Iskanje informacij
11 Govorica UI: Razvrščanje
V primerjavi z iskalniki iz začetka tisočletja današnji iskalniki opravljajo veliko podrobnejše in globlje analize. To pomeni, na primer, da ne le štejejo besede v besedilu, temveč analizirajo in primerjajo pomen besed1. Veliko takšnih procesov poteka v postopku razvrščanja:
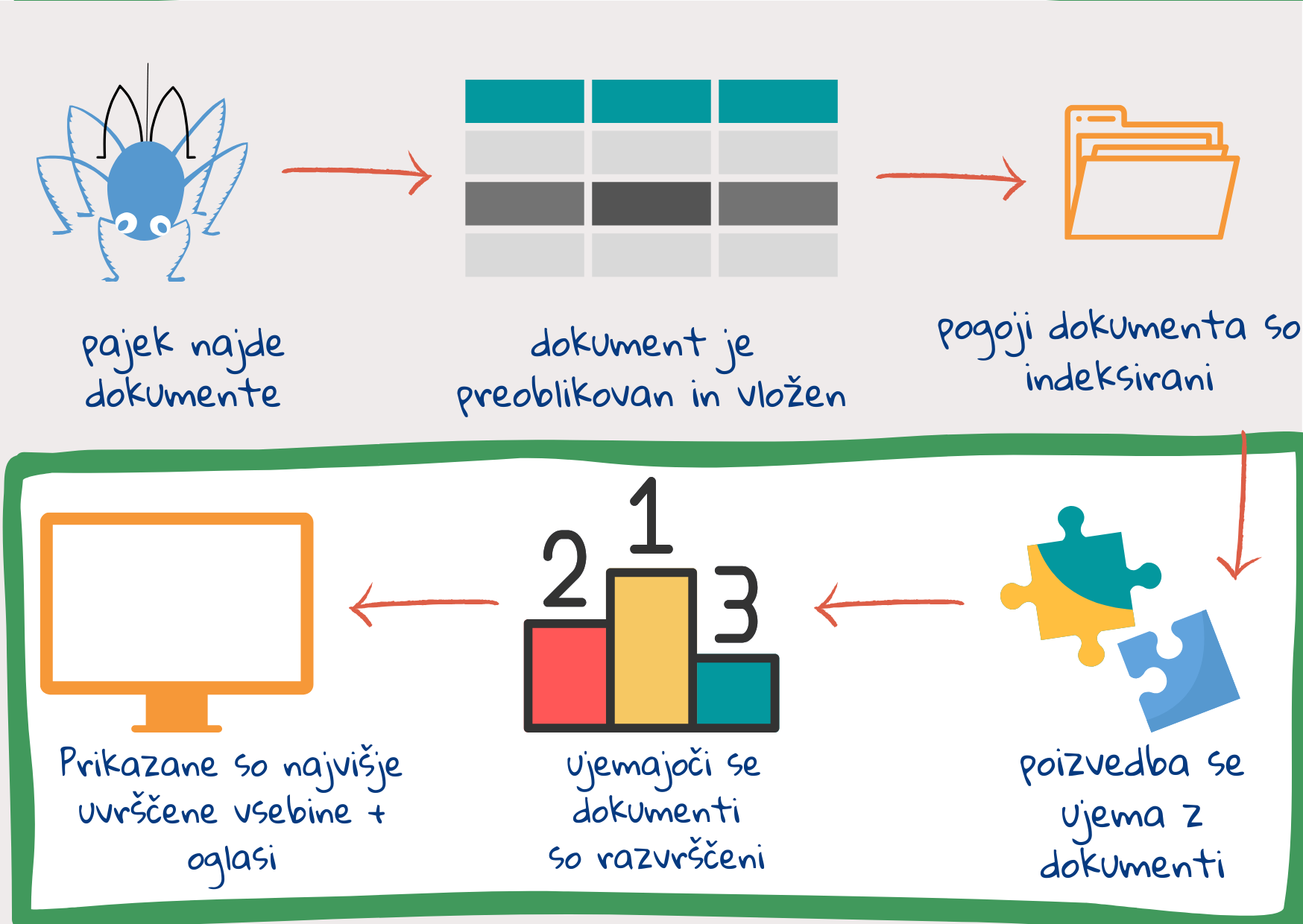
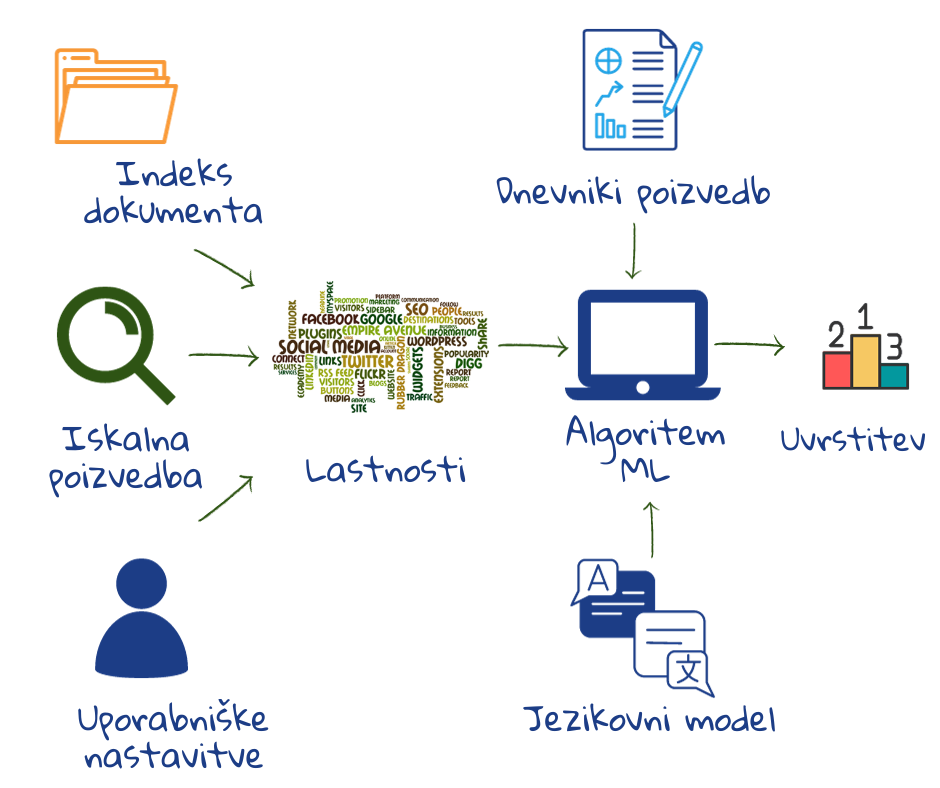
4. korak: usklajevanje izrazov iz poizvedbe z izrazi iz kazala

Ko uporabnik vnese iskalno poizvedbo in klikne na iskanje, se prične obdelava poizvedbe. Po enakem principu, kot nastane besedilo, se ustvarijo žetoni. Poizvedba se nato lahko razširi, z dodatnimi ključnimi besedami. Na ta način se izognemo situaciji, da ustreznih dokumentov ne najdemo, ker v poizvedbi uporabljamo nekoliko drugačne besede kot avtorji spletnih vsebin. To počnemo tudi zato, da upoštevamo morebitne razlike načinov rabe (npr., uporaba besed, kot so predsednik, premier, ali kancler, je lahko drugačna glede na državo)1.
Večina iskalnikov beleži zgodovino uporabnikovih poizvedb (za več informacij si oglejte Opis nekaterih priljubljenih iskalnikov). Poizvedbe se beležijo skupaj s podatki o uporabniku, za učinkovitejšo personalizacijo vsebin in zaradi prikazovanja oglasov. Podatki vseh uporabnikov se pogosto združijo in se obravnavajo kot celota, prav tako z namenom izboljšanja delovanja iskalnika.
