Poslušanje, govorjenje in pisanje
29 Govorica UI: globoke nevronske mreže
Strojno učenje sega globoko
Človeško znanje je obsežno, spremenljivo in težko opredeljivo. Človeški um je sposoben absorbirati in uporabljati znanje, ker je, kot so zapisali Chomsky, Roberts in Watumull, “…presenetljivo učinkovit, celo eleganten sistem, ki obdeluje majhne količine informacij. Ne stremi k sklepanju o surovih povezavah med podatki, ampak k razlaganju1.”
Strojno učenje naj bi to počelo z iskanjem vzorcev v velikih količinah podatkov. Prej pa so morali programerji ročno kodirati, določiti katere značilnosti podatkov so pomembne za obravnavani problem, in jih posredovati stroju v obliki “parametrov”2,3. Kot smo že povedali, je delovanje sistema močno odvisno od kakovosti podatkov in parametrov, ki jih ni vedno enostavno natančno določiti.
Globoke nevronske mreže ali globoko učenje predstavlja vejo strojnega učenja, ki omenjeno premaguje:
- z ekstrahiranjem lastnih parametrov iz podatkov v fazi učenja;
- z uporabo več plasti, ki gradijo razmerja med parametri, postopoma gredo od preprostih reprezentacij v najbolj zunanji plasti do bolj kompleksnih in abstraktnih. To globokemu učenju omogoča, da določene naloge opravi bolje kot običajni algoritmi strojnega učenja2.
Vse več zmogljivih aplikacij strojnega učenja se vedno bolj zanaša na globoko učenje. Sem spadajo iskalniki, sistemi priporočil, transkripcija govora in tudi prevod tega priročnika iz angleščine v slovenščino. Brez pretiravanja lahko rečemo, da je prav globoko učenje omogočilo uspeh UI pri številnih nalogah.
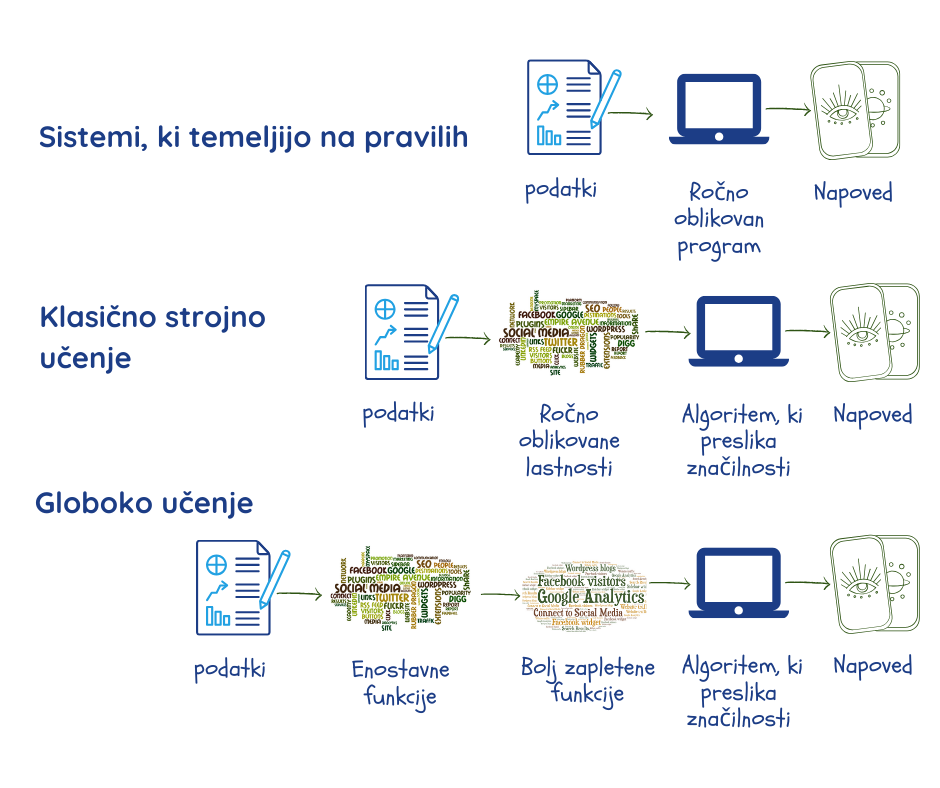
Izraz “globoke” (globoke nevronske mreže) se nanaša na to, kako se plasti nalagajo ena na drugo, da ustvarijo mrežo. Izraz “nevronske” odraža dejstvo, da so določene vidike njihove zasnove navdihnili biološki možgani. Kljub temu pa, in čeprav zagotavljajo vpogled v naše lastne miselne procese, so to strogo matematični modeli, ki v resnici niso podobni nobenemu biološkemu elementu ali procesu2.
