Iskanje informacij
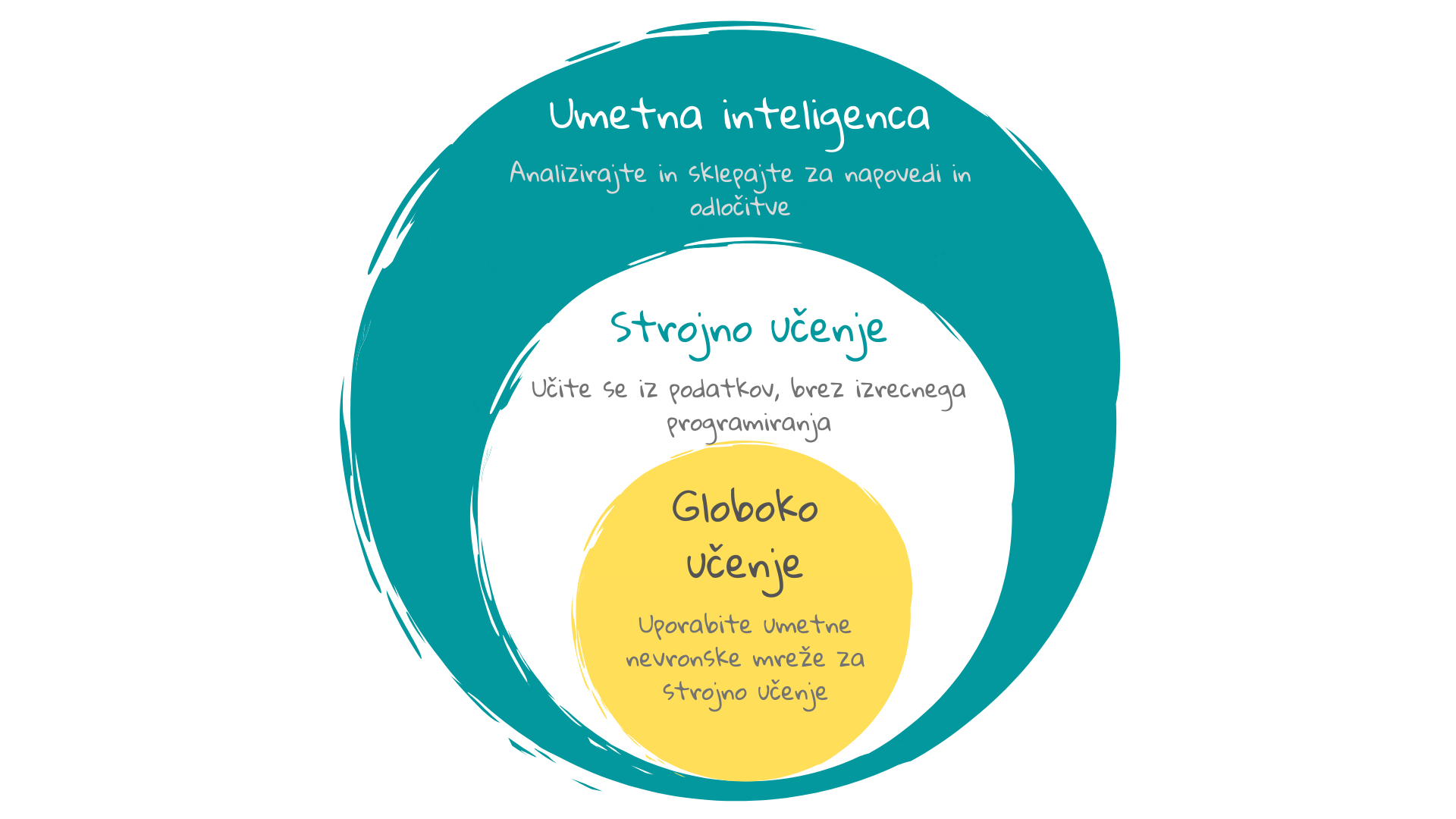
9 Govorica UI: Strojno učenje
Algoritem je določeno zaporedje navodil za izvedbo naloge. Nalogo razdeli na preproste, lahko razumljive korake, kot dobro napisan recept.
Programski jeziki so jeziki, ki jim računalnik lahko sledi in jih izvaja. Delujejo kot most med tem, kar razumemo, in tem, kar lahko razume stroj; so kot stikala za vklop in izklop. Računalnik slike, videoposnetke in navodila razume kot enice (stikalo je vklopljeno) in ničle (stikalo je izklopljeno).
Algoritem, zapisan v programskem jeziku, postane program. Aplikacije so programi, napisani za končnega uporabnika.
Tradicionalni programi sprejemajo podatke in sledijo navodilom, da dobijo rezultat. Številni zgodnji programi UI so bili v tem pogledu tradicionalni. Ker se navodila ne morejo prilagajati podatkom, ti programi niso bili prav uspešni pri nalogah, kot je npr. napovedovanje na podlagi nepopolnih informacij in naravna obdelava jezika (NLP).
