Zuhören, Sprechen und Schreiben
30 KI-Sprache: Natürliche Sprachverarbeitung
Natürliche Sprachverarbeitung ist ein Thema, mit dem sich die Forschung in den letzten 50 Jahren intensiv beschäftigt hat. Dies hat zur Entwicklung vieler Tools geführt, die wir täglich nutzen:
- Wortprozessoren
- Automatische Grammatik- und Rechtschreibkorrektur
- Automatische Vervollständigung
- Optische Zeichenerkennung (OCR)
In jüngster Zeit haben Chatbots, Heimassistenten und automatische Übersetzungstools in allen Bereichen einen enormen Einfluss ausgeübt.
Lange Zeit wurden Forschung und Industrie durch die inhärente Komplexität der Sprache ausgebremst. Ende des 20. Jahrhunderts konnten Grammatiken für eine Sprache, die von Fachleuten geschrieben wurden, bis zu 50.000 Regeln enthalten. Diese Expertensysteme zeigten, dass Technologie etwas bewirken konnte, aber robuste Lösungen waren zu komplex, um sie zu entwickeln.
Auf der anderen Seite musste die Spracherkennung in der Lage sein, akustische Daten zu nutzen und sie in Text umzuwandeln. Bei der Vielzahl von Sprechenden, die man finden konnte, in der Tat eine sehr schwierige Aufgabe!
Die Forschenden waren sich darüber im Klaren, dass es einfacher wäre, wenn wir ein Modell der beabsichtigten Sprache hätten: Wenn wir wüssten, welche Wörter die Sprache enthält und wie Sätze gebildet werden, wäre es einfacher, aus einer Reihe von Kandidaten den richtigen Satz zu finden, der zu einer bestimmten Äußerung passt, oder aus einer Reihe von möglichen Wortfolgen eine gültige Übersetzung zu erstellen.
Ein weiteres wichtiges Thema ist die Semantik. Das meiste, was wir zur Lösung linguistischer Fragen tun können, ist oberflächlich: Die Algorithmen liefern eine Antwort auf der Grundlage einiger lokaler syntaktischer Regeln. Wenn der Text am Ende nichts bedeutet, dann ist das eben so. Ähnliches kann passieren, wenn wir einen Text von Schülerinnen bzw. Schülern lesen: Wir können die Fehler korrigieren, ohne wirklich zu verstehen, worum es in dem Text geht! Eine echte Herausforderung besteht darin, dem Text und, wenn möglich, den gesprochenen Sätzen eine Bedeutung zuzuordnen.
Im Jahr 2008 kam ein überraschendes Ergebnis1: Ein einziges Sprachmodell konnte aus einer großen Menge von Daten erlernt und für eine Vielzahl von sprachlichen Aufgaben verwendet werden. Dieses einzigartige Modell schnitt sogar besser ab als Modelle, die für die jeweiligen Aufgaben trainiert wurden.
Das Modell war ein tiefes neuronales Netzwerk. Bei weitem nicht so tief wie die heute verwendeten Modelle! Aber es reichte aus, um Forschung und Industrie davon zu überzeugen, dass maschinelles Lernen und insbesondere Deep Learning die Antwort auf viele Fragen im Bereich NLP sein würde.
Seitdem hat die natürliche Sprachverarbeitung aufgehört, einem modellgesteuerten Ansatz zu folgen, und basiert fast immer auf einem datengesteuerten Ansatz.
Traditionell lassen sich die wichtigsten Sprachaufgaben in 2 Familien unterteilen: diejenigen, bei denen es um die Erstellung von Modellen geht, und diejenigen, bei denen es um die Dekodierung geht.
Aufbau von Modellen
Um zu transkribieren, Fragen zu beantworten, Dialoge zu erstellen oder zu übersetzen, müssen Sie wissen, ob „Je parle Français” tatsächlich ein Satz auf Französisch ist oder nicht. Und da die Grammatik der gesprochenen Sprache nicht immer genau befolgt wird, muss die Antwort probabilistisch sein: Ein Satz ist mehr oder weniger Französisch. Dies ermöglicht es dem System, verschiedene Kandidatensätze zu produzieren (wie die Transkription eines Lautes, die Übersetzung eines Satzes, …) und die Wahrscheinlichkeit kann eine Punktzahl sein. Wir können den am höchsten bewerteten Satz nehmen oder die Punktzahl mit anderen Informationsquellen kombinieren (wir können auch daran interessiert sein, worum es in dem Satz geht).
