuste erano troppo complesse da sviluppare.
D’altra parte, il riconoscimento vocale doveva essere in grado di utilizzare i dati acustici e trasformarli in testo. Con la varietà di parlanti che si possono trovare, un compito davvero difficile!
I ricercatori hanno capito che se avessimo avuto un modello della lingua desiderata, le cose sarebbero state più facili: se avessimo saputo quali erano le parole della lingua, come si formavano le frasi, allora sarebbe stato più facile trovare la frase giusta da un insieme di candidati che corrispondesse a un dato enunciato, o produrre una traduzione valida da un insieme di possibili sequenze di parole.
Un altro tema cruciale è stato quello della semantica. La maggior parte del lavoro che possiamo fare per risolvere questioni linguistiche è superficiale: gli algoritmi produrranno una risposta basata su alcune regole sintattiche locali. Se alla fine il testo non significa nulla, così sia. Una cosa simile può accadere quando leggiamo un testo di qualche alunno: possiamo correggere gli errori senza capire veramente di cosa parla il testo! La vera sfida è associare il significato al testo e, quando possibile, alle frasi pronunciate.
Nel 2008 è stato raggiunto un risultato sorprendente1: un unico modello linguistico poteva essere appreso da una grande quantità di dati e utilizzato per una varietà di compiti linguistici. In effetti, quel modello unico aveva prestazioni migliori rispetto ai modelli addestrati per i compiti specifici.
Il modello era una rete neurale profonda. Non così profonda come i modelli usati oggi! Ma abbastanza da convincere la ricerca e l’industria che l’apprendimento automatico, e più specificamente l’apprendimento profondo, sarebbe stato la risposta a molte domande in NLP (Natural Language Processing).
Da allora, l’elaborazione del linguaggio naturale (NLP) ha smesso di seguire un approccio basato sui modelli e si è quasi sempre basata su un approccio basato sui dati.
Tradizionalmente, i principali compiti linguistici possono essere suddivisi in due famiglie: quelli che riguardano la costruzione di modelli e quelli che riguardano la decodifica.
Costruire modelli
Per trascrivere, rispondere a domande, generare dialoghi o tradurre, è necessario essere in grado di sapere se “Je parle Français” è effettivamente una frase in francese oppure no. E poiché nel linguaggio parlato la grammatica non è sempre seguita con precisione, la risposta dovrà essere probabilistica: una frase è più o meno francese.Questo permette al sistema di produrre diverse frasi candidate (come la trascrizione di un suono, la traduzione di una frase, …) e la probabilità può essere un punteggio. Si può prendere la frase più alta in classifica o combinare il punteggio con altre fonti di informazione (si può anche essere interessati all’argomento della frase).
I modelli linguistici fanno questo: le probabilità sono costruite da algoritmi di apprendimento automatico. Naturalmente, più dati ci sono, meglio è. Per alcune lingue ci sono molti dati su cui costruire i modelli linguistici. Per altre non è così: si tratta di lingue con poche risorse.
Nel caso della traduzione, vogliamo non 2 ma 3 modelli: un modello linguistico per ogni lingua e un altro modello per le traduzioni, che ci informi su quali possano essere le migliori traduzioni di frammenti di lingua. Questi modelli sono difficili da produrre quando i dati sono scarsi. Se i modelli per le coppie di lingue comuni sono più facili da costruire, non sarà così per le lingue che non sono frequentemente parlate insieme (ad esempio il portoghese e lo sloveno). Una tipica via d’uscita in questo caso è quella di utilizzare una lingua pivot (tipicamente l’inglese) e tradurre attraverso questa lingua pivot: dal portoghese all’inglese e poi dall’inglese allo sloveno. Ovviamente i risultati sono inferiori perché gli errori si accumulano.
Decodifica
La decodifica è il processo con cui un algoritmo prende la sequenza in ingresso (che può essere un segnale o un testo) e, consultando i modelli, prende una decisione, che spesso sarà un testo in uscita. Ci sono alcune considerazioni di carattere algoritmico: in molti casi la trascrizione e la traduzione devono avvenire in tempo reale e la riduzione del ritardo è un aspetto fondamentale. C’è quindi spazio per l’intelligenza artificiale.
End-to-end
Oggi, l’approccio che prevede la costruzione di questi componenti separatamente e la loro successiva combinazione è stato sostituito da approcci end-to-end in cui il sistema trascrive/traduce/interpreta l’input attraverso un modello unico. Attualmente, tali modelli sono addestrati da reti neurali profonde che possono essere enormi: si dice che l’attuale modello GPT3 più grande comprenda diverse centinaia di milioni di parametri!