Uporabniški dnevniki vsebujejo prejšnje poizvedbe, stran z rezultati in informacije o tem, kaj je delovalo (kaj je bilo ustrezno) – torej, kaj je uporabnik kliknil in koliko časa je porabil za branje teh strani. S pomočjo uporabniških dnevnikov je mogoče vsako poizvedbo povezati z relevantnimi dokumenti (uporabnik klikne, prebere stran in zaključi sejo) in z nerelevantnimi dokumenti (uporabnik ni kliknil ali prebral ali poskušal preoblikovati poizvedbe)2.
S takšnimi dnevniki lahko vsako novo poizvedbo primerjamo s preteklo poizvedbo, ki je podobna trenutni. Eden od načinov, kako ugotoviti, da je poizvedba podobna drugi poizvedbi je, da pogledamo ali razvrščanje prikaže iste dokumente: podobne poizvedbe morda ne vsebujejo vedno istih besed, vendar bodo prikazani rezultati verjetno enaki2.
Pravopisne napake lahko popravimo s podobnimi poizvedbami. Za razširitev poizvedbe lahko dodamo nove ključne besede ali sopomenke. To storimo tako, da poiščemo druge besede, ki se pogosto pojavljajo v dokumentih, ki so rezultat preteklih poizvedb. V splošnem pa velja, da se poizvedbi dodajo besede, ki se v relevantnih dokumentih pojavljajo pogosteje kot v nerelevantnih dokumentih, ali se tem besedam dodelijo dodatne uteži2.
5. korak: razvrstitev ustreznih dokumentov
Vsak dokument se oceni glede na relevantnost (ustreznost) in se nato glede na takšno oceno razvrsti. Pri tem je pomembna tako relevantnost teme – kako dobro se indeksirani izrazi dokumenta ujemajo z izrazi poizvedbe, kot tudi relevantnost za uporabnika – kako dobro se dokument ujema z uporabnikovimi preferencami. Delno lahko razvrščanje dokumentov poteka že med indeksiranjem. Hitrost iskalnika je odvisna od kakovosti kazal. Učinkovitost iskalnikov temelji na tem, kako se poizvedba ujema z dokumentom, in na sistemu razvrščanja2.

Relevantnost za uporabnika se meri s pomočjo uporabniških modelov (tipov osebnosti) na podlagi njihovih prejšnjih iskalnih izrazov, obiskanih spletnih mest, e-poštnih sporočil, naprave, ki jo uporabljajo, jezika in geografske lokacije. Piškotki se uporabljajo za shranjevanje uporabniških nastavitev. Nekateri iskalniki kupujejo podatke o uporabnikih tudi od tretjih oseb (gl. poglavje Opis nekaterih priljubljenih iskalnikov). Če osebo zanima nogomet, bodo njeni rezultati za poizvedbo “Manchester” drugačni od rezultatov za osebo, ki je pravkar rezervirala let v London. Besedam, ki se pogosto pojavljajo v dokumentih, relevantnih za to osebo, bo dodeljena največja relevantnost.
Komercialni spletni iskalniki v svoje algoritme razvrščanja vključujejo na stotine značilnosti/funkcij, od katerih jih veliko izhaja iz ogromne zbirke podatkov o interakciji uporabnikov (iz uporabniških dnevnikov). Funkcija razvrščanja združuje značilnosti, ki se nanašajo na relevantnost dokumenta, poizvedbe in uporabnika. Ne glede na funkcijo razvrščanja ima le-ta v principu trdno matematično podlago. Rezultat je izražena verjetnost, da dokument izpolnjuje uporabnikovo zahtevo. Dokument je razvrščen kot relevanten (ustrezen) takrat, ko je presežena določena stopnja verjetnosti za njegovo relelvantnost2.
