Écouter, parler et écrire
30 Parlons IA : Traitement automatique du langage naturel
Le traitement automatique du langage naturel est un sujet sur lequel la recherche a longuement travaillé au cours des 50 dernières années. Cela a conduit au développement de nombreux outils que nous utilisons tous les jours :
- Les logiciels de traitement de texte,
- La correction automatique de la grammaire et de l’orthographe,
- La complétion automatique,
- La reconnaissance optique de caractères (ROC).
Plus récemment, les chatbots, les assistants personnels, les outils de traduction automatique ont eu un impact énorme dans tous les domaines.
Pendant longtemps, la recherche et l’industrie ont été bloquées par la complexité intrinsèque du langage. A la fin du 20e siècle, les grammaires pour une langue, écrites par des experts, pouvaient compter jusqu’à 50 000 règles. Ces systèmes d’experts montraient que la technologie pouvait faire la différence, mais les solutions robustes étaient trop complexes à développer.
D’autre part, la reconnaissance vocale devait être capable d’exploiter les données acoustiques et de les transformer en texte. Avec la variété de locuteurs que l’on pouvait trouver, une tâche très difficile en effet !
Les chercheurs ont compris que si l’on disposait d’un modèle pour la langue visée, les démarches seraient plus faciles : si l’on savait quels étaient les mots de la langue, comment les phrases étaient formées, alors il serait plus facile de trouver la bonne phrase parmi un ensemble de candidats pour correspondre à un énoncé donné, ou de produire une traduction valide à partir d’un ensemble de séquences de mots possibles.
Un autre sujet crucial a été celui de la sémantique. La plupart des travaux que nous pouvons faire pour résoudre les questions linguistiques sont superficiels : les algorithmes produiront une réponse basée sur certaines règles syntaxiques locales. Si, à la fin, le texte ne veut rien dire, qu’il en soit ainsi. Une chose similaire peut se produire lorsque nous lisons un texte de certains élèves : nous pouvons corriger les erreurs sans vraiment comprendre le sens du texte ! Un véritable défi consiste à associer du sens au texte, et lorsque cela est possible, aux phrases prononcées.
En 2008 est arrivé un résultat surprenant1 : un modèle de langue unique pouvait être appris à partir d’une grande quantité de données et utilisé pour une variété de tâches linguistiques. En fait, ce modèle unique obtenait de meilleurs résultats que les modèles formés pour les tâches spécifiques.
Le modèle était un réseau neuronal profond. Pas du tout aussi profond que les modèles utilisés aujourd’hui ! Mais suffisamment pour convaincre la recherche et l’industrie que l’apprentissage automatique, et plus spécifiquement l’apprentissage profond allait être la réponse à de nombreuses questions en TALN.
Depuis lors, le traitement du langage naturel a cessé de suivre une approche axée sur les modèles et a presque toujours été basé sur une approche axée sur les données.
Traditionnellement, les principales tâches linguistiques peuvent être décomposées en 2 familles : celles impliquant la construction de modèles et celles impliquant le décodage.
Construction de modèles
Pour transcrire, répondre à des questions, générer des dialogues ou traduire, il faut pouvoir savoir si « Je parle français » est bien une phrase en français ou non. Et comme avec la langue orale la grammaire n’est pas toujours suivie avec précision, la réponse voudra être probabiliste : une phrase est plus ou moins française. Cela permet au système de produire différentes phrases candidates (comme la transcription d’un son, la traduction d’une phrase) et la probabilité peut être un score. Nous pouvons prendre la phrase la mieux classée ou combiner le score avec d’autres sources d’informations (nous pouvons également nous intéresser au sujet de la phrase).
C’est ce que font les modèles linguistiques : les probabilités sont construites à partir d’algorithmes d’apprentissage automatique. Et bien sûr, plus il y a de données, mieux c’est. Pour certaines langues, il y a beaucoup de données à partir desquelles construire des modèles de langue. Pour d’autres, ce n’est pas le cas : ce sont des langues sous-ressourcées.
Pour le cas de la traduction, nous ne voulons pas 2 mais 3 modèles : un modèle de langue pour chaque langue et un autre modèle pour les traductions, nous informant de ce que peuvent être les meilleures traductions de fragments de langue. Ces modèles sont difficiles à produire lorsque les données sont rares. Si les modèles pour les paires de langues communes sont plus faciles à construire, ce ne sera pas le cas pour les langues qui ne sont pas fréquemment parlées ensemble (disons le portugais et le slovène). Une solution typique consiste à utiliser une langue pivot (typiquement l’anglais) et à traduire via cette langue pivot : du portugais à l’anglais, puis de l’anglais au slovène. Ce qui conduit évidemment à des résultats inférieurs au fur et à mesure que les erreurs s’accumulent.
Décodage
Le décodage est le processus par lequel un algorithme prend la séquence d’entrée (qui peut être un signal ou un texte) et, en consultant les modèles, prend une décision, qui sera souvent un texte de sortie. Il y a ici quelques considérations algorithmiques : dans de nombreux cas, la transcription et la traduction doivent se faire en temps réel et la diminution du décalage est une question clé. Il y a donc de la place pour beaucoup d’intelligence artificielle.
