Recherche d’informations
11 Parlons IA : Classement par les moteurs de recherche
Par rapport aux moteurs de recherche au début des années 2000, les moteurs de recherche actuels font une analyse plus riche et plus profonde. Par exemple, plus que de compter les mots, ils peuvent analyser et comparer la signification derrière les mots1. Une grande partie de cette richesse se produit dans le processus de classement :
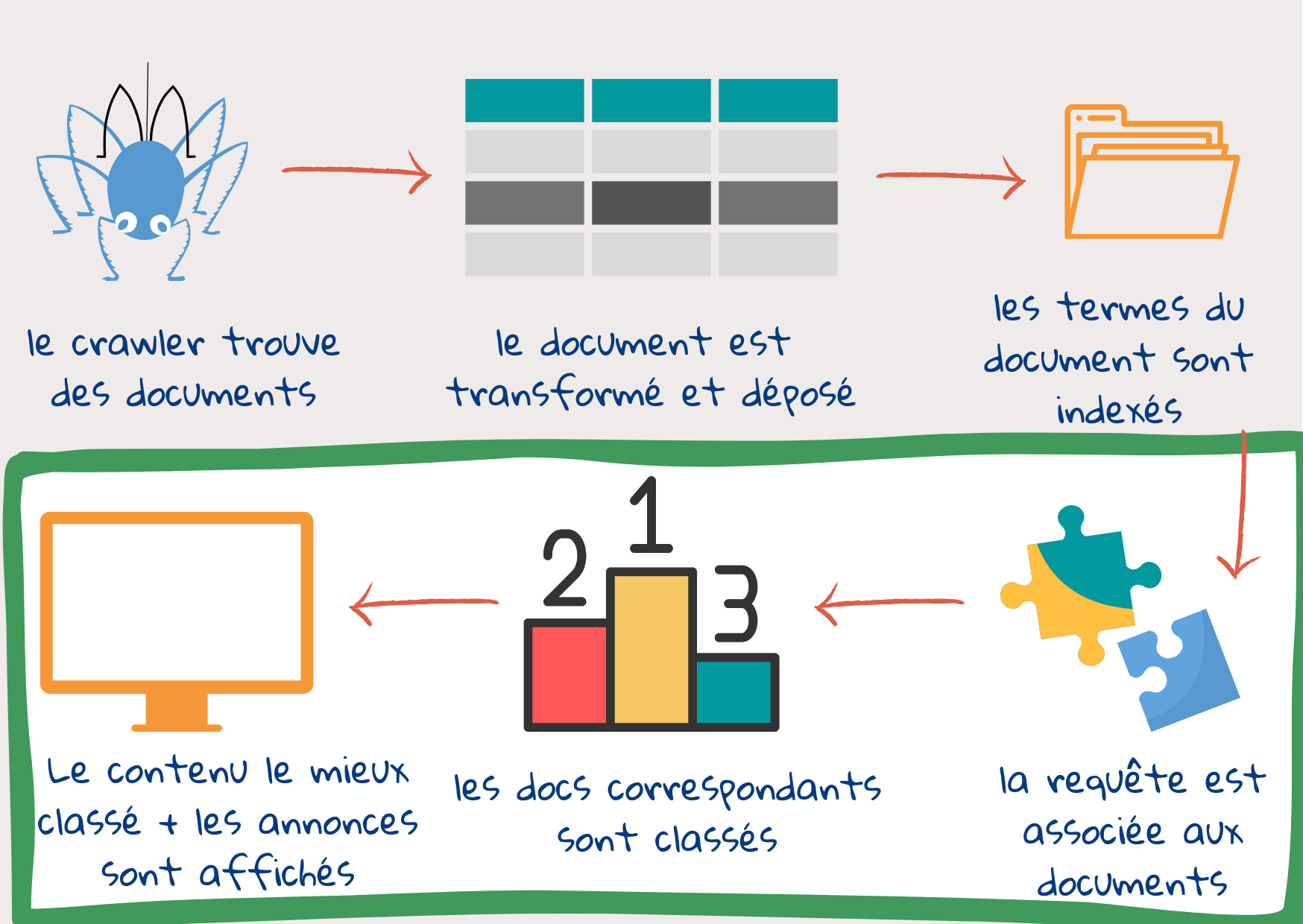
Étape 4 : Les termes de la requête sont associés aux termes de l’index

Une fois que l’utilisateur a saisi la requête et a cliqué sur le bouton de recherche, la requête est traitée. Les tokens sont créés avec le même processus que le texte du document. Ensuite, la requête peut être élargie en ajoutant d’autres mots-clés. Cela permet d’éviter le cas où des documents pertinents ne sont pas trouvés parce que la requête utilise des mots légèrement différents de ceux des auteurs du contenu Web. Ceci est également fait pour prendre en compte les différences d’usage et de coutume. Par exemple, l’utilisation de mots comme Président, Premier ministre et Chancelier peut être interchangée selon le pays1.
