Recherche d’informations
10 Parlons IA : Indexation des moteurs de recherche
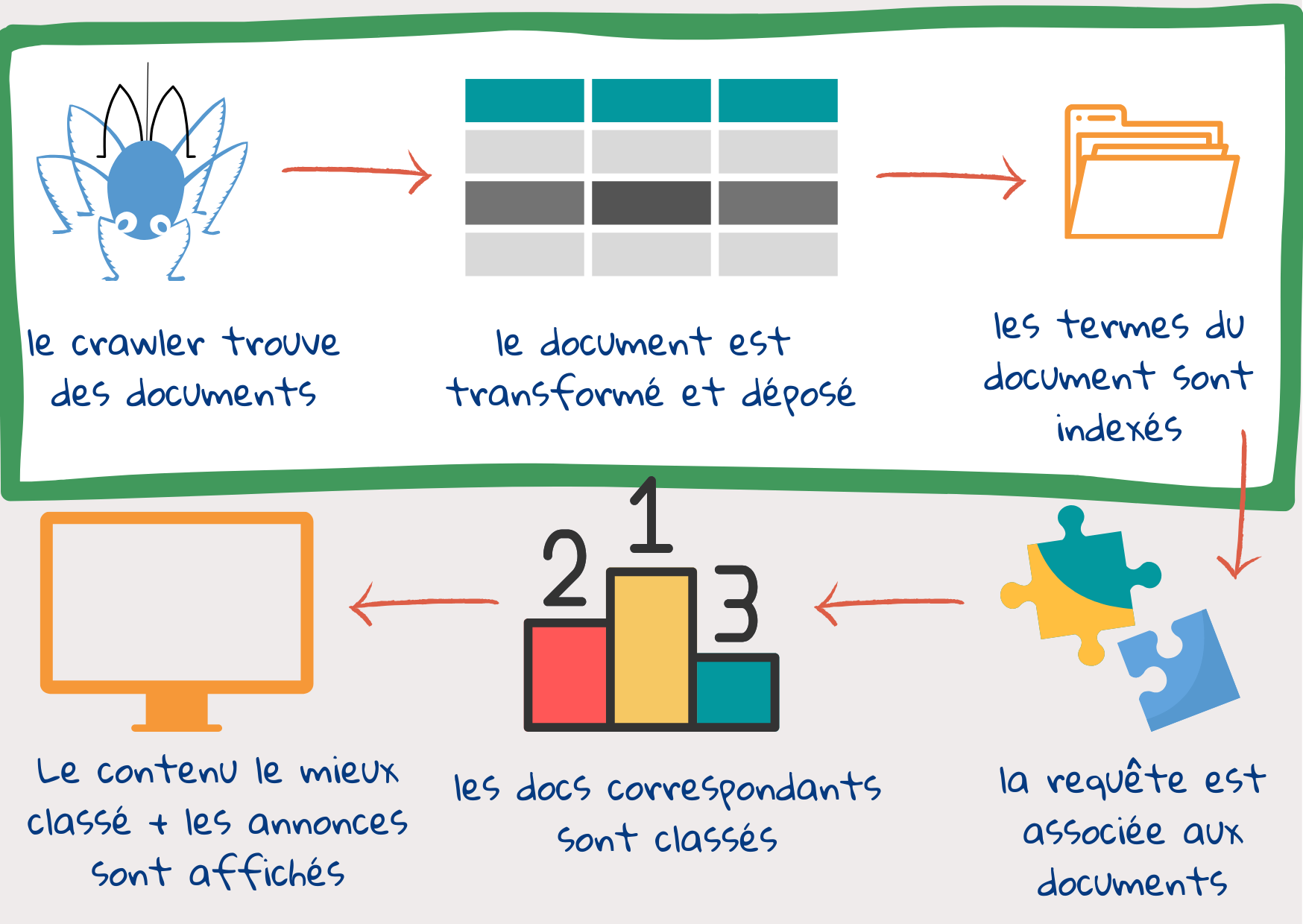
A partir de la requête de l’utilisateur – à savoir des mots-clés saisis dans la fenêtre de recherche – le moteur de recherche tente de trouver, sur le web, des documents susceptibles de satisfaire les besoins d’information de celui-ci. Puis, il les affiche sous une forme facilement accessible, par ordre de pertinence décroissant, avec la page la plus pertinente en tête de liste. Pour ce faire, le moteur de recherche doit commencer par trouver des documents sur le web et les étiqueter de manière à ce qu’ils soient faciles à récupérer. Voyons, dans les grandes lignes, ce qui se passe dans ce processus :
Etape n°1 : les robots d’exploration repèrent et téléchargent des documents.
