Ascoltare, parlare e scrivere
29 Parola all’IA: le reti neurali profonde
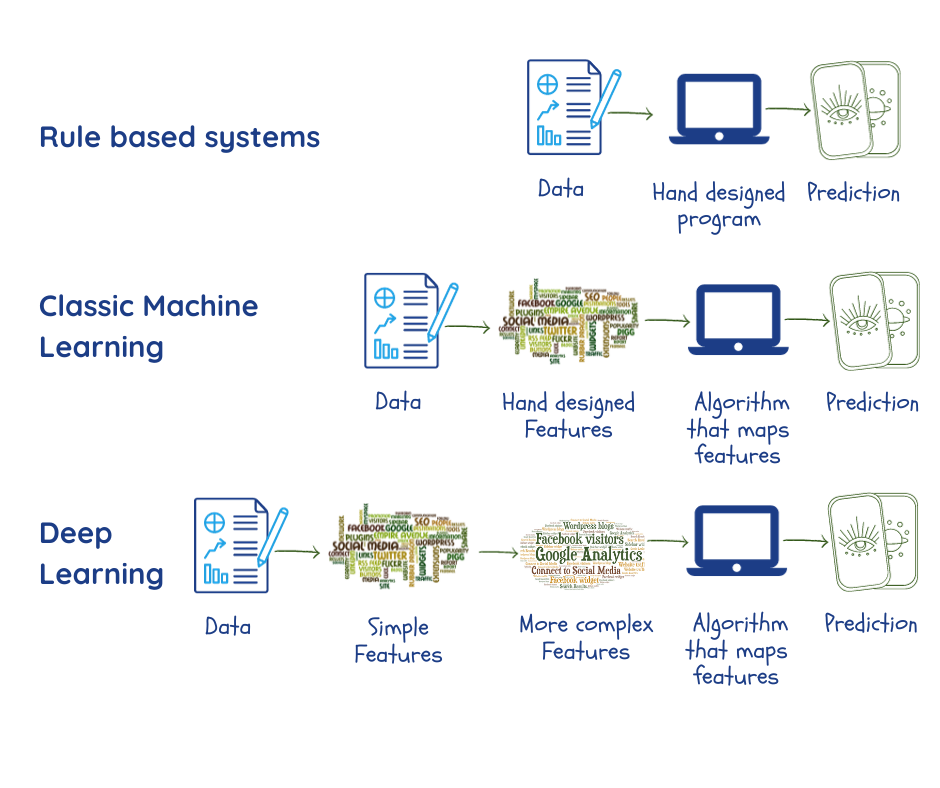
L’apprendimento automatico scende nel profondo
La conoscenza umana è ampia e mutevole ed è intrinsecamente difficile da cogliere. La mente umana può assorbire ed elaborare conoscenza dal momento che è, come ha sostenuto Noam Chomsky: «un sistema sorprendentemente efficiente e persino elegante che funziona con piccoli quantitativi di informazioni; cerca di non evincere correlazioni irrazionali tra i punti di dati, ma di creare spiegazioni»1.
Si presume che l’apprendimento automatico faccia la stessa cosa rinvenendo schemi in vasti quantitativi di dati. Ma, prima di fare ciò, esperti e programmatori devono sedersi e codificare quali caratteristiche dei dati abbiano rilevanza per il problema considerato e inserirle nella macchina come “parametri”2,3. Come abbiamo visto precedentemente, le prestazioni del sistema dipendono notevolmente dalla qualità dei dati e da questi parametri, ai quali non è sempre immediato risalire.
Le reti neurali profonde, denominate anche apprendimento profondo, sono una branca dell’apprendimento automatico pensata per superare questo inconveniente:
- estraendo propri parametri dai dati durante la fase di addestramento;
- facendo ricorso a molteplici strati che creano relazioni tra parametri, le quali vanno progressivamente da rappresentazioni semplici nello strato più esterno a rappresentazioni più complesse e astratte e ciò consente di fare alcune cose meglio che con i convenzionali algoritmi di apprendimento automatico2.
Moltissime applicazioni potenti di apprendimento automatico fanno sempre maggiore ricorso all’apprendimento profondo. Tra esse vi sono i motori di ricerca, i sistemi di raccomandazione, le funzioni di trascrizione vocale e di traduzione che abbiamo trattato in questo libro. Non sarà una forzatura affermare che l’apprendimento profondo ha dato una notevole spinta al successo dell’intelligenza artificiale in molteplici attività.