Sprachmodelle tun dies: Die Wahrscheinlichkeiten werden von Algorithmen des maschinellen Lernens erstellt. Je mehr Daten vorhanden sind, umso besser. Für einige Sprachen gibt es eine Menge Daten, aus denen Sprachmodelle erstellt werden können. Bei anderen ist das nicht der Fall: Das sind Sprachen, für die nur wenige Daten vorliegen.
Für den Fall der Übersetzung brauchen wir nicht 2, sondern 3 Modelle: ein Sprachmodell für jede Sprache und ein weiteres Modell für die Übersetzungen, das uns darüber informiert, wie die besseren Übersetzungen von Sprachfragmenten aussehen können. Diese Modelle sind schwer zu erstellen, wenn die Daten knapp sind. Wenn Modelle für gängige Sprachpaare leichter zu erstellen sind, gilt dies nicht für Sprachen, die nicht häufig zusammen gesprochen werden (z. B. Portugiesisch und Slowenisch). Ein typischer Ausweg ist hier die Verwendung einer Pivot-Sprache (in der Regel Englisch) und die Übersetzung über diese Pivot-Sprache: von Portugiesisch nach Englisch und dann von Englisch nach Slowenisch. Das führt natürlich zu minderwertigen Ergebnissen, da sich die Fehler häufen.
Dekodierung
Die Dekodierung ist der Prozess, bei dem ein Algorithmus die Eingabesequenz (bei der es sich um ein Signal oder einen Text handeln kann) nimmt und anhand der Modelle eine Entscheidung trifft, die häufig ein Ausgabetext sein wird. Hier gibt es einige algorithmische Überlegungen: In vielen Fällen müssen Transkription und Übersetzung in Echtzeit erfolgen, und die Verringerung der Verzögerung ist ein wichtiges Thema. Es gibt also viel Raum für künstliche Intelligenz.
End-to-End
Heutzutage ist der Ansatz, diese Komponenten separat zu erstellen und später zu kombinieren, durch End-to-End-Ansätze ersetzt worden, bei denen das System die Eingabe durch ein einziges Modell transkribiert/übersetzt/interpretiert. Derzeit werden solche Modelle von tiefen neuronalen Netzen trainiert, die riesig sein können: Es wird berichtet, dass das derzeit größte GPT3-Modell mehrere hundert Millionen Parameter umfasst!
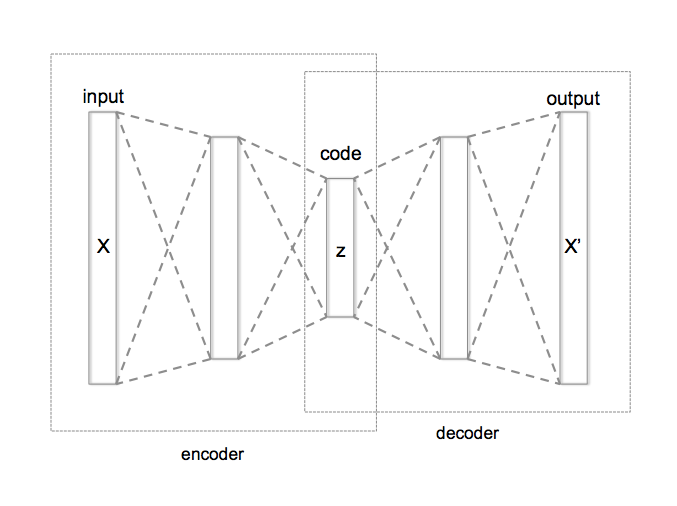
Lassen Sie uns versuchen, Zusammenhänge zu verstehen: Angenommen, wir haben einige Daten. Diese Rohdaten können auf irgendeine Weise kodiert werden. Aber die Kodierung kann sehr redundant und vielleicht sogar teuer sein. Lassen Sie uns nun eine bestimmte Maschine bauen, die wir Auto-Encoder nennen (siehe Diagramm unten). Diese Maschine ist in der Lage, einen Text zu nehmen, ihn in einen kleinen Vektor zu komprimieren (das ist der Encoder) und dann den Vektor zu dekomprimieren (der Decoderteil) und einen Text wiederherzustellen, der dem ursprünglichen Text irgendwie nahe kommt. Die Idee ist, dass dieser Mechanismus den Zwischenvektor sehr aussagekräftig macht und ihm zwei wünschenswerte Eigenschaften verleiht: dass der Vektor einigermaßen klein ist und dass er die Informationen des Ausgangspunktes enthält.
