Il reperimento delle informazioni
10 Parola all’IA: l’indicizzazione sui motori di ricerca
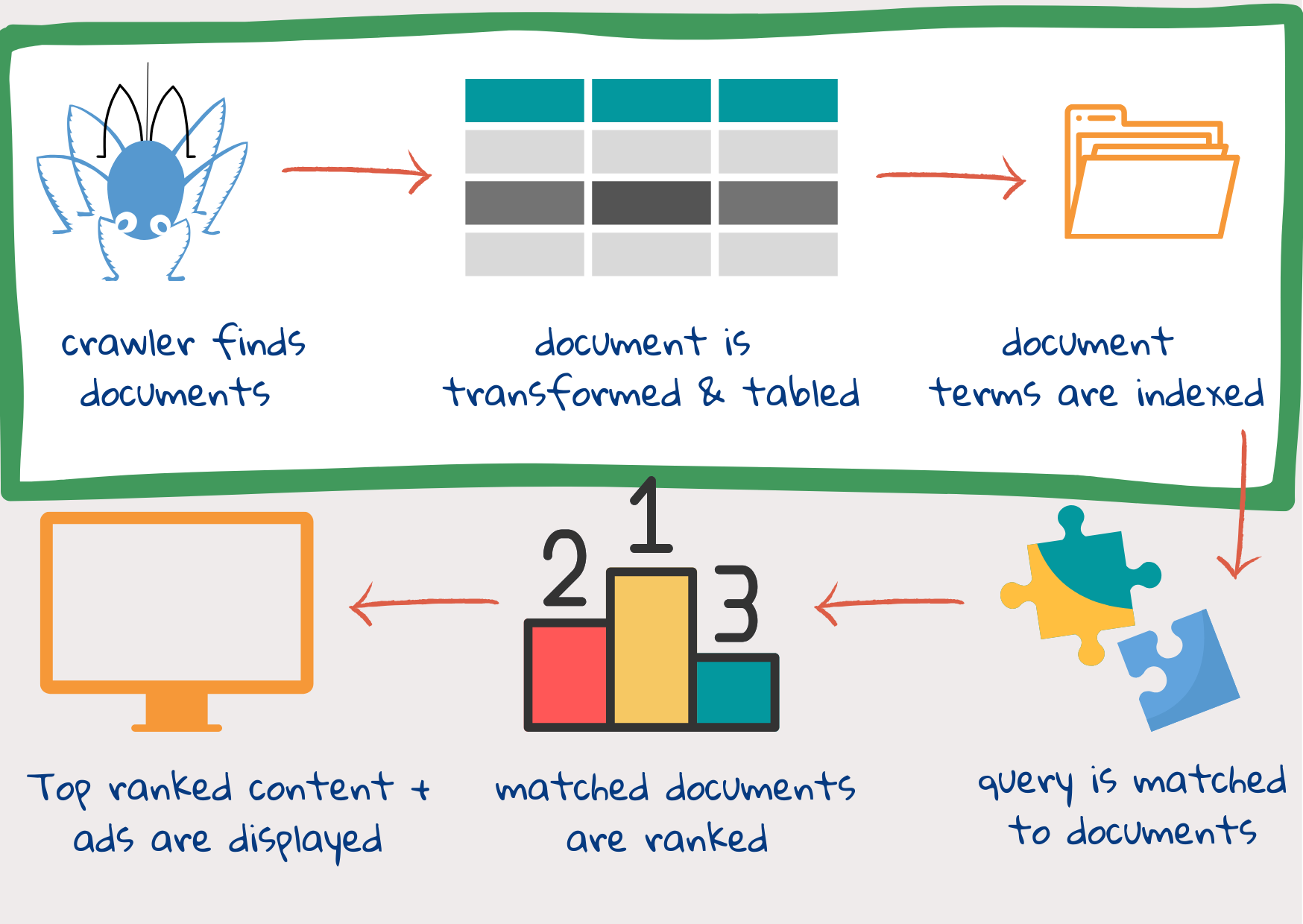
Un motore di ricerca prende delle parole chiave inserite in una casella di testo, la query di ricerca, e cerca di trovare i documenti web che corrispondono alla necessità di informazioni di un utente. Poi mostra le informazioni