Finding Information
11 AI Speak: Search Engine Ranking
Compared to the search engines of the early 2000s, the present search engines do richer and deeper analysis. For example, as well as counting words, they can analyse and compare the meaning behind words1. Much of this richness happens in the ranking process:
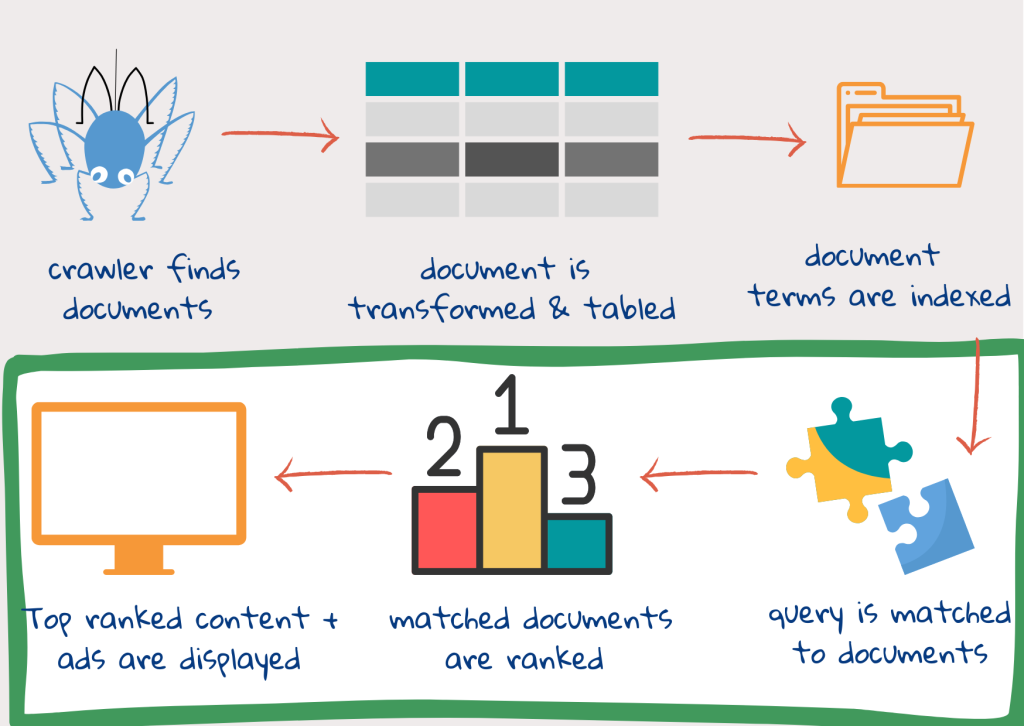
Step 4: Query terms are matched with index terms

Once the user types the query and clicks on search, the query is processed. Tokens are created using the same process as the document text. Then the query may be expanded by adding other keywords. This is to avoid the situation whereby relevant documents are not found because the query uses words that are slightly different from those of the web-content authors. This is also done to capture differences in custom and usage. For example, the use of words such as president, prime minister and chancellor may be interchanged, depending on the country1.
Most search engines keep track of user searches (Look at the description of popular search engines to learn more). Queries are recorded with the user data in order to personalise content and serve advertisements. Or, the records from all users are put together to see how and where to improve search engine performance.
User User logs contain items such as past queries, the results page and information on what worked. For example, what did the user click and what did they spend time reading? With user logs, each query can be matched with relevant documents (the user clicks, reads and closes session) and non-relevant documents (user did not click or did not read or tried to rephrase query)2.
With these logs, each new query can be matched with a similar past query. One way of finding out if one query is similar to another, is to check if ranking turns up the same documents. Similar queries may not always contain the same words but the results are likely to be identical2.
Spelling added to expand the query. This is done by looking at other words that occur frequently in relevant documents from the past. In general, however, words that occur more frequently in the relevant documents than in the non-relevant documents are added to the query or given additional weightage2.
