Écouter, parler et écrire
29 Parlons IA : Réseaux Neuronaux Profonds
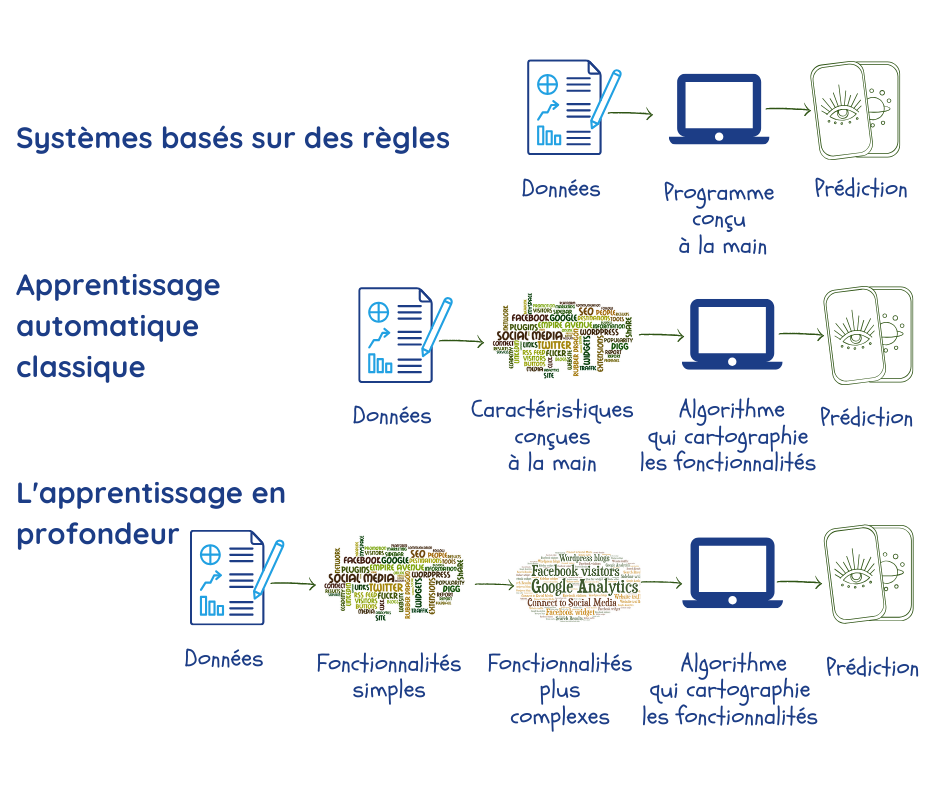
L’apprentissage automatique profond
La connaissance humaine est vaste et variable et est intrinsèquement difficile à capturer.
L’esprit humain peut absorber la connaissance et l’élaborer, car, comme l’a dit Chomsky, “ C’est un système étonnamment efficace et même raffiné qui fonctionne avec de petites quantités d’informations ; il ne cherche pas à déduire des corrélations sommaires à partir de données, mais à élaborer des explications.”
L’apprentissage automatique est censé faire cela en découvrant des modèles dans de vastes ensembles de données. Toutefois, avant cela, des experts et des programmeurs doivent encoder les caractéristiques des données qui sont pertinentes pour répondre au problème en question et doivent les introduire dans la machine sous la forme de “paramètres”2,3. Comme nous l’avons déjà vu auparavant, les performances dépendent en grande partie de la qualité des données et de ces paramètres, qui ne sont pas toujours faciles à cerner.
Les réseaux neuronaux profonds ou Deep Learning sont une branche de l’Apprentissage Automatique qui a été expressément conçue pour surmonter ces problèmes :
- en extrayant des données ses propres paramètres pendant la phase d’entraînement ;
- en utilisant de multiples couches qui créent des relations entre les paramètres, en allant progressivement de simples représentations dans la couche la plus externe à de représentations plus complexes et plus abstraites dans les couches internes. Ceci permet au Deep Learning de mieux faire certaines choses que les algorithmes conventionnels d’apprentissage automatique2.
La plupart des applications les plus puissantes d’apprentissage automatique utilisent de plus en plus souvent le Deep Learning. Parmi celles-ci, les moteurs de recherche, les systèmes de recommandation, de transcription de discours et de traduction que nous avons traités dans ce manuel. Il ne serait pas exagéré d’affirmer que le Deep Learning a propulsé le succès de l’Intelligence Artificielle dans de multiples tâches.