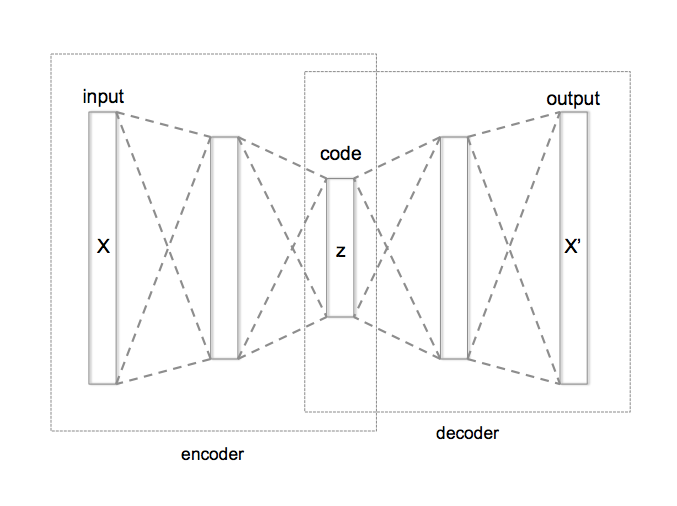
Proviamo a dare un’occhiata a questa intuizione: supponiamo di avere dei dati. Questi dati grezzi possono essere codificati in qualche modo. Ma la codifica può essere molto ridondante e forse anche costosa. Costruiamo ora una macchina particolare, chiamata autocodificatore (vedi schema sotto). Questa macchina sarà in grado di prendere un testo, comprimerlo in un piccolo vettore (questo è il codificatore), e poi decomprimere il vettore (la parte del decodificatore) e restituire un testo che è in qualche modo vicino al testo originale. L’idea è che questo meccanismo renda il vettore intermedio molto significativo con due proprietà desiderabili: un vettore ragionevolmente piccolo che “contiene” le informazioni del testo iniziale.
Il futuro
Un esempio di end-to-end che vedremo presto sarà in grado di svolgere il seguente compito: vi ascolterà parlare la vostra lingua, trascriverà il vostro testo, lo tradurrà in una lingua che non conoscete, addestrerà un sistema di sintesi vocale alla vostra voce e farà in modo che la vostra voce pronunci il testo corrispondente in una nuova frase. Ecco due esempi prodotti dai ricercatori dell’Universidad Politecnica de Valencia, in Spagna, in cui il modello vocale dell’oratore viene utilizzato per il doppiaggio.
Alcune conseguenze per l’istruzione
I progressi costanti dell’elaborazione del linguaggio naturale sono notevoli. Se solo 10 anni fa ridevamo delle traduzioni stupide proposte dall’intelligenza artificiale, oggi è sempre più difficile trovare errori grossolani. Anche le tecniche di riconoscimento vocale e di riconoscimento dei caratteri stanno migliorando rapidamente.
Le sfide semantiche sono ancora presenti e la risposta a domande che richiedono una comprensione profonda di un testo non funziona ancora bene. Ma le cose stanno andando nella giusta direzione. Ciò significa che l’insegnante dovrebbe aspettarsi che alcune delle seguenti affermazioni diventino presto vere, se non lo sono già:
- un alunno prenderà un testo complesso e ne otterrà (con l’IA) una versione semplificata; il testo potrà anche essere personalizzato e utilizzare termini, parole e concetti a cui l’alunno è abituato;
- un allievo sarà in grado di prendere un testo e di ottenere un testo che dice le stesse cose, ma non rilevabile da uno strumento antiplagio;
- i video prodotti in qualsiasi parte del mondo saranno accessibili attraverso il doppiaggio automatico in qualsiasi lingua: questo significa in particolare che i nostri alunni non saranno esposti solo a materiale didattico costruito nella nostra lingua, ma anche a materiale inizialmente progettato per un altro sistema di apprendimento, un’altra cultura;
- costruire saggi potrebbe diventare un compito del passato, poiché gli strumenti consentono di scrivere qualcosa su qualsiasi argomento.
In questi esempi è chiaro che l’IA sarà tutt’altro che perfetta e l’esperto si accorgerà che se il linguaggio è corretto, non lo è il flusso di idee. Ma diciamocelo: nel corso dell’istruzione, quanto tempo ci vuole perché i nostri alunni e studenti raggiungano questo livello?
1 Collobert, Ronan, and Jason Weston. “A unified architecture for natural language processing: Deep neural networks with multitask learning.” Proceedings of the 25th international conference on Machine learning. 2008. http://machinelearning.org/archive/icml2008/papers/391.pdf. Nota: questo riferimento è dato per ragioni storiche. Ma è difficile da leggere!