in un formato facilmente accessibile, con la pagina più pertinente in alto. Per farlo, il motore di ricerca deve iniziare a trovare documenti sul web e a taggarli in modo che siano facilmente reperibili. Vediamo a grandi linee come funziona il processo:
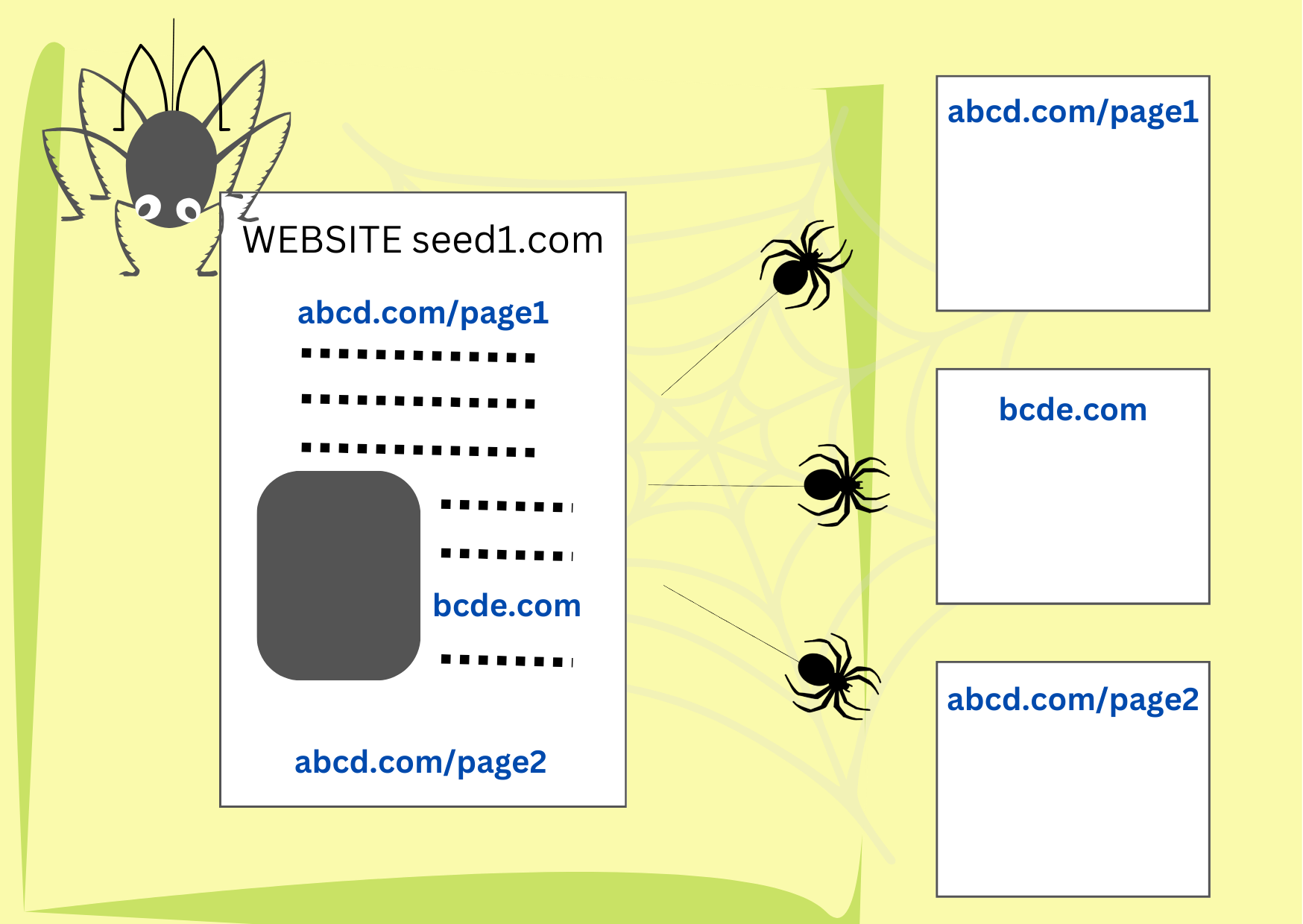
Fase 1: i web crawler trovano e scaricano i documenti.
