Il reperimento delle informazioni
11 Parlare di IA: posizionamento nei motori di ricerca
Rispetto ai motori di ricerca dei primi anni 2000, i motori di ricerca attuali effettuano analisi più ricche e profonde. Ad esempio, oltre a contare le parole, sono in grado di analizzare e confrontare il significato delle parole stesse1. Gran parte di questa ricchezza avviene nel processo di classificazione:
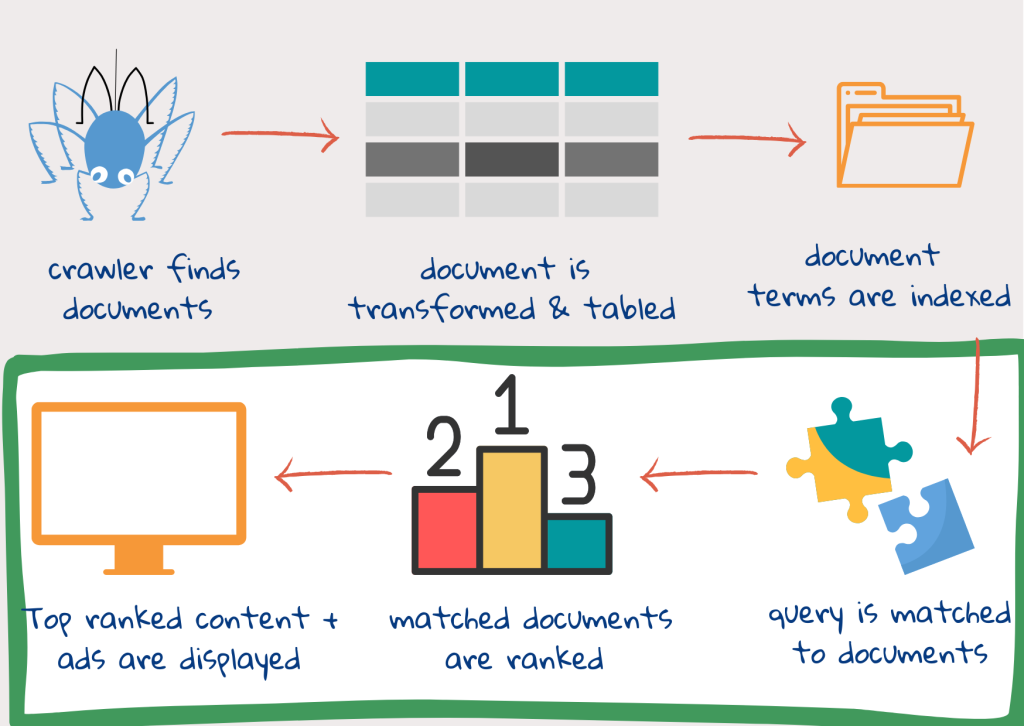
Fase 4: I termini della query vengono abbinati ai termini dell’indice

Una volta che l’utente digita la query e clicca su cerca, la query viene elaborata. I token vengono creati con lo stesso processo del testo del documento. Poi la query può essere ampliata aggiungendo altre parole chiave. Questo per evitare il caso in cui i documenti rilevanti non vengano trovati perché la query utilizza parole leggermente diverse da quelle degli autori dei contenuti web. Questo viene fatto anche per cogliere le differenze nell’uso e nella consuetudine. Ad esempio, l’uso di parole come Presidente, Primo Ministro e Cancelliere può essere cambiato a seconda del Paese1.
La maggior parte dei motori di ricerca tiene traccia delle ricerche effettuate dagli utenti (Guardate la descrizione di alcuni motori di ricerca popolari). Le query vengono registrate insieme ai dati dell’utente per personalizzare i contenuti e servire pubblicità. Oppure, i dati di tutti gli utenti vengono messi insieme per capire come e dove migliorare le prestazioni dei motori di ricerca.
I log degli utenti contengono le query precedenti, la pagina dei risultati e le informazioni su ciò che ha funzionato – cosa ha cliccato l’utente e cosa ha speso tempo a leggere. Grazie ai log degli utenti, ogni query può essere abbinata a documenti rilevanti (l’utente clicca, legge e chiude la sessione) e a documenti non rilevanti (l’utente non ha cliccato o non ha letto o ha cercato di riformulare la query)2.
Con questi log, ogni nuova query può essere abbinata a una query passata simile. Un modo per capire se una query è simile a un’altra è vedere se la classificazione produce gli stessi documenti: le query simili possono non contenere sempre le stesse parole, ma è probabile che i risultati siano identici2.
Gli errori ortografici possono essere corretti utilizzando query simili. È possibile aggiungere nuove parole chiave e sinonimi per ampliare la query. A tale scopo, è necessario esaminare altre parole che ricorrono frequentemente nei documenti rilevanti del passato. In generale, tuttavia, le parole che ricorrono più frequentemente nei documenti rilevanti rispetto a quelli non rilevanti vengono aggiunte alla query o ricevono un peso aggiuntivo2.
Fase 5: classificazione dei documenti rilevanti
Ogni documento viene valutato per la sua rilevanza e classificato in base a questo punteggio. Per rilevanza si intende sia la rilevanza dell’argomento, ossia la corrispondenza tra i termini dell’indice di un documento e quelli della query, sia la rilevanza dell’utente, ossia la corrispondenza tra il documento e le preferenze dell’utente. Una parte del punteggio dei documenti può essere effettuata durante l’indicizzazione. La velocità del motore di ricerca dipende dalla qualità degli indici. La sua efficacia si basa sulla corrispondenza tra la query e il documento e sul sistema di classificazione2.