Le terme “profond” se rapporte à la manière dont les différentes couches s’empilent les unes sur les autres pour créer le réseau. Le terme “neuronaux” désigne le fait que certains aspects de la structure s’inspirent du cerveau biologique. Malgré cela, et même s’ils fournissent certaines informations sur nos processus mentaux, il s’agit de modèles strictement mathématiques, qui ne ressemblent nullement à des processus ou à des éléments biologiques2.
Les bases du Deep Learning
Lorsque nous regardons une image, nous identifions automatiquement les objets et les visages, mais, pour un algorithme, une photo est un simple ensemble de pixels. La transition d’un mélange de couleurs et de niveaux de luminosité à la reconnaissance d’un visage est un saut trop complexe à exécuter.
Le Deep Learning y parvient en décomposant le processus en représentations très simples sur la première couche–en comparant, disons, la luminosité des pixels qui se côtoient pour noter la présence ou l‘absence de bords dans différentes parties de l’image. La deuxième couche prend en considération des ensembles de bords pour rechercher des entités plus complexes, comme les angles et les contours,en ignorant de petites variations dans le positionnement2,3 des bords.
La couche suivante recherche des éléments des objets à l’aide des contours et des angles. Petit à petit, l’image devient plus complexe jusqu’à ce que, dans la dernière couche, les différentes parties se combinent de manière suffisamment claire pour faire apparaître un visage ou un objet.
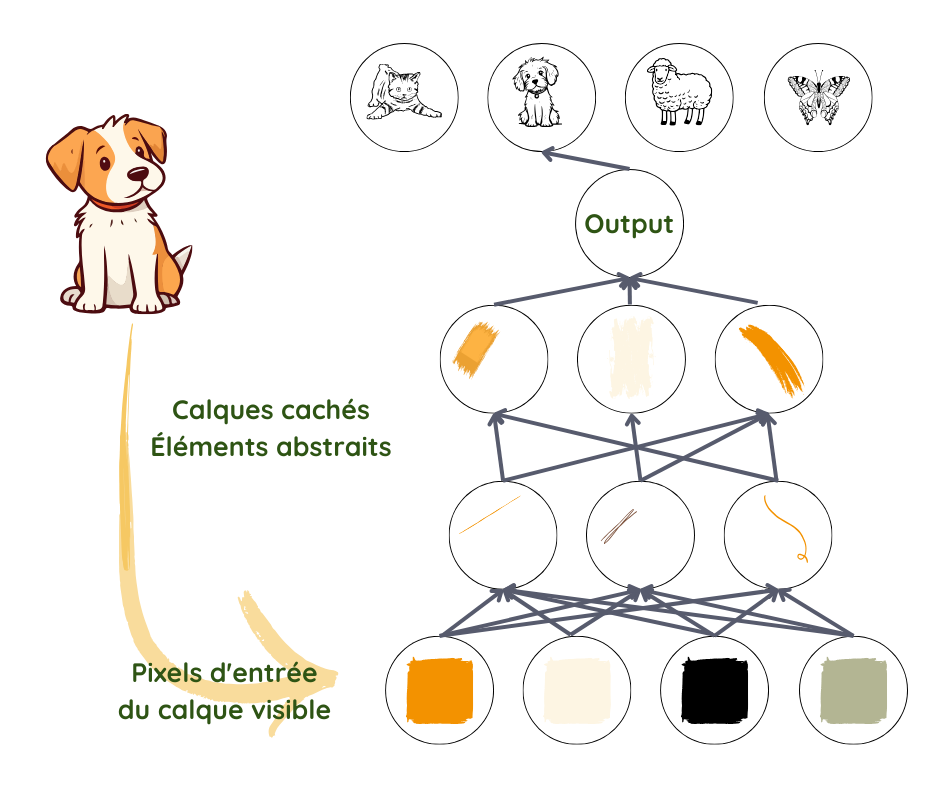 Ce qui doit être pris en compte dans chaque couche n’est pas spécifié par les programmeurs ; il est appris à partir des données pendant le processus d’entraînement3. En testant ces prédictions par rapport aux résultats réels dans l’ensemble de données d’entraînement, le fonctionnement de chaque couche est ajusté de manière légèrement différente pour obtenir, chaque fois, un résultat légèrement plus précis. Lorsque ce processus se déroule correctement, et à condition qu’un volume suffisant de données de bonne qualité soit disponible, le réseau doit évoluer pour ignorer les éléments non pertinents de la photo, tels que la position exacte des entités, des angles et de la lumière et se concentrer sur les éléments qui rendent l’identification possible.