Osnove globokega učenja
Ko ljudje gledamo sliko, na njej avtomatično prepoznamo predmete in obraze. Za algoritem pa slika ni nič drugega, kot le zbirka pikslov. Med mešanico barv in različnimi stopnjami svetlosti ter prepoznavanjem obrazov je velikanski preskok, ki ga je preveč zapleteno izvesti.
Globoka nevrosnka mreža to doseže tako, da proces razdeli na zelo preproste reprezentacije v prvi plasti – na primer tako, da primerja svetlost dveh sosednjih pikslov in tako ugotovi prisotnost ali odsotnost robov na različnih predelih slike. Naslednja plast na podlagi robov išče bolj kompleksne entitete – na primer, vogale in obrobe, pri čemer zanemari majhna odstopanja pri položajih robov2,3. Naslednja plast išče dele predmetov z uporabo obrob in vogalov. Postopoma se kompleksnost povečuje do točke, ko lahko zadnja plast združi različne dele dovolj dobro, da prepozna obraz ali identificira predmet.

Tega, kar je treba upoštevati v vsaki plasti, ne določajo programerji, temveč se tega sistem nauči iz podatkov v procesu učenja3. S primerjanjem napovedi z dejanskimi rezultati v učnem sklopu podatkov se delovanje vsake plasti uravna na nekoliko drugačen način, kar obrodi vsakič nekoliko boljši rezultat. Če je vse to izvedeno pravilno in pod pogojem, da je na voljo dovolj kakovostnih podatkov, bi se morala mreža razviti tako, da bo prezrla nepomembne dele slike, npr. natančno lokacijo entitet, kot in osvetlitev, ter se osredotočila na tiste dele, ki ji omogočajo prepoznavanje.
Tukaj je treba opozoriti na dejstvo, da je kljub naši uporabi robov in obrob za razumevanje procesa tisto, kar je dejansko predstavljeno v plasteh, niz številk, ki lahko ustrezajo stvarem, ki jih razumemo, ali pa tudi ne. Kar se pri tem ne spremeni, je vse večja abstraktnost in kompleksnost.
Oblikovanje globoke nevronske mreže
Ko se programer odloči za uporabo globokega učenja in pripravi podatke, mora najprej zasnovati tako imenovano arhitekturo svoje nevronske mreže. Določiti mora število plasti (globina mreže) in število parametrov na plast (širina mreže). Nato se mora odločiti, kako vzpostaviti povezave med plastmi – ali bo vsaka enota plasti povezana z vsako enoto prejšnje plasti ali ne.
Idealna arhitektura za določeno nalogo pogosto se pogosto izkaže kot posledica eksperimentiranja. Večje kot je število plasti, manj parametrov je potrebnih na vsaki plasti. Mreže delujejo bolje s splošnimi podatki, čeprav jih je zato težje optimizirati. Manj povezav bi pomenilo manj parametrov in manj računanja, vendar bi to zmanjšalo prilagodljivost mreže2.
Učenje globoke nevronske mreže
Vzemimo primer usmerjene nevronske mreže z nadzorovanim učenjem. Informacije tečejo naprej od ene plasti k naslednji, globlji plasti, brez povratnih zank. Kot pri vseh tehnikah strojnega učenja je tudi tukaj cilj ugotoviti, kako so vhodi povezani z izhodi – kateri parametri se združijo in kako se združijo, preden ustvarijo rezultat. Predpostavimo razmerje f, ki povezuje vhod x z izhodom y. Nato uporabimo mrežo, da poiščemo niz parametrov θ, ki dajejo najboljše ujemanje za napovedane in dejanske izhodne vrednosti.
Ključno vprašanje: Napovedani y je f (x, θ), za kateri θ?
Pri tem je napoved za y končni rezultat, sklop podatkov x pa je vhod. Pri prepoznavanju obraza je x običajno sklop pikslov na sliki. y je lahko ime osebe. V mreži plasti delujejo podobno kot delavci v proizvodni liniji, kjer se vsak delavec loti tistega, kar mu je bilo dodeljeno, potem pa to posreduje naprej naslednjemu delavcu. Prvi delavec vzame vhodno vrednost in jo malo preoblikuje, nato jo da drugemu v liniji. Drugi naredi isto, nato preda tretjemu in tako naprej, dokler se vhodna vrednost ne preoblikuje v končni rezultat.
Matematično je funkcija f razdeljena na več funkcij f1, f2, f3… pri čemer je f = ….f3(f2(f1(x))). Plast poleg vhoda preoblikuje parametre vhoda z uporabo f1, naslednja plast z uporabo f2 in tako naprej. Programer lahko pri tem posreduje, tako da pomaga izbrati pravilno družino funkcij na podlagi poznavanja problema.