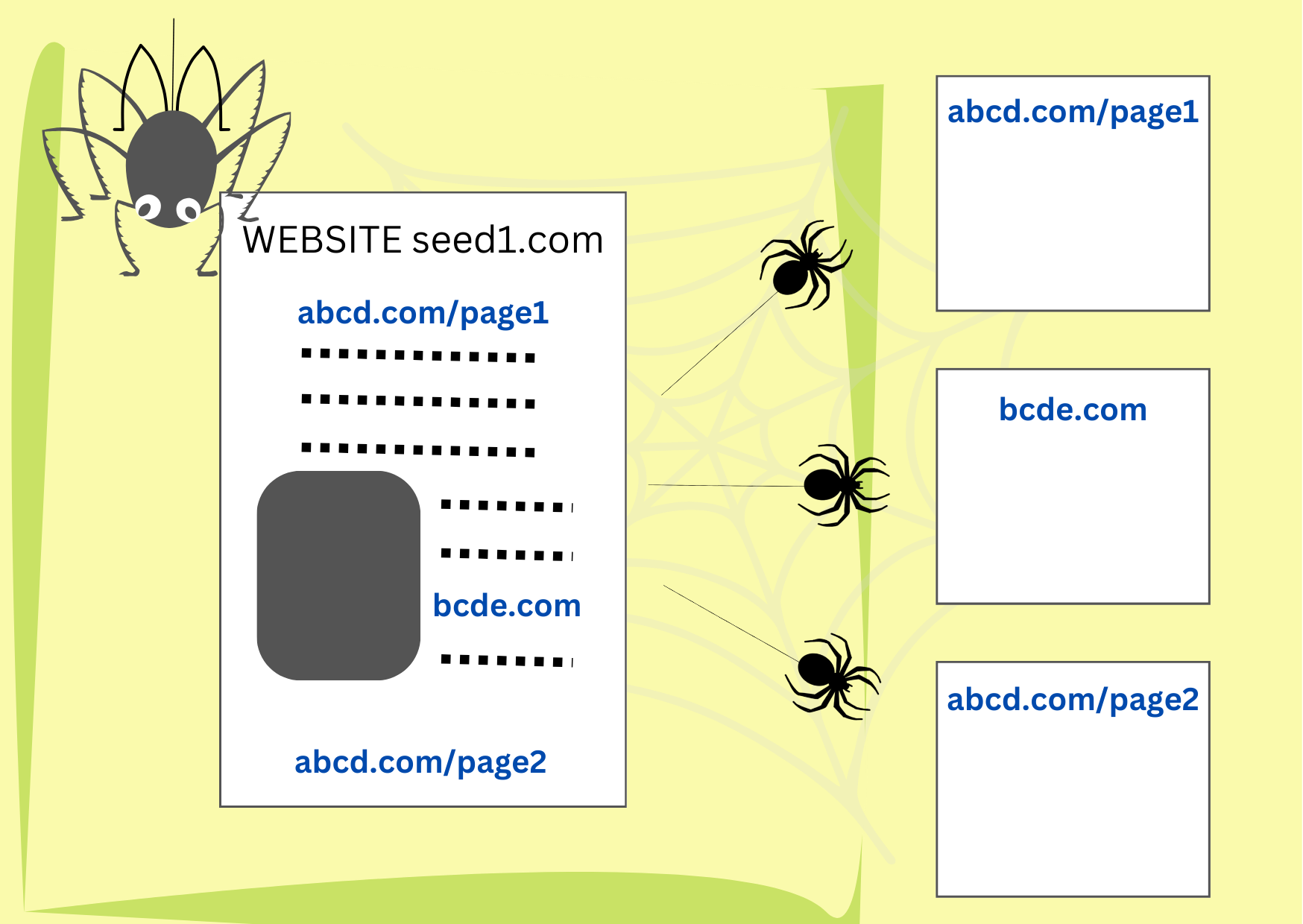
Une fois que l’utilisateur a saisi sa requête, il est trop tard pour aller consulter tous les contenus disponibles surinternet1. Les documents web sont examinés au préalable et leur contenu est ensuite décomposé et stocké à différents emplacements. Une fois que la réponse à la requête est prête, il ne reste plus qu’à associer le contenu de la requête au contenu des emplacements.
