Informationen finden
10 KI-Sprache: Suchmaschinenindizierung
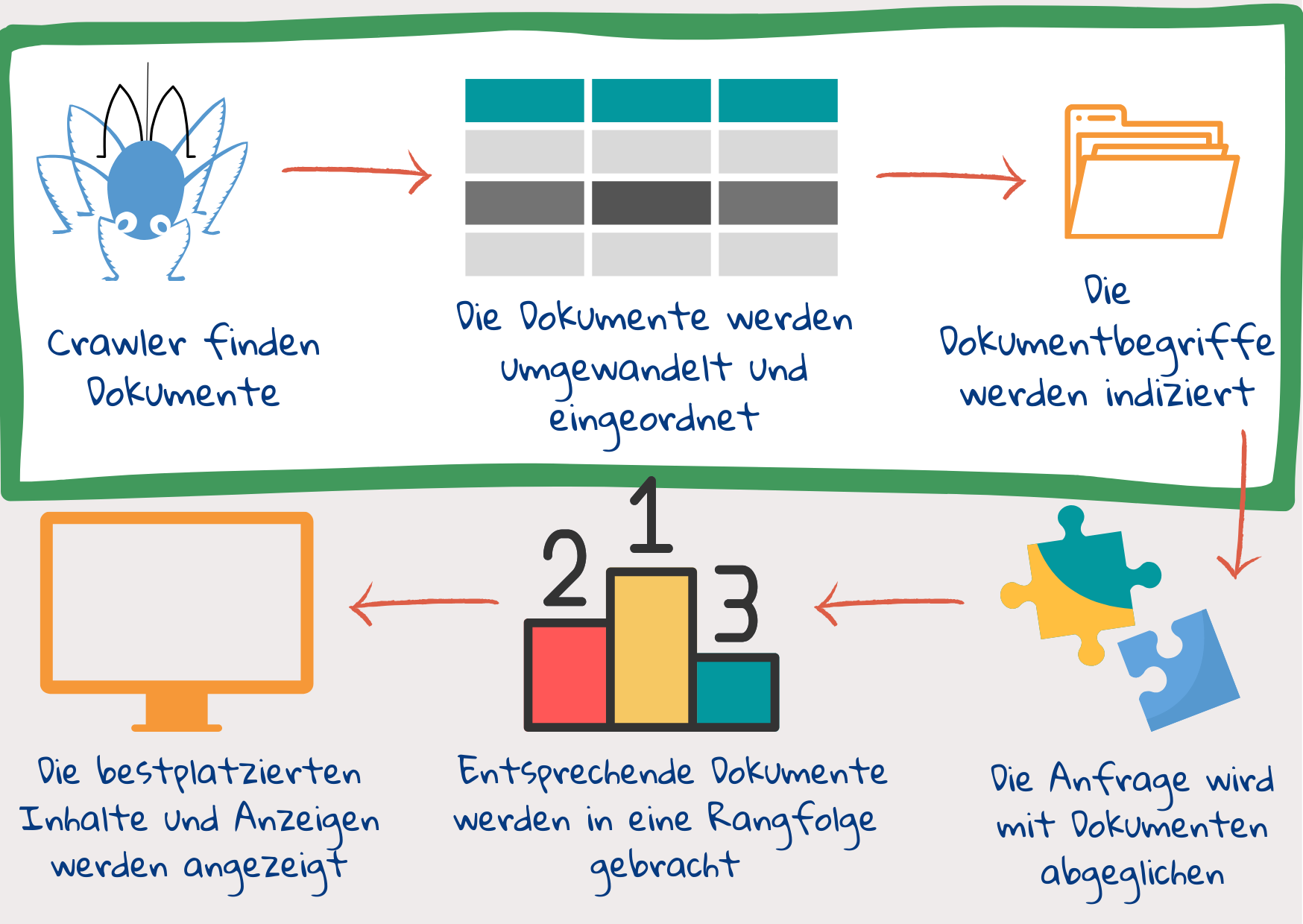
Eine Suchmaschine nimmt die in das Suchfeld eingegebenen Schlüsselwörter – die Suchanfrage – auf und versucht, die Webdokumente zu finden, die dem Informationsbedarf eines Nutzers entsprechen. Anschließend zeigt sie die Informationen in leicht zugänglicher Form an, wobei die relevanteste Seite ganz oben steht. Um dies zu erreichen, muss die Suchmaschine zunächst Dokumente im Internet finden und sie mit Tags versehen, damit sie leicht abrufbar sind. Schauen wir uns in groben Zügen an, was bei diesem Prozess vor sich geht.
