Gestire l’apprendimento
19 Problemi con i dati: pregiudizi e imparzialità
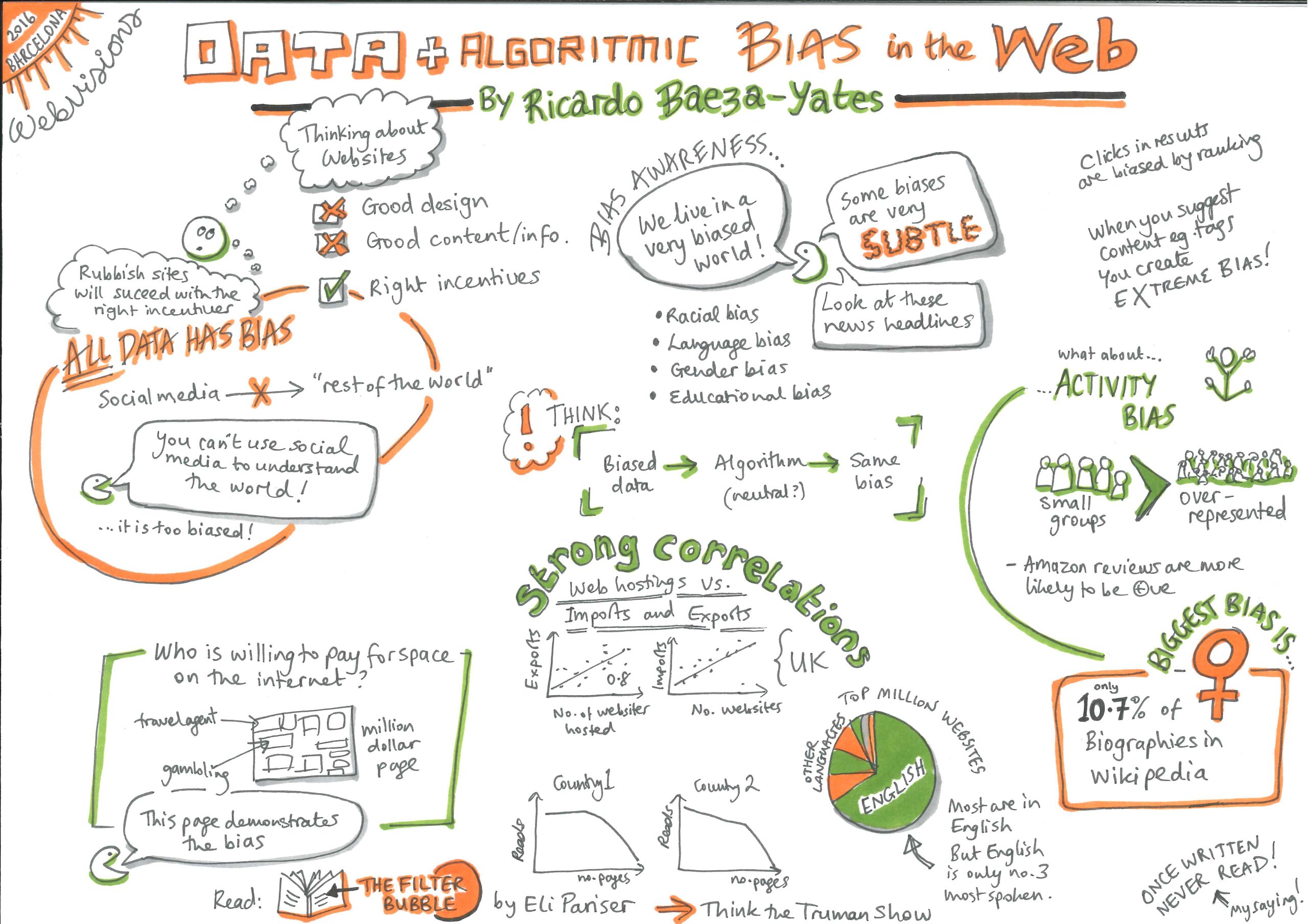
Un bias è un pregiudizio nei confronti di un’identità o una dimostrazione di avversione verso di essa, in positivo o in negativo, intenzionalmente o meno1. L’imparzialità è il contrario del pregiudizio e qualcosa in più: è trattare chiunque correttamente indipendentemente dalla sua identità e dalla sua situazione. Per avere la certezza che ognuno sia trattato con equanimità e viga un accesso paritario alle opportunità devono essere impostati e rispettati dei processi chiari1.
Sistemi basati sull’agire umano spesso manifestano una notevole dose di pregiudizio e discriminazione dal momento che ciascun individuo ha un proprio esclusivo insieme di opinioni e di pregiudizi. Anch’essi sono delle black box le cui decisioni, come il modo in cui valutano i fogli di risposta, possono rivelarsi difficili da comprendere. Abbiamo però sviluppato delle strategie e creato delle strutture per prestare attenzione a queste pratiche e metterle in discussione.