Strojno učenje se uporablja za učenje razvrščanja na podlagi implicitnih povratnih informacij uporabnika v uporabniških dnevnikih (torej, kaj je delovalo oz. kaj je bilo ustrezno pri prejšnjih poizvedbah). Strojno učenje se uporablja tudi za razvoj izpopolnjenih modelov človeške rabe jezika, s pomočjo katerih se dekodirajo poizvedbe1,2.
 V zadnjem desetletju je tehnologija spletnega iskanja doživela velikanski napredek. Toda če govorimo o razumevanju konteksta posamezne poizvedbe, nič ne more nadomestiti vnosa boljše poizvedbe s strani uporabnika samega. Običajno boljše poizvedbe nastanejo tako, da uporabniki preučijo rezultate in nato preoblikujejo svojo prvotno poizvedbo2.
V zadnjem desetletju je tehnologija spletnega iskanja doživela velikanski napredek. Toda če govorimo o razumevanju konteksta posamezne poizvedbe, nič ne more nadomestiti vnosa boljše poizvedbe s strani uporabnika samega. Običajno boljše poizvedbe nastanejo tako, da uporabniki preučijo rezultate in nato preoblikujejo svojo prvotno poizvedbo2.
6. korak: prikaz rezultatov

Končno so rezultati pripravljeni za prikaz. Prikaže se naslov spletne strani (URL – Uniform Resource Locator), izrazi poizvedba pa so poudarjeni s krepkim tiskom. Pod vsako prikazano povezavo (rezultatom) je prikazan tudi kratek povzetek. V povzetku so izpostavljeni pomembni deli dokumenta. Uporabljeni so stavki iz naslovov, iz opisa metapodatkov ali iz besedila, ki najbolj ustreza poizvedbi. Če so vsi poizvedbeni izrazi navedeni v naslovu, se v povzetkih ne ponovijo2. Stavki so izbrani tudi glede na to, kako berljivi so.
Prikazane rezultate spremljajo primerni oglasi. Z oglaševanjem večina iskalnikov ustvarja prihodke. V nekaterih iskalnikih so oglasi jasno označeni kot ‘sponzorirana vsebina’, v drugih pa ne. Ker si veliko uporabnikov ogleda le prvih nekaj rezultatov, imajo oglasi bistven vpliv na celoten postopek.
Oglasi so izbrani glede na kontekst poizvedbe in glede na model uporabnika. Podjetja, ki se ukvarjajo s spletnimi iskalniki, črpajo iz podatkovne zbirke oglasov, kjer iščejo najustreznejše oglase za dano poizvedbo. Oglaševalci zakupijo ključne besede, ki opisujejo teme, povezane z njihovim produktom. Znesek njihove ponudbe kot tudi priljubljenost oglasov sta pomembna dejavnika v postopku izbire2.
Za poizvedbe o dejstvih nekateri iskalniki uporabljajo lastne zbirke dejstev. Googlova “zakladnica znanja” (Google Knowledge Vault) vsebuje več kot milijardo dejstev, indeksiranih iz različnih virov3. Rezultate algoritmi strojnega učenja združijo v ustrezne skupine. Za konec se uporabniku predstavijo še alternative njegovi poizvedbi, s čimer se preveri, ali nemara bolje ustrezajo njegovim dejanskim zahtevam.
Nekaj uporabnih virov:
Več o nastanku in razvoju Googla: S. Brin in L. Paige – izvirni prispevek
Matematika v ozadju razvrščanja: Wiki PageRank
Za nadebudne matematike: Pagerank
1 Russell, D., What Do You Need to Know to Use a Search Engine? Why We Still Need to Teach Research Skills, AI Magazine, 36(4), 2015.
2 Croft, B., Metzler D., Strohman, T., Search Engines, Information Retrieval in Practice, 2015.
3 Spencer, S., Google Power Search: The Essential Guide to Finding Anything Online With Google, Koshkonong, Kindle Edition.