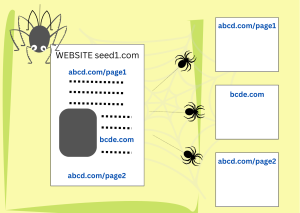
Schritt 1: Web-Crawler finden Dokumente und laden sie herunter
unter CC BY-SA 4.0. Informationen zu dieser Lizenz finden Sie unter: https://www.seobility.net/en/wiki/Creative_Commons_License_BY-SA_4.0
Nachdem ein Nutzender eine Suchanfrage eingegeben hat, ist es zu spät, sich alle im Internet verfügbaren Inhalte anzusehen1. Die Webdokumente werden vorher gesichtet, ihr Inhalt wird aufgeschlüsselt und in verschiedenen Slots gespeichert. Sobald die Abfrage vorliegt, muss nur noch der Inhalt der Abfrage mit dem Inhalt der Slots abgeglichen werden.
Web-Crawler sind Teile von Programmcodes, die Dokumente im Internet finden und herunterladen. Sie beginnen mit einer Reihe von Website-Adressen (URLs) und suchen in ihnen nach Links zu neuen Websites. Dann laden sie die neuen Seiten herunter und suchen darin nach weiteren Links. Wenn die Startliste vielfältig genug ist, besuchen die Crawler am Ende jede Website, die den Zugang zu ihnen erlaubt – oft mehrmals, um nach Aktualisierungen zu suchen.
Schritt 2: Das Dokument wird in zahlreiche Teile zerlegt
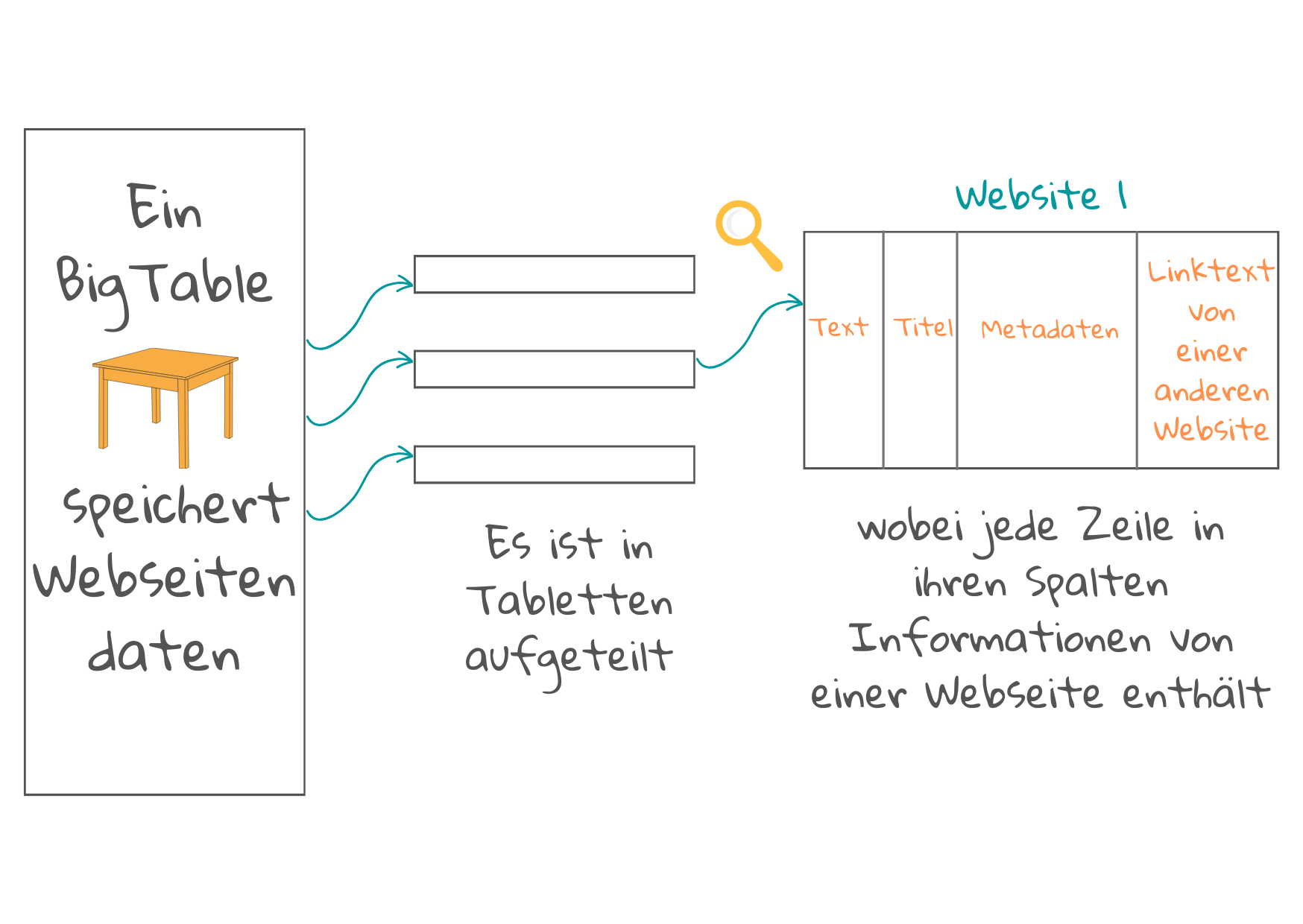 Das vom Crawler heruntergeladene Dokument kann eine klar strukturierte Webseite mit einer eigenen Beschreibung von Inhalt, Autor, Datum usw. sein. Es kann aber auch ein schlecht eingescanntes Bild eines alten Bibliotheksbuchs sein. Suchmaschinen können in der Regel hunderte verschiedene Dokumenttypen lesen1. Sie wandeln diese in html oder xml um und speichern sie in Tabellen (im Falle von Google BigTable genannt).