Il termine “profondo” fa riferimento a come gli strati si sovrappongono in modo da creare la rete. Il termine “neurale” riflette il fatto che alcuni aspetti della progettazione sono stati ispirati al cervello umano inteso da un punto di vista biologico. Nonostante ciò, e anche se forniscono delle informazioni relativamente ai nostri processi di pensiero, si tratta di modelli rigorosamente matematici privi di somiglianza con parti o processi biologici2.
I principi fondamentali dell’apprendimento profondo
Quando gli esseri umani guardano un’immagine, identificano automaticamente oggetti e volti. Ma una fotografia per un algoritmo è solo un insieme di pixel. Passare da un coacervo di colori e livelli di luminosità a riconoscere un viso è un salto troppo complicato da fare.
L’apprendimento profondo ci arriva scomponendo il processo in rappresentazioni molto semplici nel primo strato, attraverso, per esempio, la comparazione della luminosità dei pixel adiacenti in modo da notare la presenza o l’assenza di margini in diverse zone dell’immagine. Il secondo strato individua serie di margini per cercare entità più complesse, come angoli e contorni, ignorando delle variazioni trascurabili nelle posizioni dei margini2,3. Lo strato successivo cerca parti degli oggetti tenendo conto di contorni e angoli. Lentamente aumenta la complessità fino a giungere al punto in cui l’ultimo strato è in grado di combinare parti diverse sufficientemente bene da riconoscere un viso o identificare un oggetto.
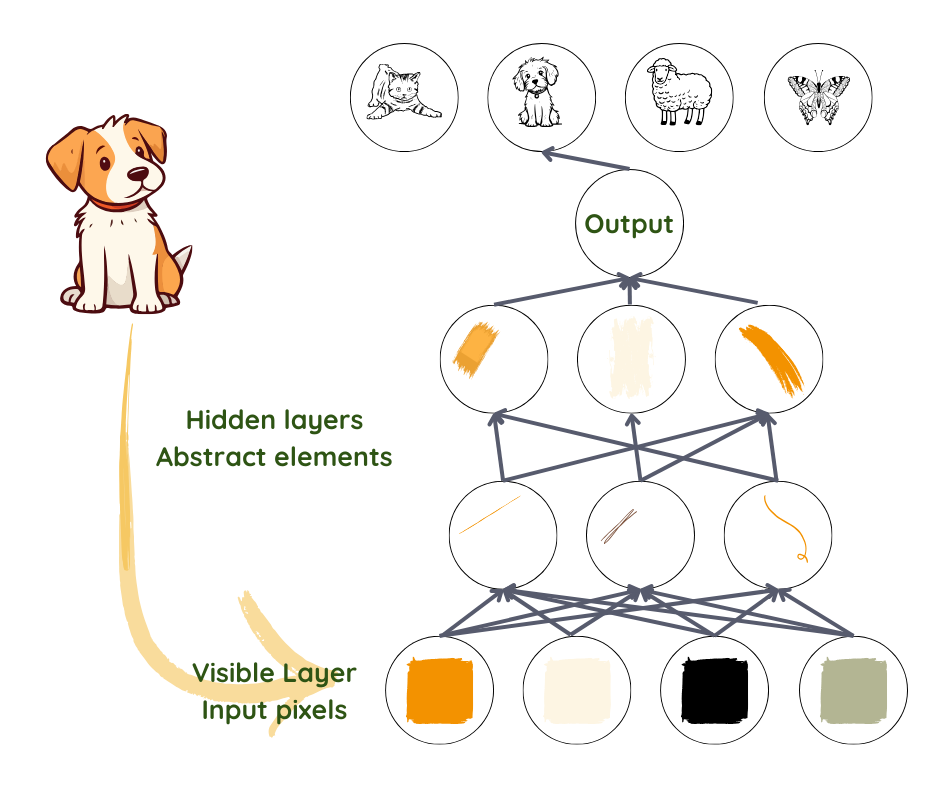
Cosa bisogna prendere in considerazione in ciascuno strato non è specificato dai programmatori, ma si apprende dai dati nel processo di addestramento3. Testando queste previsioni alla luce dei risultati reali nelle serie di dati di addestramento, il funzionamento di ciascuno strato è calibrato in un modo leggermente diverso per ottenere un risultato leggermente migliore ogni volta. Quando ciò viene fatto correttamente e purché ci sia un numero sufficiente di dati di buona qualità, la rete dovrebbe evolvere in modo da ignorare le parti irrilevanti della foto, come la posizione esatta delle entità, le angolazioni, l’illuminazione e focalizzarsi su quelle parti che rendono il riconoscimento possibile.
Una cosa da notare in questo punto è il fatto che, nonostante il nostro utilizzo di margini e contorni per comprendere il processo, ciò che è effettivamente rappresentato negli strati è una serie di numeri, che potrebbe corrispondere o meno alle cose che comprendiamo. Ciò che non cambia sono l’astrattezza e la complessità crescenti.