Les robots d’exploration sont des éléments de code qui trouvent et téléchargent des documents présents sur le web. Ils commencent par une série d’adresses de sites web (URL) et en examinent le contenu à la recherche de liens vers de nouvelles pages web. Puis, ils téléchargent et examinent le contenu des nouvelles pages à la recherche de nouveaux liens. Si la liste de départ était suffisamment diversifiée, les robots finissent par visiter tous les sites qui leur autorisent l’accès, souvent plusieurs fois, à la recherche de mises à jour.
Etape n° 2 : le document est réparti en plusieurs éléments
 Le document téléchargé par le robot d’exploration peut se présenter comme une page web clairement structurée contenant sa propre description du contenu, le nom de l’auteur, la date etc. Il peut aussi s’agir d’une mauvaise image numérisée d’un vieux livre conservé dans une bibliothèque. Les moteurs de recherche peuvent lire, généralement, une centaine de types de documents différents1.
Le document téléchargé par le robot d’exploration peut se présenter comme une page web clairement structurée contenant sa propre description du contenu, le nom de l’auteur, la date etc. Il peut aussi s’agir d’une mauvaise image numérisée d’un vieux livre conservé dans une bibliothèque. Les moteurs de recherche peuvent lire, généralement, une centaine de types de documents différents1.
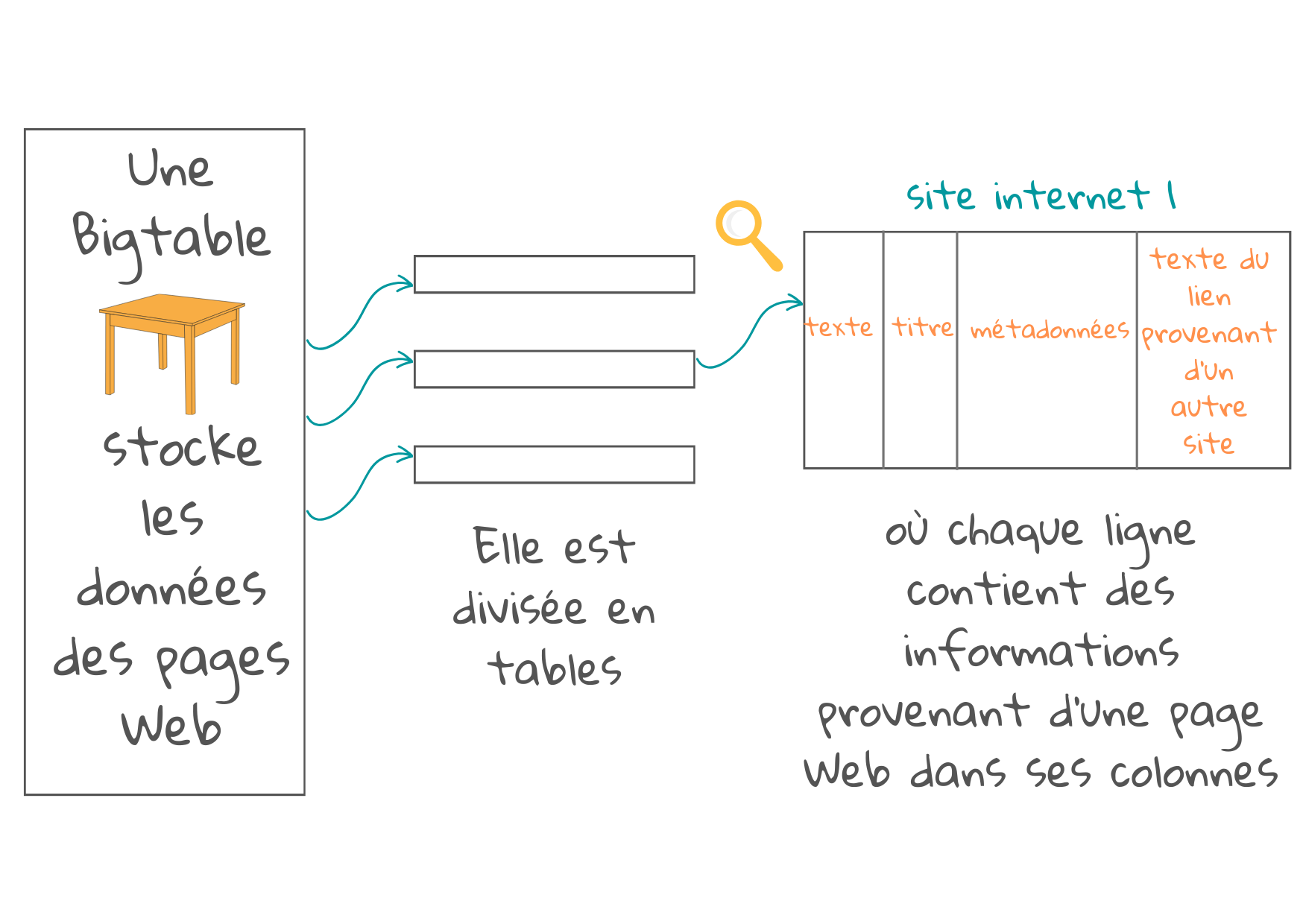
Ils les convertissent au format html ou xml et les stockent dans des tableaux (appelés BigTable dans Google).