Ce qui doit être pris en compte dans chaque couche n’est pas spécifié par les programmeurs ; il est appris à partir des données pendant le processus d’entraînement3. En testant ces prédictions par rapport aux résultats réels dans l’ensemble de données d’entraînement, le fonctionnement de chaque couche est ajusté de manière légèrement différente pour obtenir, chaque fois, un résultat légèrement plus précis. Lorsque ce processus se déroule correctement, et à condition qu’un volume suffisant de données de bonne qualité soit disponible, le réseau doit évoluer pour ignorer les éléments non pertinents de la photo, tels que la position exacte des entités, des angles et de la lumière et se concentrer sur les éléments qui rendent l’identification possible.
Il est à noter, ici, que malgré notre utilisation des bords et des contours pour comprendre le processus, ce qui est réellement représenté dans les différentes couches est une série de nombres, qui peuvent correspondre ou ne pas correspondre à des choses compréhensibles pour nous. La complexité et l’abstraction croissante, en revanche, ne changent pas.
Conception du réseau
Une fois que le programmeur a décidé de recourir au Deep Learning pour exécuter une certaine tâche et qu’il a préparé les données, il doit concevoir ce que l’on appelle l’architecture du réseau neuronal. Il doit choisir le nombre de couches (profondeur du réseau) et le nombre de paramètres par couche (largeur du réseau). Puis, il doit décider comment connecter les différentes couches, à savoir si chaque unité d’une couche doit être connectée ou non à chaque unité de la couche précédente.
L’architecture idéale pour une certaine tâche est souvent le fruit d’une expérimentation. Le nombre de paramètres nécessaires par couche est d’autant moins élevé que le nombre de couches est important et le réseau fonctionne mieux avec des données générales, au prix d’une difficulté d’optimisation. Moins de connections peut signifier moins de paramètres et moins de calculs, mais cela réduit la flexibilité du réseau2.
Entraînement du réseau
Prenons, par exemple, un réseau neuronal à avance directe qui effectue un apprentissage supervisé. Dans celui-ci, les informations avancent en passant d’une couche à une autre couche plus profonde, sans boucle de rétroaction. Tout comme pour toutes les techniques d’apprentissage automatique, il s’agit de découvrir de quelle manière les données saisies sont reliées au résultat obtenu : quels paramètres entrent en jeu et de quelle manière ils s’associent pour fournir le résultat observé. Nous partons d’une relation f qui relie les données x au résultat y. Puis, nous utilisons le réseau pour trouver l’ensemble de paramètres θ qui offre la meilleure correspondance entre les résultats prédits et les résultats réels.
Question clé : si la valeur prédite y est f(x, θ), que vaut θ ?
La prédiction pour y correspond ici au produit final et l’ensemble de données x correspond à l’input. Dans la reconnaissance faciale, x représente généralement l’ensemble de pixels contenu dans une image, tandis que y peur représenter le nom de la personne. Dans le réseau, les couches sont comme les ouvriers sur une chaîne d’assemblage, où chaque ouvrier effectue la tâche qui lui a été assignée et passe la pièce à l’ouvrier suivant. Le premier ouvrier prend la pièce qu’on lui donne et la transforme partiellement pour la passer au deuxième ouvrier sur la chaîne. Le deuxième fait la même chose et passe la pièce au troisième ouvrier et ainsi de suite jusqu’à ce que l’on obtienne le produit fini.
D’un point de vue mathématique, la fonction f est répartie en plusieurs fonctions f1, f2, f3… où f= ….f3(f2(f1(x))). La couche proche des données d’entrée transforme les paramètres d’entrée à l’aide de f1, la couche suivante à l’aide de f2 et ainsi de suite. Le programmeur peut intervenir pour aider à choisir la bonne famille de fonctions, selon sa connaissance du problème.