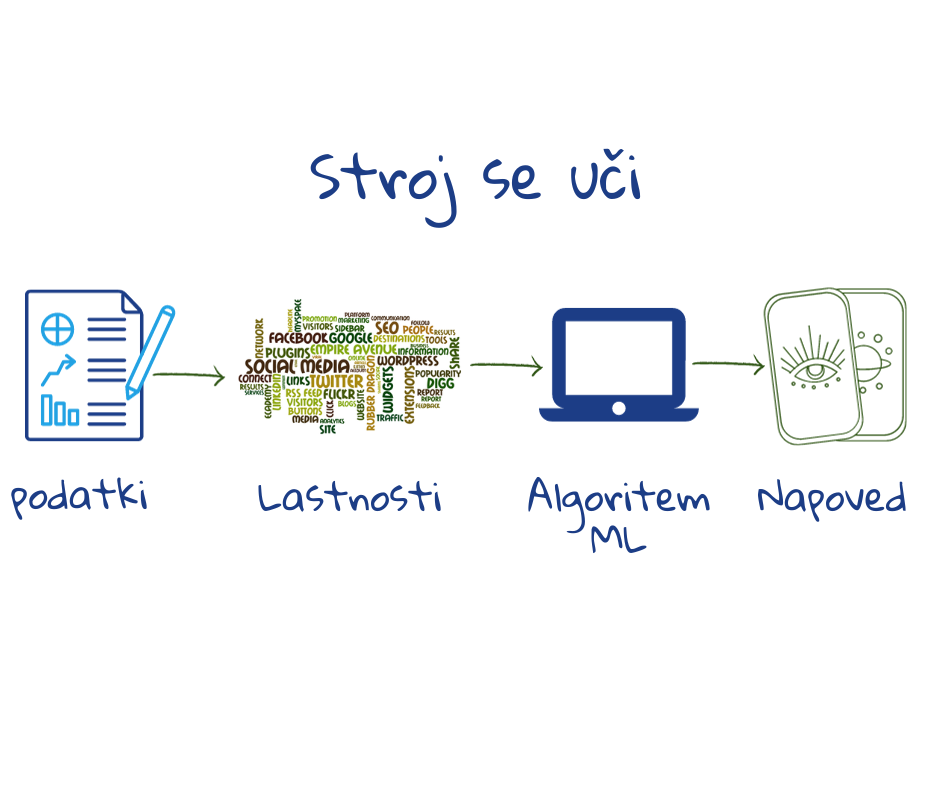
 Spletne iskalnike poganjajo klasični algoritmi in algoritmi strojnega učenja. Za razliko od prvih slednji analizirajo podatke za prepoznavanje vzorcev, ki jih nato uporabijo za sprejemanje odločitev ali generiranje napovedi. Lahko bi reklii, da na podlagi podatkov (dobrih in slabih primerov) ustvarijo svoj lasten “recept” za delovanje.
Spletne iskalnike poganjajo klasični algoritmi in algoritmi strojnega učenja. Za razliko od prvih slednji analizirajo podatke za prepoznavanje vzorcev, ki jih nato uporabijo za sprejemanje odločitev ali generiranje napovedi. Lahko bi reklii, da na podlagi podatkov (dobrih in slabih primerov) ustvarijo svoj lasten “recept” za delovanje.
Takšni algoritmi so primerni za zelo kompleksne situacije z veliko manjkajočimi podatki. Sposobni so sami spremljajati izvajanje zadanih nalog in povratne informacije uporabiti za izboljšanje svojega delovanja.
V tem so pravzaprav podobni ljudem, zlasti dojenčkom, ki se veščin učijo izven izobraževalnega sistema. Dojenčki opazujejo, ponavljajo (posnemajo), se učijo, preizkušajo naučeno in se izboljšujejo. Če je treba, tudi improvizirajo.
Vendar je podobnost med stroji in ljudmi precej površinska. Učenje ljudi je drugačno, veliko bolj diferencirano, podrobno in zapleteno kot učenje strojev.
Problem klasifikacije
Ena od pogostih nalog, ki se uporablja v aplikacijah strojnega učenja, je klasifikacija. Je na fotografiji pes ali mačka? Ali ima učenec težave pri reševanju nalog, ali je opravil preizkus znanja? Stroj ima na izbiro dve ali več skupin. Aplikacija mora nove podatke razvrstiti v eno od teh skupin.

Vzemimo za primer komplet igralnih kart, ki ga po nekem ključu razdelimo na dva kupčka, skupino A in skupino B. Nalsednjo karto (karov as) moramo razvrstiti v skupino A ali skupino B.
Najprej moramo razumeti, po kašnem ključu je razdeljen komplet kart – torej potrebujemo primere. Izberemo štiri karte iz skupine A in štiri iz skupine B. Teh osem primerov predstavlja naše učne podatke – podatke, ki nam pomagajo prepoznati vzorec, oz., nas s tem “učijo”, kako priti do rezultata.