La plupart des moteurs de recherche gardent une trace des recherches des utilisateurs (Regardez la description de certains moteurs de recherche populaires pour en savoir plus). Les requêtes sont enregistrées avec les données de l’utilisateur afin de personnaliser le contenu et de servir des publicités. Ou bien, les enregistrements de tous les utilisateurs sont rassemblés pour voir comment et où améliorer les performances des moteurs de recherche.
Les historiques des utilisateurs contiennent les requêtes précédentes, la page de résultats et des informations sur ce qui a fonctionné – ce sur quoi l’utilisateur a cliqué et ce qu’il a passé du temps à lire. Avec les historiques des utilisateurs, chaque requête peut être mise en correspondance avec des documents pertinents (l’utilisateur a cliqué, lu et fermé la session) et des documents non pertinents (l’utilisateur n’a pas cliqué ou n’a pas lu ou a essayé de reformuler la requête)2.
Avec ces logs, chaque nouvelle requête peut être mise en correspondance avec une requête passée qui est similaire. Une façon de savoir si une requête est similaire à une autre est de voir si le classement fait apparaître les mêmes documents : les requêtes similaires ne contiennent pas toujours les mêmes mots mais les résultats sont susceptibles d’être identiques2.
Les fautes d’orthographe peuvent être corrigées en utilisant des requêtes similaires. De nouveaux mots clés et synonymes peuvent être ajoutés pour élargir la requête. Pour ce faire, on examine d’autres mots qui apparaissent fréquemment dans les documents pertinents du passé. En général, cependant, les mots qui apparaissent plus fréquemment dans les documents pertinents que dans les documents non pertinents sont ajoutés à la requête ou se voient accorder une pondération supplémentaire2.
Étape 5 : Les documents pertinents sont classés
Chaque document est évalué pour sa pertinence et classé en fonction de ce score. La pertinence est ici à la fois la pertinence du sujet – dans quelle mesure les termes d’indexation d’un document correspondent à ceux de la requête, et la pertinence de l’utilisateur – dans quelle mesure il correspond aux préférences de l’utilisateur. Une partie de cette évaluation des documents peut être effectuée pendant l’indexation. La vitesse du moteur de recherche dépend de la qualité des index. Son efficacité repose sur la façon dont la requête est associée au document et sur le système de classement2.
 La pertinence pour l’utilisateur est déterminée en créant des modèles d’utilisateurs (ou types de personnalité) basés sur leurs anciens termes de recherche, les sites visités, les courriels, l’appareil qu’ils utilisent, leur langue et leur localisation géographique. Cookies sont utilisés pour enregistrer les préférences des utilisateurs. Certains moteurs de recherche achètent également des informations sur les utilisateurs auprès de tiers (voir description de certains moteurs de recherche). Si quelqu’un s’intéresse au football, ses résultats pour “Manchester » ; seront différents de ceux qui viennent de réserver un vol pour Londres. Les mots qui apparaissent fréquemment dans les documents associés à une personne se verront accorder la plus grande importance.
La pertinence pour l’utilisateur est déterminée en créant des modèles d’utilisateurs (ou types de personnalité) basés sur leurs anciens termes de recherche, les sites visités, les courriels, l’appareil qu’ils utilisent, leur langue et leur localisation géographique. Cookies sont utilisés pour enregistrer les préférences des utilisateurs. Certains moteurs de recherche achètent également des informations sur les utilisateurs auprès de tiers (voir description de certains moteurs de recherche). Si quelqu’un s’intéresse au football, ses résultats pour “Manchester » ; seront différents de ceux qui viennent de réserver un vol pour Londres. Les mots qui apparaissent fréquemment dans les documents associés à une personne se verront accorder la plus grande importance.