Das vom Crawler heruntergeladene Dokument kann eine klar strukturierte Webseite mit einer eigenen Beschreibung von Inhalt, Autor, Datum usw. sein. Es kann aber auch ein schlecht eingescanntes Bild eines alten Bibliotheksbuchs sein. Suchmaschinen können in der Regel hunderte verschiedene Dokumenttypen lesen1. Sie wandeln diese in html oder xml um und speichern sie in Tabellen (im Falle von Google BigTable genannt).
Eine Tabelle besteht aus kleineren Abschnitten, die Tablets genannt werden, wobei jede Zeile des Tablets einer Webseite gewidmet ist. Diese Zeilen sind in einer bestimmten Reihenfolge angeordnet, die zusammen mit einem Protokoll für Aktualisierungen aufgezeichnet wird. Jede Spalte enthält spezifische Informationen über die Webseite, die beim Abgleich des Dokumenteninhalts mit dem Inhalt einer künftigen Abfrage hilfreich sein können. Die Spalten enthalten:
- Die Adresse der Internetseite, die allein schon eine gute Beschreibung des Inhalts der Seite geben kann, wenn es sich um eine Homepage mit repräsentativem Inhalt oder eine Seite mit damit verbundenem Inhalt handelt.
- Titel, Überschriften und fett gedruckte Wörter, die wichtige Inhalte beschreiben.
- Metadaten der Seite: Dies sind Informationen über die Seite, die nicht Teil des Hauptinhalts sind, wie z. B. der Dokumenttyp (z. B. E-Mail oder Webseite), die Dokumentstruktur und Merkmale, wie die Länge des Dokuments, Schlüsselwörter, Autorennamen und das Veröffentlichungsdatum.
- Beschreibung der Links von anderen Seiten zu dieser Seite, die einen kurzen Text über verschiedene Aspekte des Seiteninhalts liefern. Je mehr Links, desto mehr Beschreibungen und desto mehr Spalten werden verwendet. Das Vorhandensein von Links wird auch für das Ranking verwendet, um festzustellen, wie beliebt eine Webseite ist (sehen Sie sich Google’s Pagerank an, ein Ranking-System, das Links zu und von einer Seite verwendet, um Qualität und Popularität zu messen).
