Gestire l’apprendimento
16 Parlare di IA: Sistemi basati sui dati – Parte 1
Decisioni in classe
Come insegnanti, avete accesso a molti tipi di dati. Dati tangibili, come i registri delle presenze e delle prestazioni, o intangibili, come il linguaggio del corpo degli studenti. Considerate alcune delle decisioni che prendete nella vostra vita professionale: Quali sono i dati che vi aiutano a prendere queste decisioni?
Esistono applicazioni tecnologiche che possono aiutarvi a visualizzare o elaborare i dati. I sistemi di intelligenza artificiale utilizzano i dati per personalizzare l’apprendimento, fare previsioni e prendere decisioni che potrebbero aiutarvi a insegnare e a gestire la classe: avete esigenze a cui la tecnologia può rispondere? Se sì, quali sono i dati che un sistema di questo tipo potrebbe richiedere per svolgere il compito?

I sistemi educativi hanno sempre generato dati: dati personali degli studenti, registri accademici, dati di frequenza e altro ancora. Con la digitalizzazione e le applicazioni AIED, vengono registrati e memorizzati molti più dati: clic del mouse, pagine aperte, timestamp e battute della tastiera1. Con il pensiero incentrato sui dati che sta diventando la norma nella società, è naturale chiedersi come si possano analizzare tutti questi dati per fare qualcosa di appropriato: Possiamo fornire un feedback più personalizzato al discente? Potremmo progettare strumenti di visualizzazione e notifica migliori per l’insegnante?2
Qualunque sia la tecnologia utilizzata, deve soddisfare un’esigenza reale in classe. Una volta identificata l’esigenza, possiamo esaminare i dati disponibili e chiederci cosa sia rilevante per il risultato desiderato. Si tratta di scoprire i fattori che consentono agli educatori di prendere decisioni complesse. Questi fattori possono essere catturati utilizzando i dati disponibili? I dati e i sistemi basati sui dati sono il modo migliore per affrontare il bisogno? Quali potrebbero essere le conseguenze indesiderate di questo utilizzo dei dati?3
L’apprendimento automatico (Machine Learning – LM) ci permette di rinviare molte di queste domande ai dati stessi4. Le applicazioni di ML sono addestrate sui dati. Funzionano operando sui dati. Trovano schemi e generalizzazioni e li memorizzano come modelli – dati che possono essere utilizzati per rispondere a domande future4. Anche le loro decisioni e previsioni, e il modo in cui queste influiscono sull’apprendimento degli studenti, sono tutti dati. Pertanto, sapere come i programmatori, la macchina e l’utente gestiscono i dati è una parte importante della comprensione del funzionamento dell’intelligenza artificiale.
I Dati
I dati riguardano generalmente un’entità del mondo reale: una persona, un oggetto o un evento. Ogni entità può essere descritta da una serie di attributi (caratteristiche o variabili)5. Ad esempio, nome, età e classe sono alcuni attributi di uno studente. L’insieme di questi attributi è il dato che abbiamo sullo studente che, pur non essendo in alcun modo vicino all’entità reale, ci dice qualcosa su di lui. I dati raccolti, utilizzati ed elaborati nel sistema educativo, sono chiamati dati educativi1.
Un dataset è un insieme di entità disposte in righe e colonne. Il registro delle presenze di una classe è un dataset. Ogni riga rappresenta il record di uno studente. Le colonne possono essere la presenza o l’assenza durante un particolare giorno o sessione. Ogni colonna è quindi un attributo.
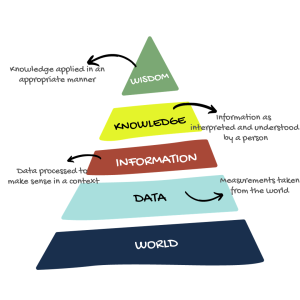
I dati vengono creati scegliendo gli attributi e misurandoli: ogni dato è il risultato di decisioni e scelte umane. La creazione dei dati è quindi un processo soggettivo, parziale e disordinato, soggetto a difficoltà tecniche4,5.Inoltre, ciò che scegliamo di misurare e ciò che non misuriamo può avere una grande influenza sui risultati attesi.
Le tracce dei dati (datatraces) sono registrazioni dell’attività degli studenti, come i clic del mouse, i dati sulle pagine aperte, la tempistica delle interazioni o la pressione dei tasti in un sistema digitale1. Metadati, cioè dati che descrivono altri dati5. I dati derivati sono dati calcolati o dedotti da altri dati: I punteggi individuali di ogni studente sono dati. La media della classe è un dato derivato. Spesso i dati derivati sono più utili per ottenere intuizioni utili, trovare modelli e fare previsioni. Le applicazioni di Machine Learning possono creare dati derivati e collegarli con tracce di metadati per creare modelli dettagliati di studenti, che aiutano a personalizzare l’apprendimento1.
Affinché qualsiasi applicazione basata sui dati abbia successo, gli attributi devono essere scelti con cura e misurati correttamente. I modelli scoperti devono essere verificati per vedere se hanno senso nel contesto educativo. Se progettati e mantenuti correttamente, i sistemi basati sui dati possono essere molto preziosi.
Questo capitolo intende introdurre alcune nozioni di base sui dati e sulle tecnologie basate sui dati, ma l’alfabetizzazione ai dati è un’abilità molto importante da possedere e merita una formazione dedicata, un supporto e un aggiornamento continui1.
Legislazione da conoscere
Grazie al drastico calo dei costi di archiviazione dei dati, una maggiore quantità di dati e metadati viene salvata e conservata più a lungo6. Questo può portare a violazioni della privacy e dei diritti. Leggi come il General Data Protection Regulation (GDPR) scoraggiano tali pratiche e offrono ai cittadini dell’UE un maggiore controllo sui loro dati personali. Il regolamento fornisce norme sulla protezione dei dati giuridicamente vincolanti in tutti gli Stati membri dell’UE.