 La rilevanza degli utenti viene misurata creando modelli di utenti (o tipi di personalità) basati sui termini di ricerca precedenti, sui siti visitati, sui messaggi e-mail, sul dispositivo utilizzato, sulla lingua e sulla posizione geografica. I Cookies sono utilizzati per memorizzare le preferenze dell’utente. Alcuni motori di ricerca acquistano informazioni sugli utenti anche da terzi (fate riferimento alla descrizione di alcuni motori di ricerca). Se una persona è interessata al calcio, i suoi risultati per “Manchester” saranno diversi da quelli di una persona che ha appena prenotato un volo per Londra. Le parole che ricorrono frequentemente nei documenti associati a una persona avranno la massima importanza.
La rilevanza degli utenti viene misurata creando modelli di utenti (o tipi di personalità) basati sui termini di ricerca precedenti, sui siti visitati, sui messaggi e-mail, sul dispositivo utilizzato, sulla lingua e sulla posizione geografica. I Cookies sono utilizzati per memorizzare le preferenze dell’utente. Alcuni motori di ricerca acquistano informazioni sugli utenti anche da terzi (fate riferimento alla descrizione di alcuni motori di ricerca). Se una persona è interessata al calcio, i suoi risultati per “Manchester” saranno diversi da quelli di una persona che ha appena prenotato un volo per Londra. Le parole che ricorrono frequentemente nei documenti associati a una persona avranno la massima importanza.
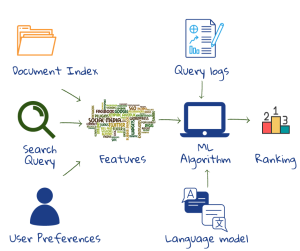
I motori di ricerca web commerciali incorporano centinaia di caratteristiche nei loro algoritmi di classificazione, molte delle quali derivano dall’enorme raccolta di dati sulle interazioni degli utenti nei log delle query. Una funzione di ranking combina le caratteristiche del documento, della query e della rilevanza dell’utente. Qualunque sia la funzione di ranking utilizzata, deve avere una solida base matematica. L’output è la probabilità che un documento soddisfi il bisogno informativo dell’utente. Al di sopra di una certa probabilità di rilevanza, il documento viene classificato come rilevante2.
L’apprendimento automatico viene utilizzato per imparare il ranking sulla base del feedback implicito dell’utente nei log (ciò che ha funzionato nelle query precedenti). L’apprendimento automatico è stato utilizzato anche per sviluppare modelli sofisticati di come gli esseri umani utilizzano il linguaggio per decifrare le query1,2.
I progressi nella ricerca sul Web sono stati fenomenali nell’ultimo decennio. Tuttavia, quando si tratta di comprendere il contesto di una specifica query, non è possibile sostituire l’utente nel fornire una query migliore. In genere, le query migliori derivano dall’esame dei risultati da parte degli utenti e dalla riformulazione della query2.
Fase 6: Visualizzazione dei risultati

Infine, i risultati sono pronti per essere visualizzati. Il titolo e l’url della pagina sono visualizzati, con i termini di ricerca in grassetto. Dopo ogni link viene generato e visualizzato un breve sommario. Il sommario evidenzia i passaggi importanti del documento. A tale scopo, vengono utilizzate frasi tratte dai titoli, dalla descrizione dei metadati o dal testo che corrisponde meglio alla query. Se tutti i termini della query sono presenti nel titolo, non vengono ripetuti nello snippet2. Le frasi vengono selezionate anche in base alla loro leggibilità.
Ai risultati viene aggiunta una pubblicità appropriata. La pubblicità è il modo in cui la maggior parte dei motori di ricerca genera entrate. In alcuni motori di ricerca sono chiaramente indicati come contenuti sponsorizzati, mentre in altri non lo sono. Poiché molti utenti guardano solo i primi risultati, gli annunci cambiano sostanzialmente l’intero processo.
Gli annunci vengono scelti in base al contesto della richiesta e al modello dell’utente. Le aziende produttrici di motori di ricerca mantengono un database di annunci pubblicitari che viene consultato per trovare gli annunci più rilevanti per una determinata query. Gli inserzionisti fanno offerte per parole chiave che descrivono argomenti associati ai loro prodotti. Sia l’importo dell’offerta che la popolarità di un annuncio sono fattori significativi nel processo di selezione2.
Per le domande sui fatti, alcuni motori utilizzano la propria raccolta di fatti. La Knowledge Vault di Google contiene oltre un miliardo di fatti indicizzati da diverse fonti3. I risultati vengono raggruppati da algoritmi di apprendimento automatico in gruppi appropriati. Infine, all’utente vengono presentate anche delle alternative alla query, per vedere se si adattano meglio alle sue reali esigenze.
Alcuni riferimenti:
L’origine di Google si trova nell’articolo orginiale di Brin and Paige
Alcuni dei calcoli che stanno alla base del Pagerank si trovano su Wiki’s PageRank
Per gli amanti della matematica, una bella spiegazione del Pagerank
1 Russell, D., What Do You Need to Know to Use a Search Engine? Why We Still Need to Teach Research Skills, AI Magazine, 36(4), 2015.
2 Croft, B., Metzler D., Strohman, T., Search Engines, Information Retrieval in Practice, 2015.
3 Spencer, S., Google Power Search: The Essential Guide to Finding Anything Online With Google, Koshkonong, Kindle Edition.