- Namen von Personen, Namen von Unternehmen oder Organisationen, Orte, Adressen, Zeit- und Datumsangaben, Mengen und Geldwerte usw. : Algorithmen für maschinelles Lernen können darauf trainiert werden, diese Dateneinheiten in beliebigen Inhalten zu finden, indem sie Trainingsdaten verwenden, die von einem Menschen kommentiert wurden1.
Die vielleicht wichtigste Spalte der Tabelle enthält den Hauptinhalt des Dokuments, der inmitten all der externen Links und Werbeanzeigen identifiziert werden muss. Eine Technik verwendet ein maschinelles Lernmodell, um zu „lernen”, welches der Hauptinhalt einer beliebigen Webseite ist.
Wir können natürlich exakte Wörter aus der Suchanfrage mit den Wörtern in einem Webdokument abgleichen, so wie die Schaltfläche Suchen in jedem Textverarbeitungsprogramm. Dies ist jedoch nicht sehr effektiv, da Menschen unterschiedliche Wörter verwenden, um über dieselbe Sache zu sprechen. Die Aufzeichnung der einzelnen Wörter allein hilft nicht dabei, zu erfassen, wie diese Wörter miteinander verbunden sind und eine Bedeutung ergeben: Es ist letztlich der Gedanke hinter den Wörtern, der uns hilft zu kommunizieren und nicht die Wörter selbst. Daher wandeln alle Suchmaschinen den Text so um, dass er leichter mit der Bedeutung des Abfragetextes übereinstimmt. Später wird die Anfrage auf ähnliche Weise verarbeitet.

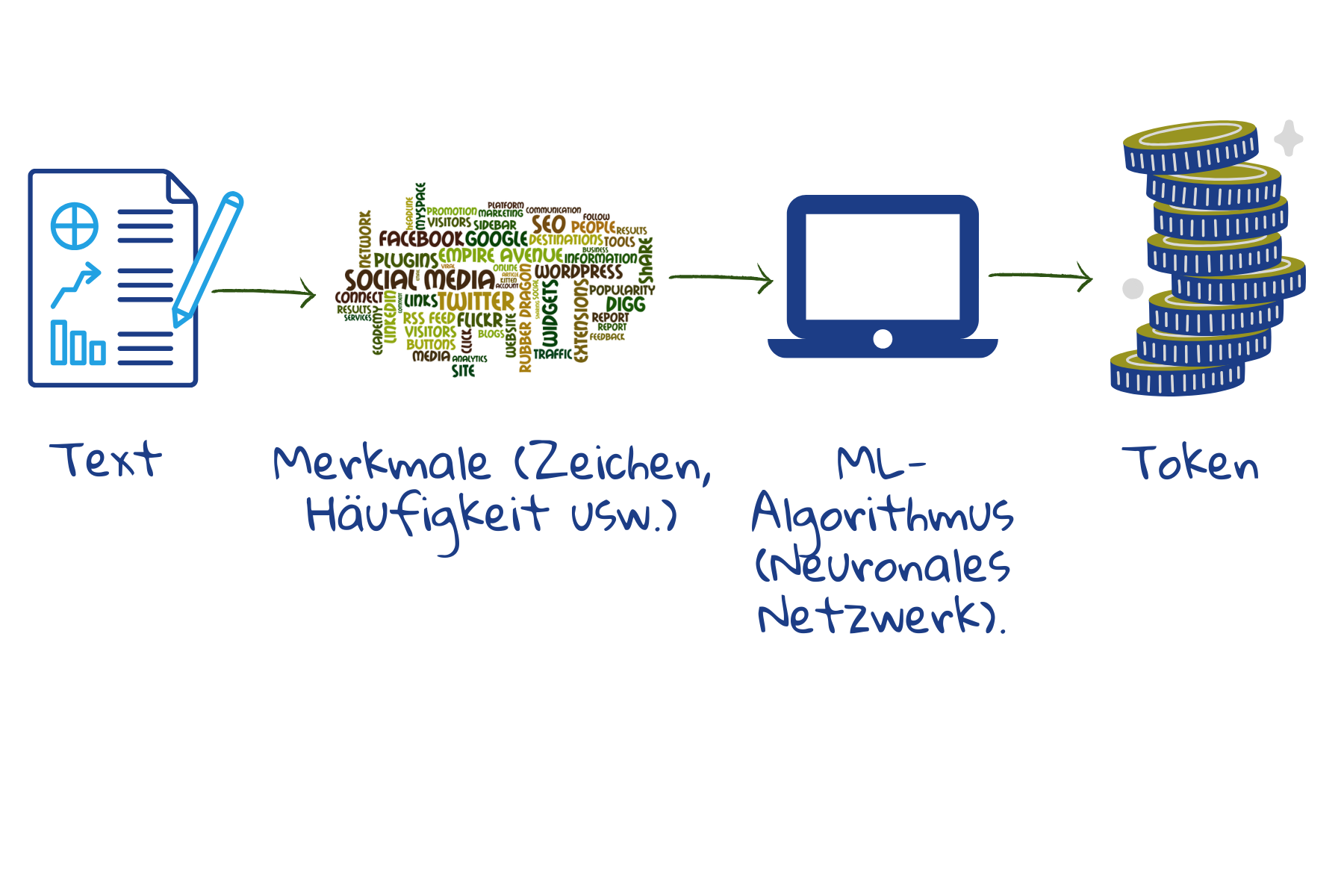
Da es sich um Wortteile handelt, verringert sich die Gesamtzahl der verschiedenen Token, die gespeichert werden müssen. Aktuelle Modelle speichern etwa 30.000 bis 50.000 Token2. Falsch geschriebene Wörter können identifiziert werden, da Teile von ihnen noch mit den gespeicherten Token übereinstimmen. Unbekannte Wörter können zu Suchergebnissen führen, da ihre Teile mit den gespeicherten Token übereinstimmen können.
Die Trainingsmenge für das maschinelle Lernen besteht hier aus Beispieltexten. Ausgehend von einzelnen Zeichen, Leerzeichen und Interpunktion fasst das Modell häufig vorkommende Zeichen zu neuen Token zusammen. Wenn die Anzahl der Token nicht ausreicht, wird der Zusammenführungsprozess fortgesetzt, um größere oder weniger häufige Wortteile abzudecken. Auf diese Weise können die meisten Wörter, Wortendungen und alle Präfixe abgedeckt werden. So kann die Maschine einen neuen Text leicht in Token aufteilen und an den Speicher senden.