con licenza CC BY-SA 4.0. Per visualizzare una copia di questa licenza, visitare https://www.seobility.net/en/wiki/Creative_Commons_License_BY-SA_4.0
Dopo che un utente ha inserito una query di ricerca, è troppo tardi per andare a cercare tutti i contenuti disponibili in Internet1. I documenti web sono previamente visionati e il loro contenuto viene frazionato e archiviato in slot diversi. Quando la query è disponibile, tutto ciò che bisogna fare è combinare il contenuto della query con quello degli slot.
I web crawler sono frammenti di codice che trovano e scaricano documenti dal web. Iniziano con una serie di indirizzi di siti web (URL) cercando al loro interno collegamenti a nuove pagine web. Poi scaricano le nuove pagine e al loro interno cercano ulteriori collegamenti. Purché l’elenco iniziale fosse sufficientemente diversificato, i crawler finiscono per visitare qualsiasi sito consenta loro l’accesso, spesso svariate volte, alla ricerca di aggiornamenti.
Fase 2: il documento viene scomposto in molteplici parti
 Il documento scaricato dal crawler potrebbe essere una pagina web chiaramente strutturata con la propria descrizione del contenuto, l’indicazione dell’autore, della data ecc. Può anche essere un’immagine digitalizzata malamente di un vecchio libro custodito in una biblioteca. Di norma i motori di ricerca sono in grado di leggere un centinaio di tipi diversi di documenti1. Li convertono in formato html o xml e li archiviano in tabelle (denominate BigTable nel caso di Google).
Il documento scaricato dal crawler potrebbe essere una pagina web chiaramente strutturata con la propria descrizione del contenuto, l’indicazione dell’autore, della data ecc. Può anche essere un’immagine digitalizzata malamente di un vecchio libro custodito in una biblioteca. Di norma i motori di ricerca sono in grado di leggere un centinaio di tipi diversi di documenti1. Li convertono in formato html o xml e li archiviano in tabelle (denominate BigTable nel caso di Google).
Una tabella è costituita da sezioni più piccole denominate tablet, ogni riga di un tablet è dedicata a una pagina web.
Queste righe sono disposte secondo un ordine registrato insieme a un registro per gli aggiornamenti. Ogni colonna riporta delle informazioni specifiche collegate alla pagina web che possono essere di aiuto nel combinare il contenuto del documento ai contenuti di query future. Le colonne riportano:
- l’indirizzo del sito web che potrebbe, di per sé, fornire una buona descrizione dei contenuti della pagina, se la home page contiene contenuti rappresentativi, o il collegamento a una pagina laterale con contenuto inerente.
- Titoli, intestazioni e parole in grassetto che descrivono contenuti importanti.
- Metadati della pagina. Si tratta di informazioni inerenti alla pagina che non costituiscono parte del contenuto principale, come il tipo del documento (per es. e-mail o pagina web), la struttura e le caratteristiche del documento, come la sua lunghezza, le parole chiave, i nomi degli autori e la data di pubblicazione.
- La descrizione di link da altre pagine a questa pagina, che fornisce una formulazione testuale succinta dei diversi aspetti del contenuto della pagina. Più sono i link, più sono le descrizioni e le colonne utilizzate. La presenza di link viene utilizzata anche a fini di ranking, per stabilire quanto sia visualizzata una pagina web (date un’occhiata al PageRank di Google, un sistema di classificazione che utilizza i link a e da una pagina per valutare qualità e popolarità).
- I nomi di persone, società, organizzazioni, di località, gli indirizzi, indicazioni di date e orari, quantità e valori monetari ecc.. Gli algoritmi di apprendimento automatico possono essere addestrati al reperimento di questi elementi in qualsiasi contenuto utilizzando dei dati di addestramento inseriti da un essere umano1.
