Henrik Heymann1 and Andrés Boza1![]()
1 Centro de Investigación Gestión e Ingeniería de la Producción (CIGIP),
Universitat Politècnica de València, Valencia, Spain.
henhey@etsii.upv.es, aboza@cigip.upv.es
Keywords: Artificial Intelligence, Machine Learning, Deployment, Manufacturing, Predictive Quality.
1. Introduction and Objectives
The application of artificial intelligence (AI) and machine learning (ML) in production environments offers huge potential for the manufacturing industry, for example by predicting the product quality during the production process. However, deploying ML models into the running process and making prediction results available where they are needed proves to be enormously difficult due to numerous technological but also organizational challenges [1].
As an initial task in deployment, called the deployment design, decision owners need to define the desired ML system architecture. The goal of this paper is to provide a structured guideline for the selection of the most adequate deployment options.
2. Review Method and Results
A gray literature review allows to fully grasp the subject and is a useful technique in dynamic fields of investigation such as software engineering and ML [2]. The results of the review can be structured in form of a morphological box as introduced by Zwicky and Wilson in 1967 [3] which is depicted in Fig. 1.
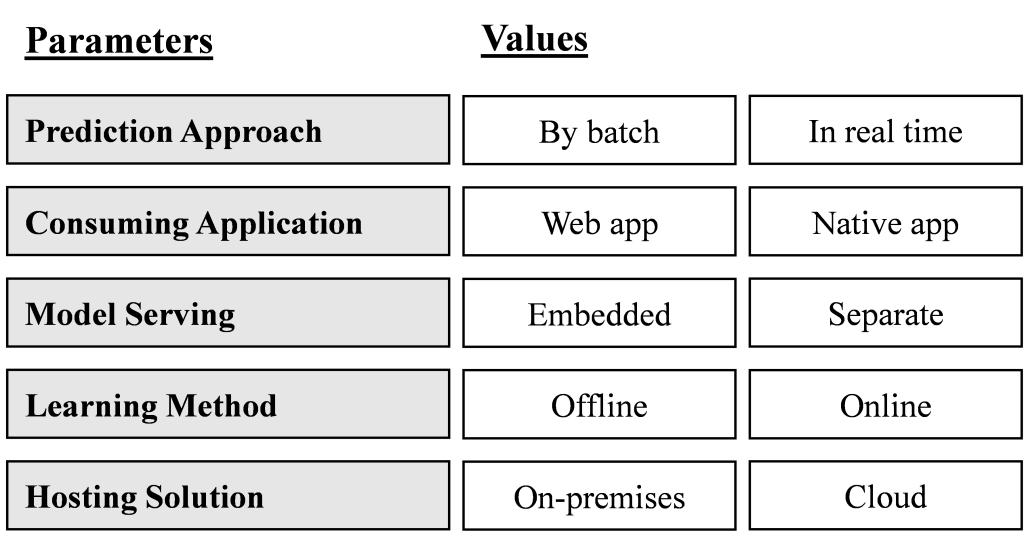
In order to identify the requirements for the ML system architecture, one of the available values for each parameter is selected. Predictions can be made by batch or in real time. Batch predictions are executed at a particular point in time and do not consider live input. In contrast, real time predictions are calculated at the exact required moment triggered either by a user request or by the arrival of new data. The predictions can be consumed by a web app or a native app. Whereas the web app is accessible from any device via browser, a native app is developed for a specific platform and must be installed onto a device. Models can be embedded into the consuming application or can be served separately. The decoupling of model serving and prediction consumption allows more flexibility. Online learning models must be trained continuously on new data and, thus, are more complex to handle than offline learning models which do not require continuous training. Finally, the model can be hosted on-premises within the organization or a cloud service is provided by an external supplier. With respect to hosting, data security is the main concern.
3. Case Study and Outlook
For validating purposes, the methodology is applied in the context of predictive quality considering a representative use case. The results of the case study are discussed based on existing architectures of realized deployments and the experience of industry experts.
As future lines of research, it is to be investigated how further parameters, which are currently not covered, can be included in the concept. Moreover, implications of in-creasing the scope of the methodology to companies outside of the manufacturing industry can be analyzed.
Acknowledgements. This research has been funded by the project entitled NIOTOME (Ref. RTI2018-102020-B-I00) (MCI/AEI/FEDER, UE).
References
- Baier, L., Jöhren, F., Seebacher, S. (2019). Challenges in the Deployment and Operation of Machine Learning in Practice. Twenty-Seventh European Conference on Information Systems (ECIS2019), Stockholm-Uppsala, Sweden.
- Garousi, V., Felderer, M., Mäntylä, M. V. (2019). Guidelines for including grey literature and conducting multivocal literature reviews in software engineering. Information and Software Technology, 106, pp. 101-121.
- Zwicky, F., Wilson, A. G. (1967). New Methods of Thought and Procedure. Contributions to the Symposium on Methodologies, May 22-24, 1967, Pasadena. Springer, New York.