Talvolta si pubblicizzano i sistemi automatizzati come la panacea alla soggettività umana: gli algoritmi sono basati su numeri, come possono avere dei pregiudizi? Degli algoritmi basati, tra le altre cose, su dati poco affidabili, possono non solo raccogliere e apprendere dei pregiudizi esistenti concernenti genere, razza, cultura o disabilità, ma addirittura amplificarli1,2,3. A peggiorare la situazione, anche se essi non sono bloccati in sistemi chiusi e proprietari, non possono essere interrogati per spiegare le proprie azioni per via di una intrinseca mancanza di spiegabilità propria di alcuni sistemi come quelli basati sulle reti neurali profonde.
Esempi di pregiudizi interessanti i sistemi che applicano l’IA all’istruzione
- Quando i programmatori codificano dei sistemi basati su regole, possono inserire pregiudizi e stereotipi personali all’interno del sistema1.
- Un algoritmo basato su dati può concludere di non proporre un percorso di carriera in ambito STEM per ragazze per via del fatto che le studentesse appaiono in numero minore negli insiemi di dati relativi ai laureati in materie STEM. Il fatto che vi siano meno donne matematiche è dovuto a stereotipi e norme sociali esistenti o è dovuto ad alcune proprietà intrinseche all’appartenenza al sesso femminile? Gli algoritmi non hanno la capacità di distinguere tra le due situazioni. Dal momento che i dati esistenti riflettono degli stereotipi esistenti, gli algoritmi addestrati su di essi replicano delle disuguglianze e delle dinamiche sociali esistenti4. Inoltre, se si adottassero tali raccomandazioni, più ragazze sceglierebbero di studiare materie non-STEM e i nuovi dati lo rifletterebbero, si verificherebbe un caso di una profezia che si autoavvera3.
- Gli studenti appartenenti a una cultura sottorappresentata nelle serie di dati di addestramento potrebbero avere schemi comportamentali e modi differenti per mostrare la propria motivazione. Come calcolerebbe i parametri inerenti a loro un’analisi dell’apprendimento? Se i dati non sono rappresentativi di tutte le categorie di studenti, i sistemi addestrati su questi dati potrebbero penalizzare la minoranza le cui tendenze comportamentali non sono ciò che il programma era stato ottimizzato a premiare. Se non siamo attenti, gli algoritmi di apprendimento generalizzeranno basandosi sulla cultura maggioritaria, portando a elevate percentuali di errore per quanto concerne i gruppi minoritari4,5. Decisioni di tal genere potrebbero scoraggiare quanti potrebbero apportare diversità, creatività e doti uniche e quanti hanno esperienze, interessi e motivazioni diversi2.
- Uno studente di origine britannica giudicato da un software di correzione temi statunitense sarebbe penalizzato per via di quelli che verrebbero considerati errori di ortografia. La lingua locale, variazioni di ortografia e accento, la geografia e la cultura locali saranno sempre un’insidia per sistemi ideati e addestrati per altri Paesi e altri contesti.
- Alcuni insegnanti penalizzano delle frasi comuni a una categoria o a una zona, consciamente o per via di associazioni sociali viziate da pregiudizi. Se un software per la valutazione di temi si forma su temi valutati da questi insegnanti applicherà i medesimi pregiudizi.
- I sistemi di apprendimento automatico necessitano di un target variabile e di valori indicativi per essere ottimizzati. Supponiamo che dei risultati di test della scuola secondaria siano stati utilizzati come valori indicativi dei meriti accademici. I sistemi ora saranno addestrati esclusivamente per migliorare schemi compatibili con studenti che ottengono buoni risultati in situazioni di stress e nei ristretti contesti delle aule d’esame. Saranno i risultati dei test, e non le conoscenze complessive, che questi sistemi cercheranno di ottimizzare consigliando risorse ed esercizi agli studenti. Anche se ciò potrebbe valere in molte aule al momento, l’approccio tradizionale rende almeno possibile formulare molteplici obiettivi4.
- I sistemi di apprendimento adattivo suggeriscono agli studenti delle risorse per porre rimedio a lacune nelle competenze o nelle conoscenze. Se queste risorse devono essere acquistate o necessitano di una connessione domestica a Internet, ciò non è corretto nei confronti di quegli studenti che non hanno gli strumenti per mettere in pratica i consigli. «Quando un algoritmo dà degli spunti, suggerisce passi successivi o risorse a uno studente, dobbiamo verificare se l’aiuto fornito non è imparziale dal momento che un gruppo sistematicamente non ottiene un aiuto utile, cosa che costituisce una discriminazione»2.