Chaque tableau est réparti en plus petits éléments dits « tablettes », dans lesquels chaque rangée de la tablette est consacrée à une page web. Ces rangées sont disposées dans un certain ordre, qui est enregistré, avec un journal pour les mises à jour. Chaque colonne contient une information spécifique relative à la page web, qui peut aider à associer le contenu du document aux contenus d’une future requête. Les colonnes contiennent :
- L’adresse du site web qui peut fournir, déjà, par elle-même, une bonne description du contenu de la page, s’il ‘agit d’une page d’accueil avec un contenu significatif ou d’une page secondaire, avec un contenu associé.
- Les titres, intertitres et mots en caractères gras mettant en évidence les contenus importants.
- Les métadonnées de la page. Il s’agit d’informations relatives à la page ne faisant pas partie du contenu principal, telles que le type de document (par ex. e-mail ou page web), la structure du document et ses caractéristiques, telles que la longueur du document, les mots-clés, les noms des auteurs et la date de publication.
- La description des liens contenus dans d’autres pages vers cette page avec un bref texte décrivant les différents aspects du contenu de la page. Plus il y a de liens plus il y a de descriptions et de colonnes utilisées. La présence de liens est également utilisée pour prioriser, afin de déterminer la popularité d’une page (Cf.Google’s Pagerank, un système de classement basé sur les liens vers et depuis une page pour mesurer la qualité et la popularité de celle-ci).
