ZUSÄTZLICHER INHALT
Maschinenlernen und KI im Rahmen von Datenexperimenten in Orange
Blaž Zupan
Sind Delphine Säugetiere und wenn ja, warum? Zu welcher Tierart gehört ein Kiwi? Liegen Athen und Rom in derselben Klimazone?
Wer hat das berühmte Gemälde mit einer schreienden Dame gemalt? Malt dieser Künstler den Himmel immer in Orange?
Können wir den Verfasser oder die Verfasserin eines Posts auf Social Media durch seinen oder ihren Schreibstil erkennen? Hat Luka Dončič einen Klon in der NBA, was seinen Spielstil angeht?
Kann man die Art des Baumes anhand seiner Blätter erkennen? Oder anhand eines Fotos seiner Rinde?
Wie lassen sich die Länder der Welt nach ihren sozioökonomischen Merkmalen gruppieren? Ist die Welt tatsächlich sozioökonomisch nach Norden und Süden aufgeteilt?
Welches Landeshauptstadt ähnelt vom Wetter her am ehesten der Hauptstadt Berlin?
Die Datenwissenschaft, insbesondere Methoden des maschinellen Lernens, dient als Katalysator für Veränderungen in verschiedenen Bereichen wie Wissenschaft, Ingenieurwesen und Technologie und hat erhebliche Auswirkungen auf unser tägliches Leben. Computertechniken, die in der Lage sind, umfangreiche Datensätze zu durchkämmen, interessante Muster zu erkennen und Vorhersagemodelle zu erstellen, sind allgegenwärtig. Allerdings verfügen nur wenige Fachleute über ein grundlegendes Verständnis der Datenwissenschaft, und noch weniger sind aktiv an der Erstellung von Modellen aus diesen Daten beteiligt. In einem Zeitalter, in dem KI unsere Welt im Stillen formt, muss sich jeder ihrer Fähigkeiten, Vorteile und potenziellen Risiken bewusst sein. Wir müssen Methoden entwickeln, um die Konzepte der Datenwissenschaft einer breiten Öffentlichkeit wirksam zu vermitteln und zu lehren. Die Grundsätze und Techniken des maschinellen Lernens, der Datenwissenschaft und der künstlichen Intelligenz sollten zum Allgemeinwissen werden.
Jede Frage, die zu Beginn dieses Kapitels gestellt wurde, kann durch die Analyse relevanter Daten beantwortet werden. Wir schlagen einen Ansatz für das Training des maschinellen Lernens vor, bei dem wir mit der Frage beginnen, relevante Daten finden und dann die Frage durch das Finden relevanter Datenmuster und Modelle beantworten. Im Projekt Pumice entwickeln wir pädagogische Aktivitäten, die zur Ergänzung verschiedener Schulfächer eingesetzt werden können. Wir nutzen Daten, die mit dem Thema in Verbindung stehen und untersuchen sie mit Hilfe von KI und maschinellem Lernen. In Zusammenarbeit mit pädagogischen Fachkräften haben wir Lernvorlagen und Hintergrunderklärungen für Lehrende und Lernende entwickelt.
Die Aktivitäten und das Training von Pumice werden von Orange unterstützt, einem Programm für maschinelles Lernen mit einer intuitiven Benutzeroberfläche, interaktiven Visualisierungen und visueller Programmierung. Der Schlüssel zur Einfachheit, die für das Training erforderlich ist und für die Vielseitigkeit, um die meisten Kernthemen abzudecken und an verschiedene Anwendungsbereiche anzupassen, ist der Legostein-ähnliche Aufbau der analytischen Pipelines und die Interaktivität aller Komponenten (siehe Abb. 1). Um den Unterricht weiter zu unterstützen und sich auf Konzepte statt auf die zugrunde liegende Mechanik zu konzentrieren, implementiert Orange einen einfachen Zugang zu Daten, Reproduzierbarkeit durch das Speichern von Arbeitsabläufen mit all den verschiedenen nutzerbasierten Einstellungen und Auswahlmöglichkeiten sowie eine einfache Anpassung durch das Design neuer Komponenten. Ein entscheidender Aspekt des Trainings ist das Storytelling durch die Inspektion von Arbeitsabläufen und speziellen Funktionen für Experimente, wie z. B. das Zeichnen von Versuchsdatensätzen oder das Lernen über die Überanpassung der polynomialen linearen Regression. Orange ist als Open-Source-Software verfügbar und wird durch ein kurzes Schulungsvideo ergänzt.
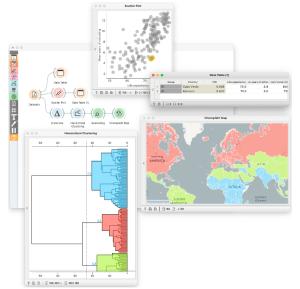
In Abb. 1 zeigen wir einen typischen Workflow der Orange Datenexploration. Der Workflow besteht aus Komponenten, die die Daten laden, die Abstände berechnen, die Daten oder die sich daraus ergebenden Modelle visualisieren oder alle notwendigen Aufgaben durchführen, um Datenmuster zu finden und zu visualisieren. In diesem Workflow haben wir die sozioökonomischen Daten von Ländern der Welt verwendet. Der obere Zweig innerhalb des Workflows untersucht zwei Merkmale und zeigt, dass die Lebenserwartung und die Anzahl der Schuljahre miteinander korrelieren. Es zeigt auch, dass es Länder wie Cabo Verde und Marokko gibt, in denen die Menschen lange leben, aber nicht allzu viel Zeit in der Schule verbringen. Kinder in Schulen können solche Netzwerke entwerfen, um herauszufinden, welche Länder sich sozioökonomisch ähneln und wo sie feststellen können, dass die Welt sozioökonomisch in Nord, Mitte und Süd aufgeteilt ist und dass es eine große Kluft zwischen entwickelten und unterentwickelten Teilen der Welt gibt. Es ist nicht nötig, ihnen dies ausdrücklich zu sagen dank der Auswertung der Daten in Orange können sie dies und werden in den oberen Klassen selbstständig in diese Bereiche eintauchen.
Die Entwicklung von Orange begann im Jahr 2003 und hat seitdem erheblich an Fahrt zugelegt. Mit über 50.000 verschiedenen monatlichen Nutzern hat sich Orange als eine weitverbreitete spezialisierte Softwareanwendung etabliert. Ungefähr die Hälfte der Nutzer kommt aus dem akademischen Bereich. Vor allem im Bildungsbereich hat Orange einen bemerkenswerten Aufschwung erlebt: Mehr als 500 Universitäten auf der ganzen Welt haben die Software in ihre Data-Science-Kurse integriert.
Wenn Sie als Lehrkraft in den Bereich des maschinellen Lernens und der Datenwissenschaft eintauchen möchten, finden Sie hier eine Zusammenstellung von Ressourcen, die eine Einführung in diese Disziplinen durch praktische Datenerforschung mit Orange bieten:
- Die Website der Toolbox Orange
- Eine Einführung in die Datenwissenschaft ist eine Reihe von kurzen Videos, die ausgewählte Visualisierungen und maschinelle Lernmethoden mit Orange vorstellen. Sie finden Videos auf http://youtube.com/orangedatamining und rufen Sie die Wiedergabeliste „Einführung in die Datenwissenschaft” auf.
- Pumice ist eine Website für Lehrkräfte, auf der wir Anwendungsfälle sammeln, die Sie in Ihr Trainingsprogramm einbauen können.