- Il concetto di personalizzazione dell’istruzione conformemente all’attuale livello di conoscenze e ai gusti del momento di uno studente potrebbe in sé costituire un pregiudizio1. Non stiamo forse anche impedendo a questo studente di esplorare nuovi interessi e nuove alternative? Il nostro approccio lo renderebbe monodimensionale, riducendone competenze e conoscenze complessive e l’accesso alle opportunità?
Cosa possono fare gli insegnanti per ridurre gli effetti prodotti dai pregiudizi insiti nell’IA applicata all’istruzione?
I ricercatori stanno costantemente proponendo e analizzando modi diversi per ridurre i pregiudizi. Non tutti i metodi però sono semplici da applicare. Oltre a ciò, l’imparzialità è qualcosa di molto più complesso della mitigazione dei pregiudizi.
Per esempio, se i dati esistenti sono pieni di stereotipi, «abbiamo l’obbligo di mettere in discussione i dati e di programmare i nostri sistemi in modo che si conformino direttamente a un concetto di comportamento equo, indipendentemente dal fatto se ciò sia supportato o meno dai dati di cui attualmente disponiamo?»4. I metodi sono sempre confliggenti e contrapposti e alcuni interventi messi in atto per arginare un tipo di pregiudizio ne possono generare un altro!
Dunque, cosa possono fare gli insegnanti?
- Porre domande alle società venditrici: prima di adottare un sistema AIED, chiedere quali tipi di insiemi di dati sono stati usati per addestrare il sistema, dove, da chi e per chi il sistema è stato concepito e ideato e come è stato valutato.
- Non accettare passivamente i parametri che vengono loro venduti. Una precisione complessiva del, diciamo, “5% di errore” potrebbe celare il fatto che un modello funziona malissimo per un gruppo minoritario4.
- Leggere la documentazione: quali misure sono state assunte per rilevare e contrastare i pregiudizi e agire in modo imparziale1?
- Ottenere informazioni sugli sviluppatori: sono unicamente degli esperti di informatica oppure anche dei ricercatori nel campo della didattica e degli insegnanti sono stati coinvolti in tutte le fasi del processo? Il sistema si basa unicamente sull’apprendimento automatico o vi sono state integrate teorie e pratiche di apprendimento2?
- Preferire modelli di apprendimento trasparenti e aperti che conferiscono la facoltà di ignorare delle decisioni2: molti modelli di IA applicata all’istruzione hanno una struttura flessibile, in cui il docente, o anche il discente, può controllare la decisione della macchina, chiedere spiegazioni in proposito oppure ignorarla totalmente.
- Verificare l’accessibilità del prodotto: è accessibile da chiunque allo stesso modo, soprattutto per i discenti con disabilità o particolari esigenze didattiche1?
- Fare attenzione agli effetti prodotti, tanto a lungo quanto a breve termine, dall’uso di una tecnologia sui propri studenti e in classe ed essere pronti a offrire assistenza quando necessario.
Nonostante questi problemi legati alla tecnologia basata sull’IA, ci sono ragioni per essere ottimisti riguardo al futuro del suo impiego nel settore dell’istruzione:
- con l’aumento della consapevolezza relativa a questi temi, si sono fatte ricerche sui metodi per individuare e correggere i pregiudizi e si sono sperimentati questi metodi.
- I sistemi basati sulle regole e quelli basati sui dati con un certo grado di spiegabilità fanno emergere pregiudizi nascosti nelle prassi didattiche esistenti. Facendoci esprimere i nostri pensieri e spiegare i nostri processi, ci costringono a ricontrollare i fondamenti da cui siamo partiti e a fare piazza pulita.
- Grazie al potenziale di personalizzazone dei sistemi di IA, possiamo attagliare molti aspetti della didattica. Le risorse potrebbero essere rese funzionali alle conoscenze e alle esperienze di ogni studente. Esse potrebbero potenzialmente integrare le comunità e il patrimonio culturale locali e soddisfare delle specifiche esigenze a livello locale2.
1 Ethical guidelines on the use of artificial intelligence and data in teaching and learning for educators, European Commission, October 2022.
2 U.S. Department of Education, Office of Educational Technology, Artificial Intelligence and Future of Teaching and Learning: Insights and Recommendations, Washington, DC, 2023.
3 Kelleher, J.D, Tierney, B, Data Science, MIT Press, London, 2018.
4 Barocas, S., Hardt, M., Narayanan, A., Fairness and machine learning Limitations and Opportunities, 2022.
5 Milano, S., Taddeo, M., Floridi, L., Recommender systems and their ethical challenges, AI & Soc 35, 957–967, 2020.