- Les noms des personnes de la société ou de l’organisation, les lieux, les adresses, l’horodatage, les quantités et les valeurs monétaires etc. Les algorithmes d’apprentissage automatique peuvent être entraînés à détecter ces entités dans tout contenu, à l’aide des données d’entraînement annotées par un être humain1.
Une colonne du tableau, peut-être la plus importante, contient le contenu principal du document, qui doit être identifié parmi les liens externes et les annonces publicitaires. L’une des techniques applicables consiste à employer un modèle d’apprentissage automatique pour “apprendre” à distinguer le contenu principal d’une page web.
Naturellement, nous pouvons rechercher une correspondance entre certains termes précis contenus dans la requête et les termes contenus dans un document web, comme on le fait dans n’importe quel traitement de texte en appuyant sur le bouton Rechercher. Toutefois, ce système n’est pas très efficace, car les gens peuvent utiliser des mots différents pour parler de la même chose. Il ne suffit pas d’enregistrer chaque mot pour saisir de quelle manière ces mots s’associent pour créer du sens : en effet, c’est la pensée qui sous-tend ces mots qui nous aide à communiquer et non pas les mots en tant que tels. Par conséquent, tous les moteurs de recherche transforment le texte de manière à ce qu’il corresponde au sens du texte de la requête. Ensuite, la requête est traitée de manière similaire.

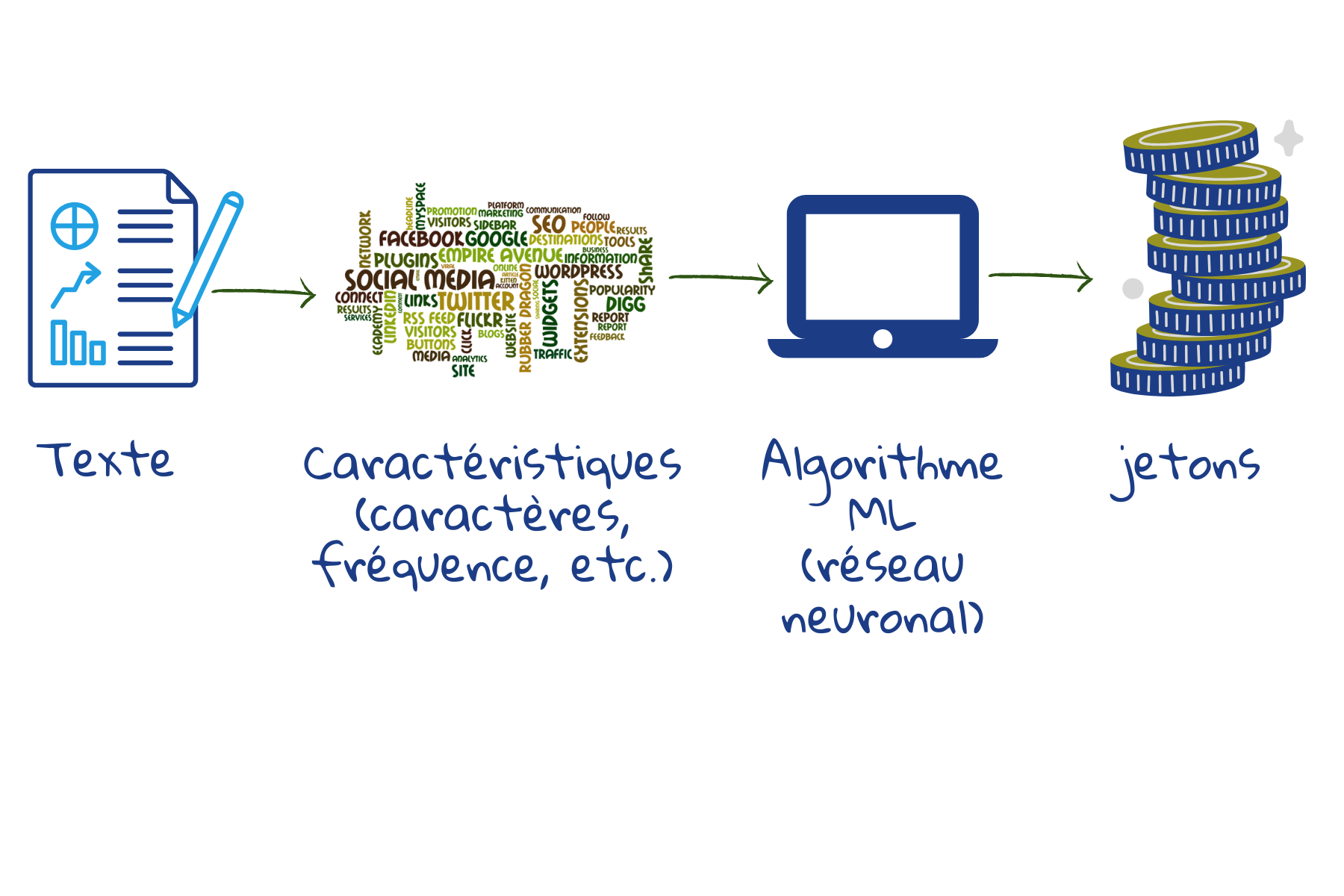
En tant que parties de mots, le nombre total de jetons [tokens] différents qui doivent être stockés est limité. Les modèles actuels peuvent stocker environ 30000 à 50000 jetons2. Les mots mal orthographiés peuvent être identifiés, car certaines parties du mot peuvent correspondre aux jetons stockés. Les mots inconnus peuvent donner lieu à des résultats de recherche, parce que certaines parties du mot peuvent correspondre aux jetons stockés.