Progettare la rete
Quando il programmatore decide di fare uso dell’apprendimento profondo per un’attività e prepara i dati, deve progettare ciò che viene definito l’architettura della propria rete neurale. Deve scegliere il numero di strati (la profondità della rete) e il numero di parametri per strato (l’ampiezza della rete). Successivamente deve decidere come creare delle connessioni tra gli strati, se ogni unità di uno strato sarà collegata a ogni unità dello strato precedente o meno.
L’architettura ideale per una determinata attività spesso viene rinvenuta attraverso la sperimentazione. Maggiore è il numero degli strati, minore è quello dei parametri che sono necessari per ogni strato e la rete funziona meglio con dei dati generali, a costo di essere difficile da ottimizzare. Un minor numero di connessioni significherà un minor numero di parametri e una quantità minore di calcoli, ma ridurrà la flessibilità della rete2.
Addestrare la rete
Consideriamo l’esempio di una rete neurale di tipo “feed forward” per l’apprendimento supervisionato. In questo caso, le informazioni fluiscono da uno strato a quello più profondo senza cicli di feedback. Come accade nel caso di tutte le tecniche di apprendimento automatico, l’obiettivo è trovare come gli input siano collegati con gli output, quali parametri si combinano e come si combinano per fornire il risultato osservato: presumiamo che vi sia una relazione f che collega i valori di ingresso x a quelli di uscita y. Utilizziamo poi la rete per trovare la serie di parametri θ che dà la combinazione migliore per ottenere gli output previsti e quelli effettivi.
Domanda chiave: il valore previsto y è f (x,θ), per quale θ?
In questo caso l’y previsto è il prodotto finale e la serie di dati x è l’input. Nel campo del riconoscimento facciale, x è di solito l’insieme dei pixel all’interno di un’immagine. y può essere il nome della persona. Nella rete, gli strati sono assimilabili ai lavoratori in una catena di montaggio nella quale ciascun lavoratore lavora al pezzo che gli è assegnato e lo passa avanti al lavoratore successivo. Il primo strato riceve l’input e lo trasforma un po’ prima di passarlo al secondo nella successione. Il secondo strato fa lo stesso prima di passarlo al terzo e via di questo passo fino a che l’input viene trasformato nel prodotto finale.
Matematicamente, la funzione f è suddivisa in svariate funzioni f1, f2, f3… in cui f= ….f3(f2(f1(x))). Lo strato successivo a quello di ingresso trasforma i parametri di ingresso utilizzando f1, lo strato ancora successivo lo fa utilizzando f2 e così via. Il programmatore potrebbe intervenire per aiutare a scegliere la famiglia di funzioni corretta in base alla propria conoscenza del problema.

È compito di ciascuno strato assegnare il livello di importanza, il peso conferito a ciascun parametro che riceve. Tali pesi sono come delle manopole che in ultima analisi definiscono la relazione tra l’output previsto e l’input in quello strato3. In un sistema di apprendimento profondo tipico, consideriamo centinaia di milioni di queste manopole e centinaia di milioni di esempi di addestramento. Dal momento che né definiamo né possiamo vedere output e pesi negli strati tra l’input e l’output, questi sono definiti strati nascosti.
Nel caso dell’esempio del riconoscimento dell’oggetto discusso precedentemente, è compito del primo lavoratore individuare i margini e passarli al secondo che individua i contorni e così via.
Durante l’addestramento, l’output previsto viene considerato e paragonato all’output reale. Se la differenza tra i due è considerevole, i pesi assegnati in ciascuno strato dovranno essere modificati notevolmente. In caso contrario sarà sufficiente una variazione lieve. Questa attività avviene in due momenti. In primo luogo si calcola la differenza tra la previsione e l’output e poi un altro algoritmo calcola come modificare i pesi in ciascuno strato, iniziando dallo strato di uscita (in questo caso, le informazioni fluiscono risalendo dagli strati più profondi). Pertanto al termine del processo di addestramento, la rete è pronta con i suoi pesi e le sue funzioni ad attaccare i dati di test. Il resto del processo è il medesimo di quello dell’apprendimento automatico convenzionale.
1 Chomsky, N., Roberts, I., Watumull, J., Noam Chomsky: The False Promise of ChatGPT, The New York Times, 2023.
2 Goodfellow, I.J., Bengio, Y., Courville, A., Deep Learning, MIT Press, 2016.
3 LeCun, Y., Bengio, Y., Hinton, G., Deep learning, Nature 521, 436–444 (2015).