Schritt 3: Ein Index wird als einfache Referenz erstellt

Informationen zu dieser Lizenz finden Sie unter: https://creativecommons.org/licenses/by-nd/2.0/?ref=openverse.
Sobald die Daten in BigTables gespeichert sind, wird ein Index erstellt. Ähnlich wie Lehrbuchindizes listet der Suchindex Token und ihre Position in einem Webdokument auf – zusammen mit statistischen Angaben, z. B. wie oft ein Token in einem Dokument vorkommt und wie wichtig es für das Dokument ist sowie Positionsangaben, z. B. ob das Token im Titel oder in einer Überschrift vorkommt, ob es sich auf einen Teil des Dokuments konzentriert und ob ein Token immer auf ein anderes folgt.
Heutzutage verwenden viele Suchmaschinen eine Kombination aus traditioneller Indexierung und sprachbasierten Modellen, die von tiefen neuronalen Netzen (deep neural networks) generiert werden. Letztere kodieren semantische Details des Textes und sorgen für ein besseres Verständnis der Suchanfragen3. Sie helfen den Suchmaschinen, über die Anfrage hinauszugehen, um den Informationsbedarf zu erfassen, der die Abfrage ausgelöst hat.
Diese drei Schritte stellen eine vereinfachte Darstellung dessen dar, was als „Indexierung” bezeichnet wird – das Auffinden, Vorbereiten und Speichern von Dokumenten und die Erstellung eines Index. Als Nächstes folgen die Schritte des „Ranking”, d. h. der Abgleich von Abfrage und Inhalt und die Anzeige der Ergebnisse nach Relevanz.
1 Croft, B., Metzler D., Strohman, T., Search Engines, Information Retrieval in Practice, 2015
2 Sennrich,R., Haddow, B., and Birch, A., Neural Machine Translation of Rare Words with Subword Units, In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1715–1725, Berlin, Germany. Association for Computational Linguistics, 2016.
3 Metzler, D., Tay, Y., Bahri, D., Najork, M., Rethinking Search: Making Domain Experts out of Dilettantes, SIGIR Forum 55, 1, Article 13, June 2021.