De bout en bout
De nos jours, l’approche consistant à construire ces composants séparément et à les combiner plus tard a été remplacée par des approches de bout en bout (end to end) dans lesquelles le système va transcrire/traduire/interpréter l’entrée à travers un modèle unique. Actuellement, de tels modèles sont formés par des réseaux neuronaux profonds qui peuvent être énormes : on rapporte que le plus grand modèle actuel de GPT3 comprend plusieurs centaines de millions de paramètres !
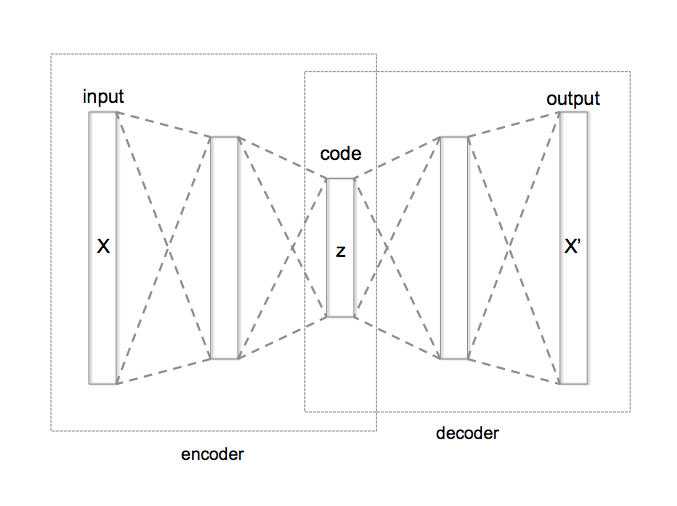
Essayons d’en saisir l’intuition : supposons que nous ayons des données. Ces données brutes peuvent être encodées d’une certaine manière. Mais l’encodage peut être très redondant, et peut-être même coûteux. Construisons maintenant une machine particulière appelée auto-encodeur (voir le schéma ci-dessous). Cette machine sera capable de prendre un texte, de le compresser en un petit vecteur (c’est l’encodeur), puis de décompresser le vecteur (la partie décodeur) et de restituer un texte qui est en quelque sorte proche du texte original. L’idée est que ce mécanisme rendra le vecteur intermédiaire très significatif avec deux propriétés souhaitables : un vecteur raisonnablement petit « contenant » les informations du texte initial.
L’avenir
Un exemple de bout-en-bout que nous verrons bientôt sera capable d’effectuer la tâche suivante : il vous entendra parler votre langue, transcrira votre texte, le traduira dans une langue que vous ne connaissez pas, entraînera un système de synthèse vocale à votre voix et fera en sorte que votre propre voix prononce le texte correspondant dans une nouvelle phrase. Voici deux exemples produits par des chercheurs de l’Universidad Politecnica de Valencia, en Espagne, dans lesquels le modèle vocal du locuteur est utilisé pour effectuer le doublage.
Quelques conséquences pour l’éducation
Les progrès constants du traitement automatique des langues naturelles sont remarquables. Là où nous nous moquions des traductions stupides proposées par l’IA il y a seulement 10 ans, il devient de plus en plus difficile de trouver des erreurs grossières aujourd’hui. Les techniques de reconnaissance vocale et de reconnaissance de caractères s’améliorent également rapidement.
Les défis sémantiques sont toujours là et répondre à des questions qui nécessitent une compréhension profonde d’un texte ne fonctionne toujours pas correctement. Mais les choses vont dans la bonne direction. Ce qui signifie que l’enseignant doit s’attendre à ce que certaines des affirmations suivantes soient bientôt vraies, si elles ne le sont pas déjà !
- un élève prendra un texte complexe et en obtiendra (avec l’IA) une version simplifiée ; le texte pourra même être personnalisé et utiliser des termes, des mots et des concepts auxquels l’élève est habitué ;
- un élève pourra prendre un texte et obtenir un texte disant les mêmes choses mais indétectable par un outil anti-plagiat ;
- des vidéos produites partout dans le monde seront accessibles par doublage automatique dans n’importe quelle langue : cela signifie notamment que nos élèves ne seront pas seulement exposés à du matériel d’apprentissage construit dans notre langue, mais aussi par du matériel initialement conçu pour un autre système d’apprentissage, une autre culture ;
- construire des essais pourrait devenir une tâche du passé car les outils permettront d’écrire sur n’importe quel sujet.
Dans ces exemples, il est clair que l’IA sera loin d’être parfaite et que l’expert détectera que si le langage est correct, le flux d’idées ne l’est pas. Mais regardons les choses en face : au cours de l’enseignement, combien de temps faut-il à nos élèves et étudiants pour atteindre ce niveau ?
1 Collobert, Ronan, et Jason Weston. » A unified architecture for natural language processing : Deep neural networks with multitask learning« . Actes de la 25e conférence internationale sur l’apprentissage automatique. 2008. http://machinelearning.org/archive/icml2008/papers/391.pdf. Remarque : cette référence est donnée pour des raisons historiques. Mais elle est difficile à lire !