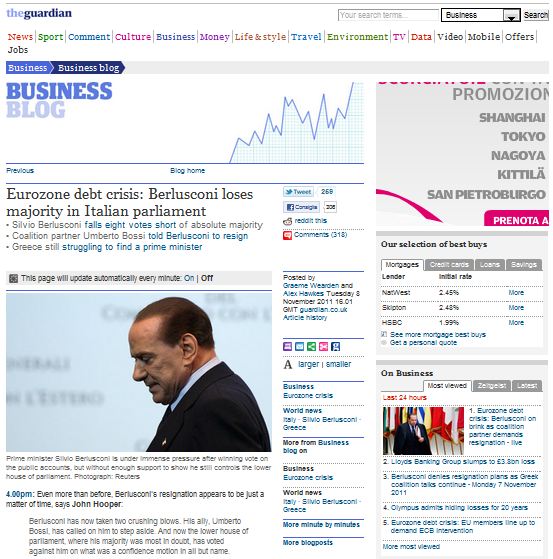
Una colonna della tabella, forse la più importante, presenta il contenuto principale del documento, che deve essere identificato tra tutti i link e gli annunci pubblicitari esterni. Una tecnica utilizza un modello di apprendimento automatico per “apprendere” quale sia il contenuto principale di una pagina web.
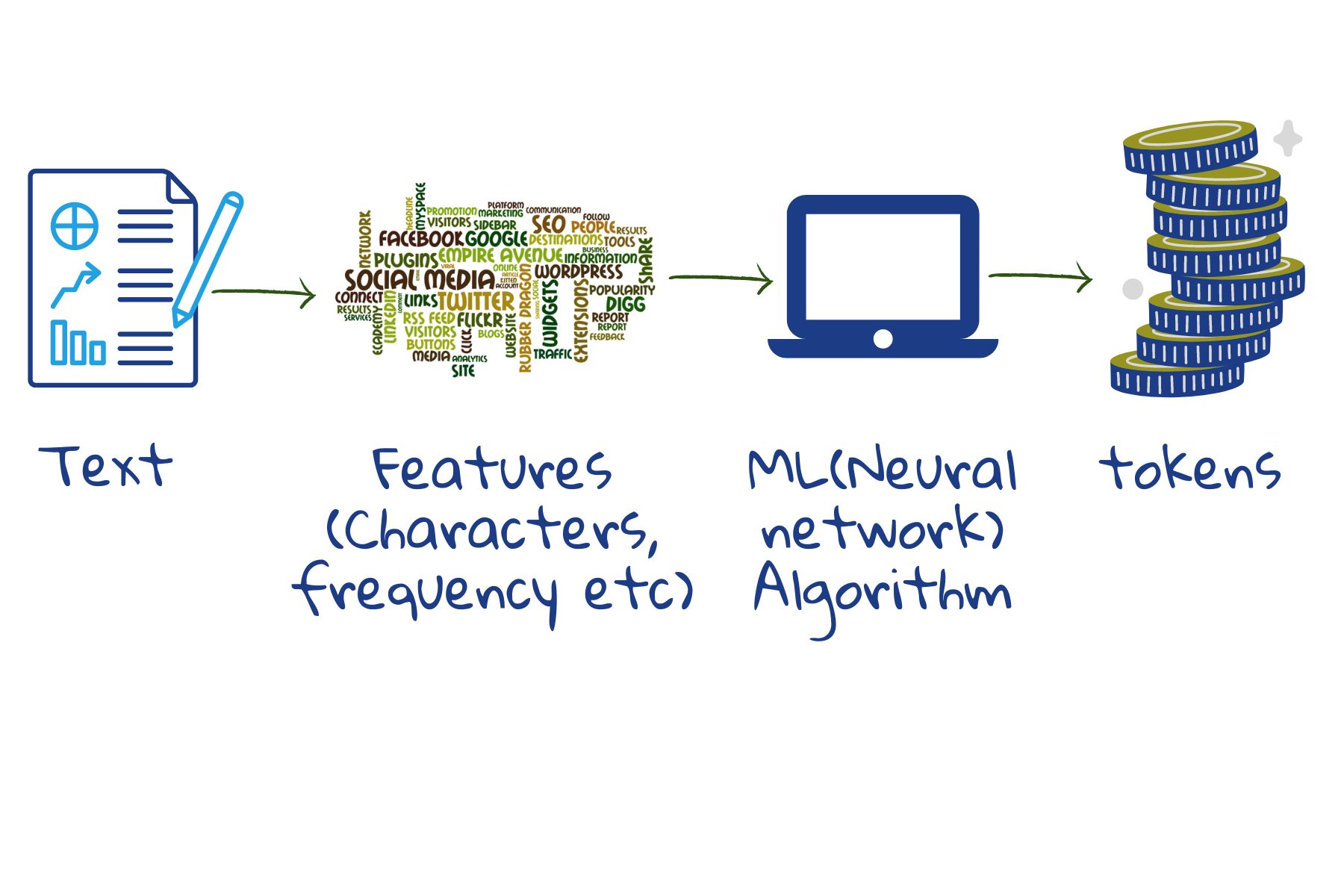
Possiamo naturalmente combinare delle parole esatte tratte dalla query con le parole contenute in un documento web, come faremmo con il pulsante Find (Trova) di un programma di videoscrittura. Ma non è una soluzione molto efficace in quanto le persone usano parole diverse per definire il medesimo oggetto. Registrare semplicemente i termini separati non aiuterà a catturare il modo in cui essi si combinano tra loro per creare significato: in definitiva è il pensiero dietro le parole che ci aiuta a comunicare e non le parole di per sé stesse. Pertanto, tutti i motori di ricerca trasformano il testo in un modo che renda più semplice combinarlo con il significato del testo della query. Successivamente, la query viene elaborata in modo analogo.
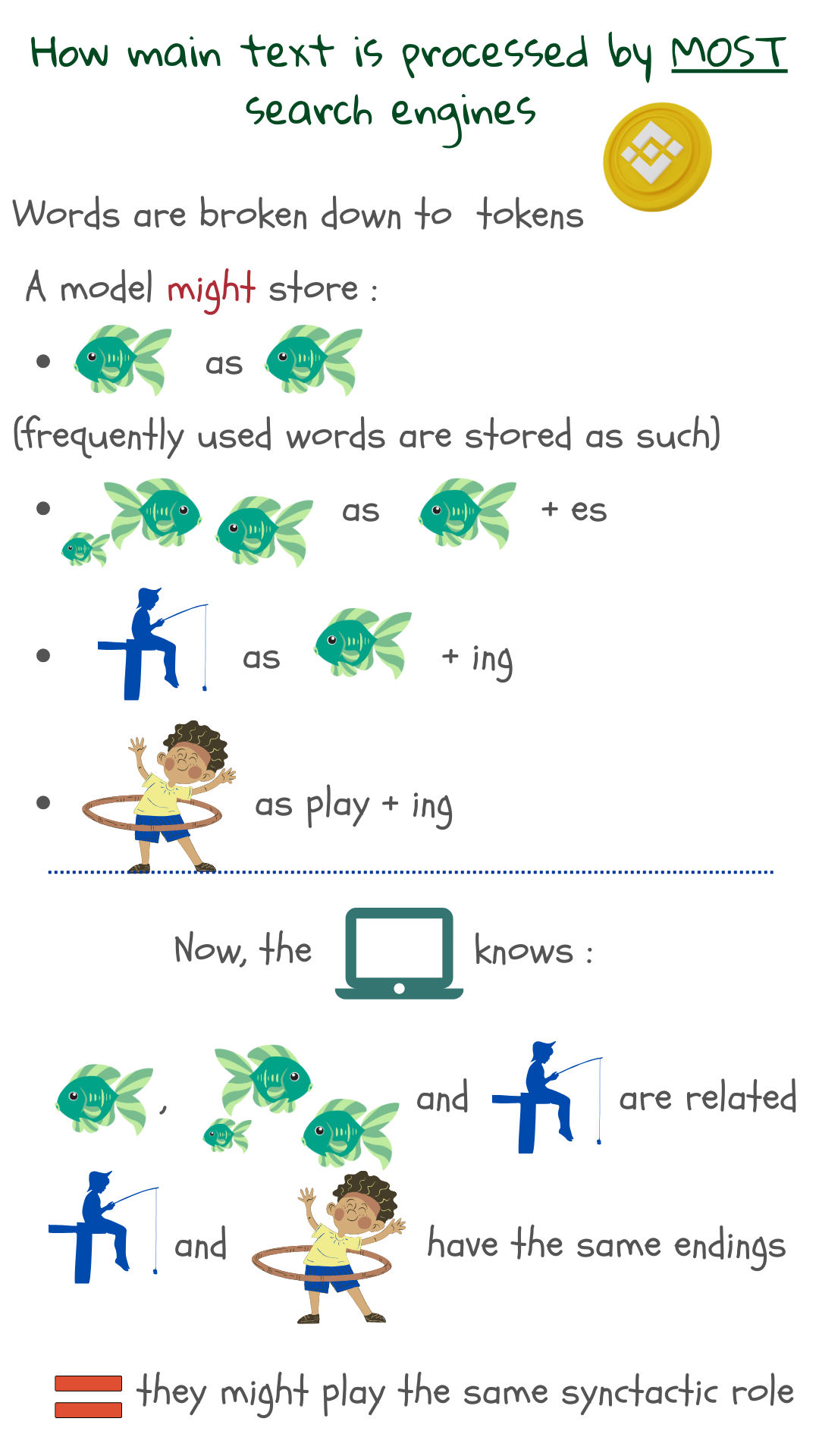
In quanto segmenti di parole, il numero totale di token diversi che devono essere archiviati si riduce. I modelli attuali archiviano da trentamila a cinquantamila token2. Delle parole scritte in modo scorretto