Takoj ko vidimo razporeditev (slika desno), nas večina ugane, da karov as spada v skupino B. Pri tem ne potrebujemo posebnih navodil, človeški možgani so čudežni iskalec vzorcev. Kako pa bi to nalogo opravil stroj?
Algoritmi strojnega učenja temeljijo na uveljavljenih statističnih teorijah. Različni algoritmi temeljijo na različnih matematičnih enačbah, ki jih je treba skrbno izbrati, da ustrezajo dani nalogi. Naloga programerja je, da izbere podatke, analizira, katere značilnosti podatkov so pomembne za določen problem, in izbere pravilen algoritem.
Pomen podatkov

Vendar pa bi lahko v zgornjem primeru šlo narobe več stvari. Oglejte si sliko. V skupini 1 je premalo kart, da bi lahko ugibali. V skupini 2 je sicer več kart, vendar so vse enake barve, zato ne moremo predvideti, kam uvrstiti karo. Če skupine ne bi bile enako velike, bi v skupini 3 karte s številkami spadale v skupino A, karte s podobami pa v skupino B.
Problemi strojnega učenja so običajno bolj odprti in vključujejo nabore podatkov, veliko večje od kompleta kart. Učne podatke je treba izbrati s pomočjo statistične analize, sicer se vanje prikradejo napake. Dobra izbira podatkov je ključnega pomena za učinkovite aplikacije strojenga učenja, bolj kot pri drugih vrstah programov. Strojno učenje potrebuje veliko število relevantnih podatkov. Osnovni model strojnega učenja mora vsebovati najmanj desetkrat več podatkov, kot je skupno število značilnosti1. Kljub temu je strojno učenje posebej primerno tudi za obdelavo hrupnih, neurejenih in nasprotujočih si podatkov.
Ekstrakcija značilnosti
Ko ste si v zgornjem primeru ogledali skupini A in B, ste bržkone najprej opazili barvo kart. Nato številko ali črko in barvo. Pri algoritmih je treba vse te posamezne značilnosti vnesti posebej. Algoritem ne more samodejno vedeti, kaj je pomembno za dano nalogo.
Pri izbiri značilnosti si morajo programerji zastaviti številna vprašanja. Koliko značilnosti je premalo, da bi bile uporabne? Koliko jih je preveč? Katere značilnosti so pomembne za nalogo? Kakšno je razmerje med izbranimi značilnostmi – ali je ena značilnost odvisna od druge? Ali je z izbranimi značilnostmi mogoče doseči natančen rezultat?
Postopek
Ko programer ustvarja aplikacijo, vzame podatke, iz njih ekstrahira značilnosti, izbere ustrezen algoritem strojnega učenja (matematična funkcija, ki določa postopek) in ga usposobi z uporabo označenih podatkov (v primeru, ko je izhod znan – npr. skupina A ali skupina B), tako da stroj razume vzorec, ki se skriva za problemom.
Za stroj razumevanje pomeni zapis v oblik niza številk ali uteži, ki jih dodeli vsaki značilnosti. S pravilno dodelitvijo uteži lahko izračuna verjetnost, da nova karta spada v skupino A ali B. Običajno v fazi učenja programer pomaga stroju tako, da ročno spremeni nekatere vrednosti (uglaševanje). Za tem je treba program pred začetkom uporabe preizkusiti. Pri tem se vanj vnesejo takšni označeni podatki, ki niso bili uporabljeni v fazi učenja, imenujemo jih testni podatki.
Nato se oceni učinkovitost stroja pri napovedovanju rezultatov. Ko učinkovitost doseže zadovoljivo stopnjo, lahko začnemo z uporabo programa, ki je sedaj pripravljen za vnos povsem novih podatkov, na podlagi katerih sprejema odločitve ali generira napovedi.
Algoritem nato lastno delovanje v realnem času nenehno spremlja in se izboljšuje (prilagoditev uteži za boljše rezultate). Učinkovitost delovanja v realnem času se pogosto razlikuje od izmerjene učinkovitosti v fazi preizkušanja (testiranja). Ker je eksperimentiranje z resničnimi uporabniki drago, zahteva veliko truda in pogosto s seboj prinaša določeno tveganje, se algoritmi praviloma preizkušajo na podlagi preteklih uporabniških podatkov, zaradi česar pa morda ni možno oceniti vpliva na vedenje uporabnikov1 . Zato je pomembno, da se pred uporabo aplikacij strojnega učenja opravi celovita ocena njihovega delovanja:
Ali bi radi strojno učenje preizkusili v praksi? Oglejte si to aktivnost.
1 Theobald, O. Machine Learning For Absolute Beginners: A Plain English Introduction (Second Edition) (Machine Learning From Scratch Book 1) (p. 24). Scatterplot Press. Kindle Edition.
2 Konstan, J., Terveen, L., Human-centered recommender systems: Origins, advances, challenges, and opportunities, AI Magazine, 42(3), 31-42, 2021.

.jpg){kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}