Listening, Speaking and Writing
30 AI-Speak: Natural Language Processing
Natural language processing has been a topic on which research has worked in length for the past 50 years. This has led to the development of many tools we use every day:
- Word processors
- Automatic grammar and orthography correction
- Automatic completion
- Optical character recognition (OCR)
More recently, chatbots, home assistants and automatic translation tools have been making a huge impact in all areas.
For a long time, research and industry was stalled by the intrinsic complexity of language. At the end of the 20th century, grammars for a language, written by experts, could have up to 50,000 rules. These expert systems were showing that technology could make a difference, but robust solutions were too complex to develop.
On the other hand, speech recognition needed to be able to make use of acoustic data and transform it into text. With the variety of speakers one could find, a hard task indeed!
Researchers understood that if we had a model for the intended language, things would be easier. If we knew the words of the language, how sentences were formed, then it would be easier to find the right sentence from a set of candidates to match a given utterance, or to produce a valid translation from a set of possible sequences of words.
Another crucial aspect has been that of semantics. Most of the work we can do to solve linguistic questions is shallow; the algorithms will produce an answer based on some local syntactic rules. If in the end, the text means nothing, so be it. A similar thing may happen when we read a text by some pupils – we can correct the mistakes without really understanding what the text is about! A real challenge is to associate meaning to text and, when possible, to uttered sentences.
There was a surprising result in 20081. One unique language model could be learnt from a large amount of data and used for a variety of linguistic tasks. In fact, that unique model performed better than models trained for specific tasks.
The model was a deep neural network. Nowhere as deep as the models used today! But enough to convince research and industry that machine learning, and more specifically Deep learning was going to be the answer to many questions in NLP.
Since then, natural language processing has ceased to follow a model-driven approach and has been nearly always based on a data-driven approach.
Traditionally, the main language tasks can be decomposed into 2 families – those involving building models and those involving decoding.
Building models
In order to transcribe, answer questions, generate dialogues or translate, you need to be able to know whether or not “Je parle Français” is indeed a sentence in French. And as with spoken languages, rules of grammar are not always followed accurately, so the answer has to be probabilistic. A sentence can be more or less French. This allows the system to produce different candidate sentences (as the transcription of a sound, or the translation of a sentence) and the probability is given as a score associated with each candidate. We can take the highest-ranking sentence or combine the score with other sources of information (we may also be interested in what the sentence is about).
Language models do this, and the probabilities are built from machine-learning algorithms. And of course, the more data there is, the better. For some languages there is a lot of data from which to build language models. For others, this is not the case; these are under-resourced languages.
In the case of translation, we want not two but three models: a language model for each language and another model for the translations, informing us of what the better translations of fragments of language can be. These are difficult to produce when data is scarce. If models for common language pairs are easier to build, this will not be the case for languages that are not frequently spoken together (such as Portuguese and Slovene). A typical way out of this is to use a pivot language (typically English) and translate via this pivot language – from Portuguese to English and then from English to Slovene. This will lead to inferior results as errors accumulate.
Decoding
Decoding is the process in which an algorithm takes the input sequence (which can be signal or text) and, by consulting the models, makes a decision, which will often be an output text. There are here some algorithmic considerations – in many cases transcription and translation are to happen in real time and diminishing the time lag is a key issue. So there is room for a lot of artificial intelligence.
End-to-end
Nowadays, the approach of building these components separately and combining them later has been replaced by end-to-end approaches in which the system will transcribe/translate/interpret the input through a unique model. Currently, such models are trained by deep neural networks, which can be huge. It is reported that the current largest GPT3 model comprises several hundred million parameters!
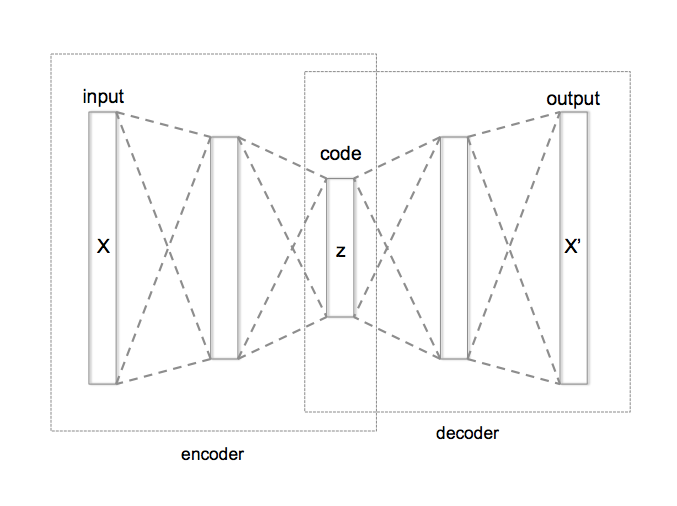
Let’s try to get at the intuition behind this process. Suppose we have some data. This raw data can be encoded in some way. But the encoding can be redundant, and perhaps even expensive. Let us now build a particular machine, called an auto-encoder (see diagram to the left). This machine will be able to take a text, compress it into a small vector (this is the encoder), and then uncompress the vector (the decoder part) and return a text which is somehow close to the original text. The idea is that this mechanism will make the intermediate vector meaningful, with two desirable properties – a reasonably small vector which ‘contains’ the information in the initial text.
The future
An example of an end-to-end process that might be available soon will be the ability to perform the following task – it will hear you speak your language, transcribe your text, translate it to a language you don’t know, train a speech synthesis system to your voice, and have your own voice speak the corresponding text in a new sentence. Here are two examples produced by researchers at the Universidad Politecnica de Valencia, Spain, in which the speaker’s own voice model is used to do the dubbing.
Some consequences for education
The steady progress of natural language processing is remarkable. Where we would laugh at the translations proposed by AI just ten years ago, it becomes increasingly difficult to find such obvious errors today. Speech recognition and character-recognition techniques are also improving fast.
The semantics challenges are still there, and answering questions which require a deep understanding of a text is still not quite right. But things are going in the right direction. This means that the teacher should expect some of the following statements to be true soon, if they are not already out there!
- A pupil will take a complex text and obtain (with AI) a simplified version; the text may even be personalised and use terms, words and concepts the pupil is used to;
- A pupil will be able to find a text, copy it, and obtain a text stating the same things but undetectable by an anti-plagiarism tool;
- Videos produced anywhere in the world will be accessible through automatic dubbing in any language. This means that our pupils will be exposed to learning material built in our language and also by material initially designed for another learning system in a different culture;
- Writing essays could become a task of the past, as tools will enable writing on any topic.
It is clear that AI will be far from perfect, and the expert will detect that even if the language is correct, the flow of ideas won’t be. But let’s face it, during the course of education, how long does it take for our pupils and students to reach that level?
1 Collobert, Ronan, and Jason Weston. A unified architecture for natural language processing: Deep neural networks with multitask learning. Proceedings of the 25th international conference on Machine learning. 2008. http://machinelearning.org/archive/icml2008/papers/391.pdf. Note: this reference is given for historical reasons. But it is difficult to read!