possono essere individuate in quanto parti di esse continuano a corrispondere ai token archiviati. Delle parole sconosciute possono emergere dai risultati delle ricerche, dal momento che parti di esse potrebbero corrispondere con i token archiviati.
Nel nostro caso, il set di addestramento per l’apprendimento automatico è costituito da testi esemplificativi. Iniziando da singoli caratteri, spazi e segni di interpunzione, il modello fonde caratteri che si presentano frequentemente per formare nuovi token. Se il numero di token non è sufficientemente elevato, il processo di fusione continua in modo da coprire parti di parole più grandi o meno frequenti. In questo modo si riescono a coprire la maggior parte delle parole, delle terminazioni delle parole e tutti i prefissi. Quindi, fornito un nuovo testo, la macchina lo può suddividere facilmente in token e archiviare.
Fase 3: si crea un indice per farvi agevolmente riferimento

Per visualizzare una copia di questa licenza, visitare: https://creativecommons.org/licenses/by-nd/2.0/?ref=openverse.
Quando i dati sono inseriti in BigTable, si crea un indice. Similarmente al concetto degli indici dei libri, l’indice di ricerca elenca i token contenuti in un documento web e la loro posizione, insieme a statistiche come quelle inerenti al numero di volte in cui un token si rinviene all’interno di un documento, quanto importante sia per il documento ecc. e a informazioni sulla sua posizione, per esempio se il token si trovi nel titolo o in un’intestazione, sia concentrato in una parte del documento e se un token ne segua sempre un altro.
Oggi, molti motori di ricerca utilizzano una combinazione di modelli di indicizzazione tradizionali e linguistici generati da reti neurali profonde. I secondi codificano dettagli semantici del testo e consentono una miglior comprensione delle query3.
Aiutano i motori di ricerca a superare la query al fine di catturare le informazioni necessarie alla base della creazione della query.
Queste tre fasi forniscono un resoconto semplificato di ciò che viene definito “indicizzazione”, ossia reperire, preparare e archiviare documenti creando un indice. Il passaggio successivo sono le fasi del “ranking” consistenti nel combinare query e contenuto e nel mostrare i risultati in base alla pertinenza.
1 Croft, B., Metzler D., Strohman, T., Search Engines, Information Retrieval in Practice, 2015
2 Sennrich,R., Haddow, B., and Birch, A., Neural Machine Translation of Rare Words with Subword Units, In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1715–1725, Berlin, Germany. Association for Computational Linguistics, 2016.
3 Metzler, D., Tay, Y., Bahri, D., Najork, M., Rethinking Search: Making Domain Experts out of Dilettantes, SIGIR Forum 55, 1, Article 13, June 2021.

{kind=link}