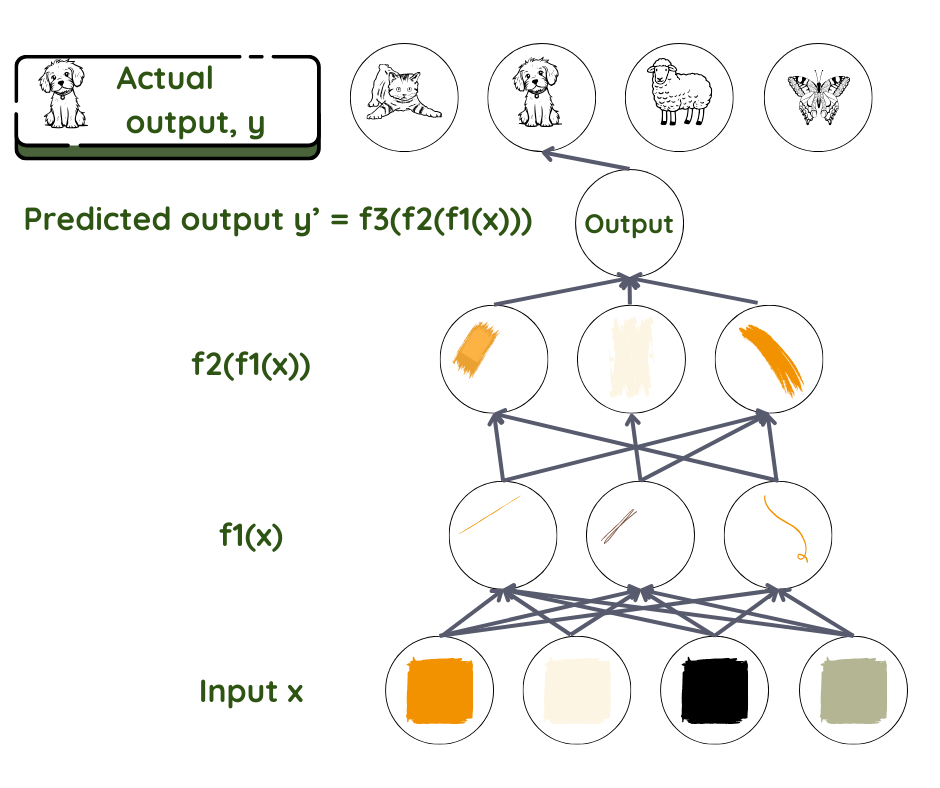
Le travail de chaque couche consiste à attribuer le niveau d’importance, à savoir le poids à attribuer à chaque paramètre reçu. Ces poids sont comme des boutons qui définissent, en dernier lieu, la relation entre le résultat prédit et les données d’entrée de cette couche3. Dans un système typique de deep learning, nous avons des centaines de millions d’exemples d’entraînement. Puisque nous ne définissons pas et ne pouvons pas voir les résultats et les poids dans les différentes couches entre l’entrée et la sortie, celles-ci sont appelées « couches cachées ».
Dans le cas de la reconnaissance d’objet décrite ci-dessus, le premier ouvrier doit détecter les bords et doit les passer au deuxième ouvrier qui va détecter les contours, et ainsi de suite.
Pendant l’entraînement, le résultat prévu est comparé au résultat réel. En cas de différence importante entre les deux, les poids attribués dans chaque couche devront être modifiés de manière significative. Dans le cas contraire, ils devront être légèrement modifiés. Ce travail a lieu en deux temps. Tout d’abord, la différence entre la prédiction et le résultat est calculée, puis un autre algorithme calcule comment modifier les poids dans chaque couche, en commençant par la couche externe (Dans ce cas, l’ information circule en sens inverse, à partir des couches les plus profondes). Par conséquent, au terme du processus d’entraînement, le réseau est prêt, avec ses poids et ses fonctions, à s’attaquer aux données de test. Le reste du processus est identique à celui d’apprentissage automatique conventionnel.
1 Chomsky, N., Roberts, I., Watumull, J., Noam Chomsky: The False Promise of ChatGPT, The New York Times, 2023.
2 Goodfellow, I.J., Bengio, Y., Courville, A., Deep Learning, MIT Press, 2016.
3 LeCun, Y., Bengio, Y., Hinton, G., Deep learning, Nature 521, 436–444 (2015).