Ici les données d’entraînement pour l’apprentissage automatique sont constituées d’exemples de textes. A partir de caractères, espaces et signes de ponctuation, le modèle fusionne les caractères récurrents pour former de nouveaux tokens. Si le nombre de tokens n’est pas suffisamment élevé, le processus de fusion se poursuit pour prendre en compte des parties de mots plus étendues ou moins fréquentes. De cette façon, la plupart des mots, les terminaisons des mots et tous les préfixes peuvent être pris en compte. Par conséquent, quand elle reçoit un nouveau texte, la machine peut aisément le répartir en tokens à stocker.
Etape n° 3 : Un index est créé pour faciliter la consultation

Une fois que les données sont stockées dans BigTables, un index est créé. L’index de recherche, qui est similaire, dans sa forme, à celui des index des manuels scolaires, répertorie les tokens dans un document web, avec leur emplacement et des statistiques – concernant, entre autres, le nombre d’occurrences d’un token dans un document et son importance pour le document – et des informations sur la position – par ex. se trouve-t-il dans le titre ou dans un intertitre, est-il concentré dans une certaine partie du document et un certain token suit-il toujours un autre token.
Actuellement, de nombreux moteurs de recherche combinent un système d’indexation classique et des modèles basés sur le langage générés par des réseaux neuronaux profonds. Ces derniers encodent des détails sémantiques du texte et permettent de mieux comprendre les requêtes3. Ils aident les moteurs de recherche à aller au-delà de la requête pour saisir le besoin d’information qui en est à l’origine.
Ces trois étapes offrent une description simplifiée de ce que l’on appelle “Indexation” : trouver, préparer et stocker des documents et créer un index. Suivent les étapes qui concernent le “Référencement”, qui consiste à trouver une correspondance entre la requête et le contenu et à afficher les résultats selon leur pertinence.
1 Croft, B., Metzler D., Strohman, T., Search Engines, Information Retrieval in Practice, 2015
2 Sennrich,R., Haddow, B., and Birch, A., Neural Machine Translation of Rare Words with Subword Units, In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1715–1725, Berlin, Germany. Association for Computational Linguistics, 2016.
3 Metzler, D., Tay, Y., Bahri, D., Najork, M., Rethinking Search: Making Domain Experts out of Dilettantes, SIGIR Forum 55, 1, Article 13, June 2021.