Step 5: Relevant documents are ranked
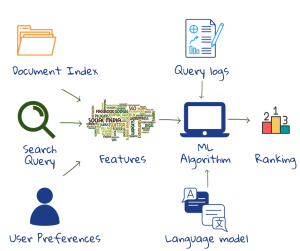
Each document is scored for relevance, and ranked according to this score. Relevance here is both topic relevance – how well the index terms of a document match that of the query, and user relevance – how well it matches the preferences of the user. A part of document scoring can be done while indexing. The speed of the search engine depends on the quality of indexes. Its effectiveness is based on how the query is matched to the document as well as on the ranking system2.
 User relevance is measured by creating user models (or personality types), based on their previous search terms, sites visited, email messages, the device they are using, language and geographic location. Cookies are used to store user preferences. Some search engines buy user information from third parties as well (you could refer to descriptions of some search engines). If a person is interested in football their results for “Manchester” will be different from the person who just booked a flight to London. Words that occur frequently in the documents associated with a person will be given the highest importance.
User relevance is measured by creating user models (or personality types), based on their previous search terms, sites visited, email messages, the device they are using, language and geographic location. Cookies are used to store user preferences. Some search engines buy user information from third parties as well (you could refer to descriptions of some search engines). If a person is interested in football their results for “Manchester” will be different from the person who just booked a flight to London. Words that occur frequently in the documents associated with a person will be given the highest importance.
Commercial web search engines incorporate hundreds of features in their ranking algorithms; many derived from the huge collection of user interaction data in the query logs. A ranking function combines the document, the query and user relevance features. Whatever ranking function is used, it would have a solid mathematical foundation. The output is the probability that a document satisfies the user’s information need. Above a certain probability of relevance, the document is classified as relevant2.
Machinelearning is used to learn about ranking on implicit user feedback in the logs (ie, what worked in previous queries). Machine learning has also been used to develop sophisticated models of how humans use language; this is used to decipher queries1,2.
 Advances in web search have been phenomenal in the past decade. However, where it refers to understanding the context for a specific query, there is no substitute for the user providing a better query. Typically, better queries come from users who examine results and reformulate the query2.
Advances in web search have been phenomenal in the past decade. However, where it refers to understanding the context for a specific query, there is no substitute for the user providing a better query. Typically, better queries come from users who examine results and reformulate the query2.
Step 6: Results are displayed
the results are ready. The page’s title and url are displayed, with query terms in bold. A short summary is generated and displayed after each link. The summary highlights important passages in the document.
In this regard, sentences are taken from headings, metadata description or from text that best corresponds with the query. If all query terms appear in the title, they will not be repeated in the snippet2. Sentences are also selected based on how readable they are.
Appropriate advertising is added to the results. Search engines generate revenue through advertisements. In some search engines, they are clearly marked as sponsored content, while in others they are not. Since many users look at only the first few results, ads can change the process substantially.
Advertisements are chosen according to the context of the query and the user model. Search engine companies maintain a database of advertisements. This database is searched to find the most relevant advertisements for a given query. Advertisers bid for keywords that describe topics associated with their product. Both the amount bid and the popularity of an advertisement are significant factors in the selection process2.
For questions on facts, some engines use their own collection of facts. Google’s Knowledge Vault contains over a billion facts indexed from different sources3. Results are clustered by machine learning algorithms into appropriate groups. Finally, the user is also presented with alternatives to the query to see if they are better.
Some references
The origin of Google can be found in Brin and Page’s original paper. Some of the maths behind Pagerank are on Wiki’s PageRank. For the mathematical minded, here is a nice explanation of Pagerank.
1 Russell, D., What Do You Need to Know to Use a Search Engine? Why We Still Need to Teach Research Skills, AI Magazine, 36(4), 2015.
2 Croft, B., Metzler D., Strohman, T., Search Engines, Information Retrieval in Practice, 2015.
3 Spencer, S., Google Power Search: The Essential Guide to Finding Anything Online With Google, Koshkonong, Kindle Edition.