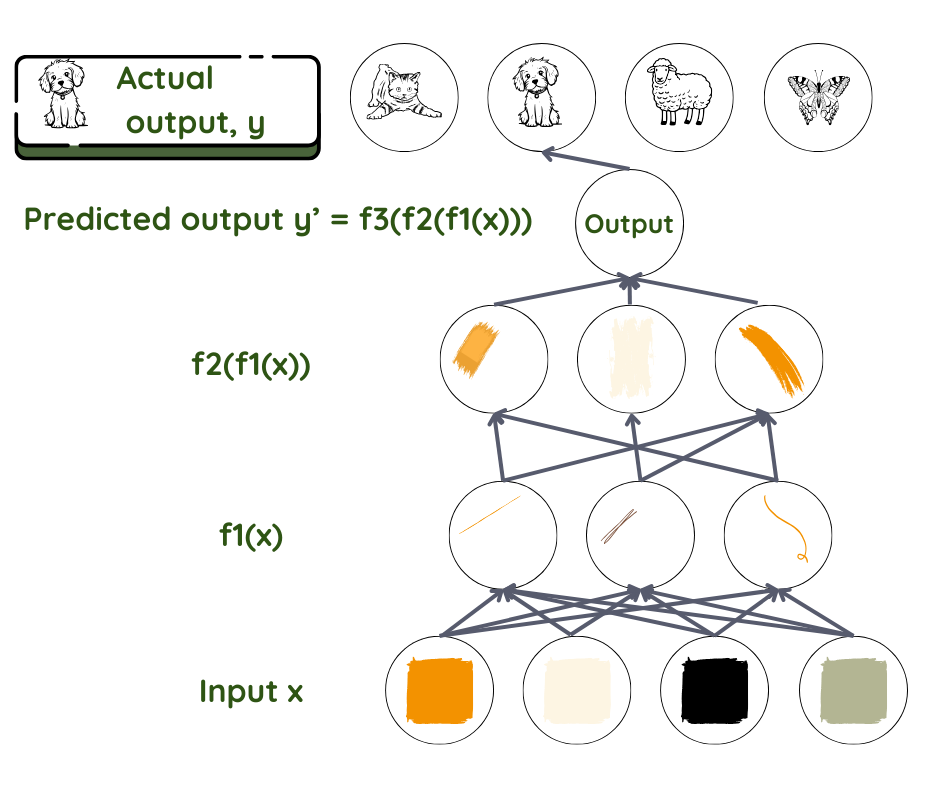
Naloga vsake plasti je, da dodeli raven pomembnosti – utež, ki jo dodeli vsakemu prejetemu parametru. Uteži so kot stikala, ki na koncu opredelijo razmerje med predvidenim izhodom in vhodom v določeni plasti3. V povprečnem sistemu globokega učenja je takšnih “stikal” na stotine milijonov, kot je tudi na stotine milijonov učnih primerov. Ker ne določamo, niti ne moremo videti izhodnih vrednosti in uteži v plasteh med vhodno in izhodno vrednostjo, se takšne plasti imenujejo skrite plasti.
Pri zgornjem primeru prepoznavanja predmeta je naloga prvega “delavca” v globoki nevronski mreži, da zazna robove in jih preda drugemu delavcu, ki bo zaznal obrobe, in tako naprej.
V fazi učenja se napovedana izhodna vrednost primerja z dejansko izhodno vrednostjo. Če med njima obstaja velika razlika, je treba toliko bolj spremeniti uteži, dodeljene v vsaki plasti. Če je razlika majhna, je potrebno le malo prilagoditi vrednosti uteži. Ta proces poteka v dveh delih. Najprej se izračuna razlika med napovedjo in rezultatom (izhodom), nato pa drug algoritem izračuna, kako prilagoditi uteži v vsaki plasti, začenši z izhodno plastjo (v tem primeru informacije tečejo nazaj iz globljih plasti). Tako je na koncu procesa učenja mreža z vsemi svojimi utežmi in funkcijami pripravljena za “napad” na testne podatke. Preostali del procesa je enak kot pri klasičnem strojnem učenju.

1 Chomsky, N., Roberts, I., Watumull, J., Noam Chomsky: The False Promise of ChatGPT, The New York Times, 2023.
2 Goodfellow, I.J., Bengio, Y., Courville, A., Deep Learning, MIT Press, 2016.
3 LeCun, Y., Bengio, Y., Hinton, G., Deep learning, Nature 521, 436–444 (2015).