Secondo il GDPR, i dati personali sono tutte le informazioni relative a una persona identificata o identificabile (soggetto dei dati). Le scuole, oltre a collaborare con le aziende che gestiscono i loro dati, conservano enormi quantità di informazioni personali su studenti, genitori, personale, dirigenti e fornitori. In qualità di responsabili del trattamento dei dati, sono tenute a conservare i dati che trattano in modo confidenziale e sicuro e a disporre di procedure per la protezione e l’uso corretto di tutti i dati personali1.
I diritti stabiliti dal GDPR comprendono:
- Il Diritto di Accesso, che rende obbligatorio per i cittadini la possibilità di sapere facilmente quali dati vengono raccolti su di loro.
- Il Diritto del cittadino di essere informato sull’utilizzo dei suoi dati
- Il Diritto alla Cancellazione, che consente a un cittadino i cui dati sono stati raccolti da una piattaforma di chiedere che tali dati siano rimossi dal dataset costruito dalla piattaforma (e che può essere venduto a terzi).
- Il Diritto alla Spiegazione: ogni volta che i cittadini hanno bisogno di chiarimenti sui processi decisionali automatizzati che li riguardano, deve essere fornita una spiegazione.
Tuttavia, il GDPR consente la raccolta di alcuni dati in base al “legittimo interesse“7e l’utilizzo di dati derivati, aggregati o anonimizzati a tempo indeterminato e senza consenso.5 Il nuovo Digital Services Act limita l’utilizzo dei dati personali per scopi pubblicitari specifici.7 Oltre a questi, the EU-US Privacy Shield (lo Scudo per la privacy UE-USA) rafforza i diritti di protezione dei dati dei cittadini dell’UE nel caso in cui i loro dati siano stati trasferiti al di fuori dell’UE5.
Si può fare riferimento al documento GDPR for dummies per l’analisi effettuata da esperti indipendenti dell’Unione delle Libertà Civili per l’Europa (Civil Liberties Union for Europe – Liberties), che è un organo di controllo che tutela i diritti umani di tutti nell’Unione Europea.
1 Ethical guidelines on the use of artificial intelligence and data in teaching and learning for educators, European Commission, October 2022.
2 du Boulay, B., Poulovasillis, A., Holmes, W., Mavrikis, M., Artificial Intelligence And Big Data Technologies To Close The Achievement Gap,in Luckin, R., ed. Enhancing Learning and Teaching with Technology, London: UCL Institute of Education Press, pp. 256–285, 2018.
3 Hutchinson, B., Smart, A., Hanna, A., Denton, E., Greer, C., Kjartansson, O., Barnes, P., Mitchell, M., Towards Accountability for Machine Learning Datasets: Practices from Software Engineering and Infrastructure, Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, Association for Computing Machinery, New York, 2021.
4 Barocas, S., Hardt, M., Narayanan, A., Fairness and machine learning Limitations and Opportunities, 2022.
5 Kelleher, J.D, Tierney, B, Data Science, MIT Press, London, 2018.
6 Schneier, B., Data and Goliath: The Hidden Battles to Capture Your Data and Control Your World, W. W. Norton & Company, 2015.
7 Kant, T., Identity, Advertising, and Algorithmic Targeting: Or How (Not) to Target Your “Ideal User.”, MIT Case Studies in Social and Ethical Responsibilities of Computing, 2021.

{kind=link}