Die Zukunft
Ein Beispiel für ein End-to-End-System, das wir bald sehen werden, wird folgende Aufgabe erfüllen können: Es hört Sie Ihre Sprache sprechen, transkribiert Ihren Text, übersetzt ihn in eine Sprache, die Sie nicht kennen, trainiert ein Sprachsynthesesystem auf Ihre Stimme und lässt Ihre eigene Stimme den entsprechenden Text in einem neuen Satz sprechen. Hier sehen Sie zwei Beispiele, die von Forschenden der Universidad Politecnica de Valencia in Spanien produziert wurden und bei denen das eigene Sprachmodell der Sprecherin bzw. des Sprechers für die Synchronisation verwendet wird.
Einige Konsequenzen für die Bildung
Die stetigen Fortschritte bei der Verarbeitung natürlicher Sprache sind bemerkenswert. Wo wir noch vor 10 Jahren über die dummen Übersetzungen, die von der KI vorgeschlagen wurden, gelacht hätten, wird es heute immer schwieriger, grobe Fehler zu finden. Auch die Techniken zur Sprach- und Zeichenerkennung werden immer besser.
Die semantischen Herausforderungen sind immer noch da und die Beantwortung von Fragen, die ein tiefes Verständnis eines Textes erfordern, funktioniert immer noch nicht richtig. Aber die Dinge entwickeln sich in die richtige Richtung. Das bedeutet, dass Lehrkräfte damit rechnen sollten, dass einige der folgenden Aussagen bald wahr sein werden, wenn sie es nicht schon sind!
- Ein Schüler bzw. eine Schülerin wird einen komplexen Text nehmen und (mit KI) eine vereinfachte Version erhalten; der Text kann sogar personalisiert sein und Begriffe, Wörter und Konzepte verwenden, die ihm btw. ihr vertraut sind.
- Ein Schüler bzw. eine Schülerin wird in der Lage sein, einen Text zu nehmen und einen Text zu erhalten, in dem dieselben Dinge stehen, der aber von einem Anti-Plagiat-Tool nicht entdeckt werden kann.
- Videos, die irgendwo auf der Welt produziert werden, werden durch automatische Synchronisation in jeder Sprache zugänglich sein: Das bedeutet insbesondere, dass unsere Schülerinnen und Schüler nicht nur mit Lernmaterial in unserer Sprache konfrontiert werden, sondern auch mit Material, das ursprünglich für ein anderes Lernsystem, eine andere Kultur entwickelt wurde.
- Das Verfassen von Aufsätzen könnte der Vergangenheit angehören, da die Tools es ermöglichen werden, zu jedem Thema etwas zu schreiben.
In diesen Beispielen wird deutlich, dass die KI bei weitem nicht perfekt sein und die Person mit Fachkenntnis feststellen wird, dass die Sprache zwar korrekt ist, der Ideenfluss jedoch nicht. Aber seien wir ehrlich: Wie lange dauert es im Laufe der Ausbildung, bis unsere Schülerinnen und unsere Studierenden dieses Niveau erreichen?
1 Collobert, Ronan, and Jason Weston. “A unified architecture for natural language processing: Deep neural networks with multitask learning.” Proceedings of the 25th international conference on Machine learning. 2008. http://machinelearning.org/archive/icml2008/papers/391.pdf. Note: this reference is given for historical reasons. But it is difficult to read!