Les moteurs de recherche web commerciaux intègrent des centaines de caractéristiques dans leurs algorithmes de classement, dont beaucoup proviennent de l’énorme collection de données d’interaction des utilisateurs dans les historiques de requêtes. La fonction de classement combine le document, la requête et les éléments de pertinence pour l’utilisateur. Quelle que soit la fonction de classement utilisée, elle doit reposer sur une base mathématique robuste. La sortie est la probabilité qu’un document réponde au besoin de renseignements de l’utilisateur. Au-delà d’une certaine probabilité de pertinence, le document est classé comme étant utile2.
L’apprentissage automatique est utilisé pour apprendre le classement sur la base des retours implicites des utilisateurs dans les historiques (ce qui a fonctionné dans les requêtes précédentes). L’apprentissage automatique est également utilisé pour développer des modèles sophistiqués de la façon dont les humains utilisent le langage avec lesquels il est possible de déchiffrer les requêtes1,2.
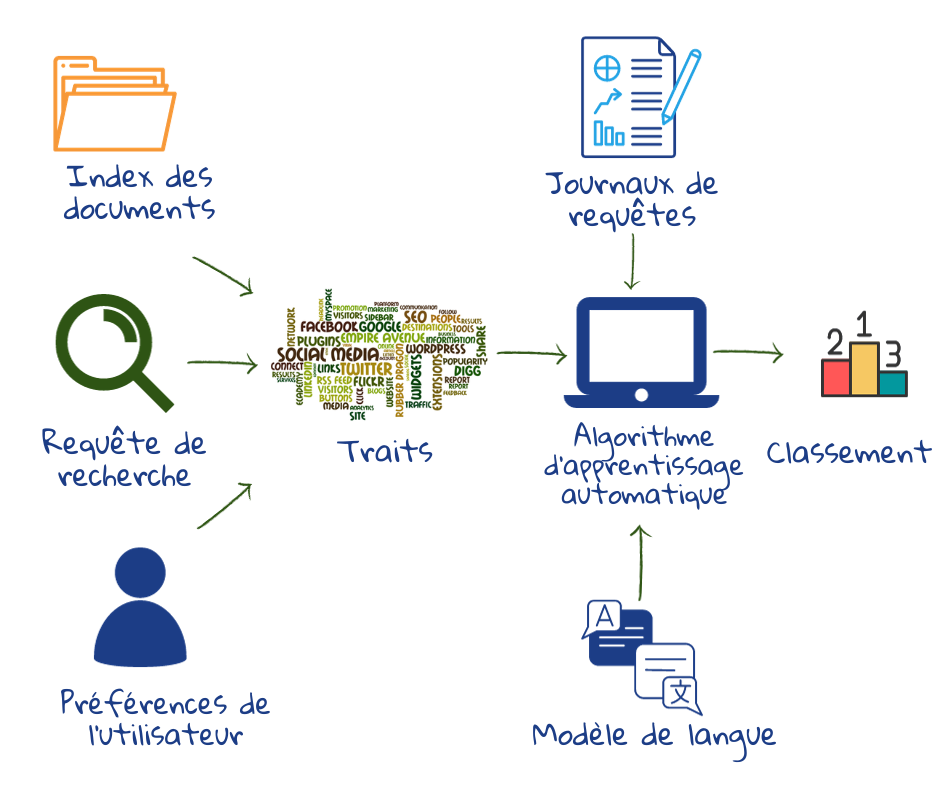
Les progrès de la recherche web ont été phénoménaux au cours de la dernière décennie. Cependant, lorsqu’il s’agit de comprendre le contexte d’une requête spécifique, rien ne remplace l’utilisateur qui fournit une meilleure requête. Généralement, les meilleures requêtes proviennent des utilisateurs qui examinent les résultats et reformulent la requête2.
Étape 6 : Les résultats sont affichés
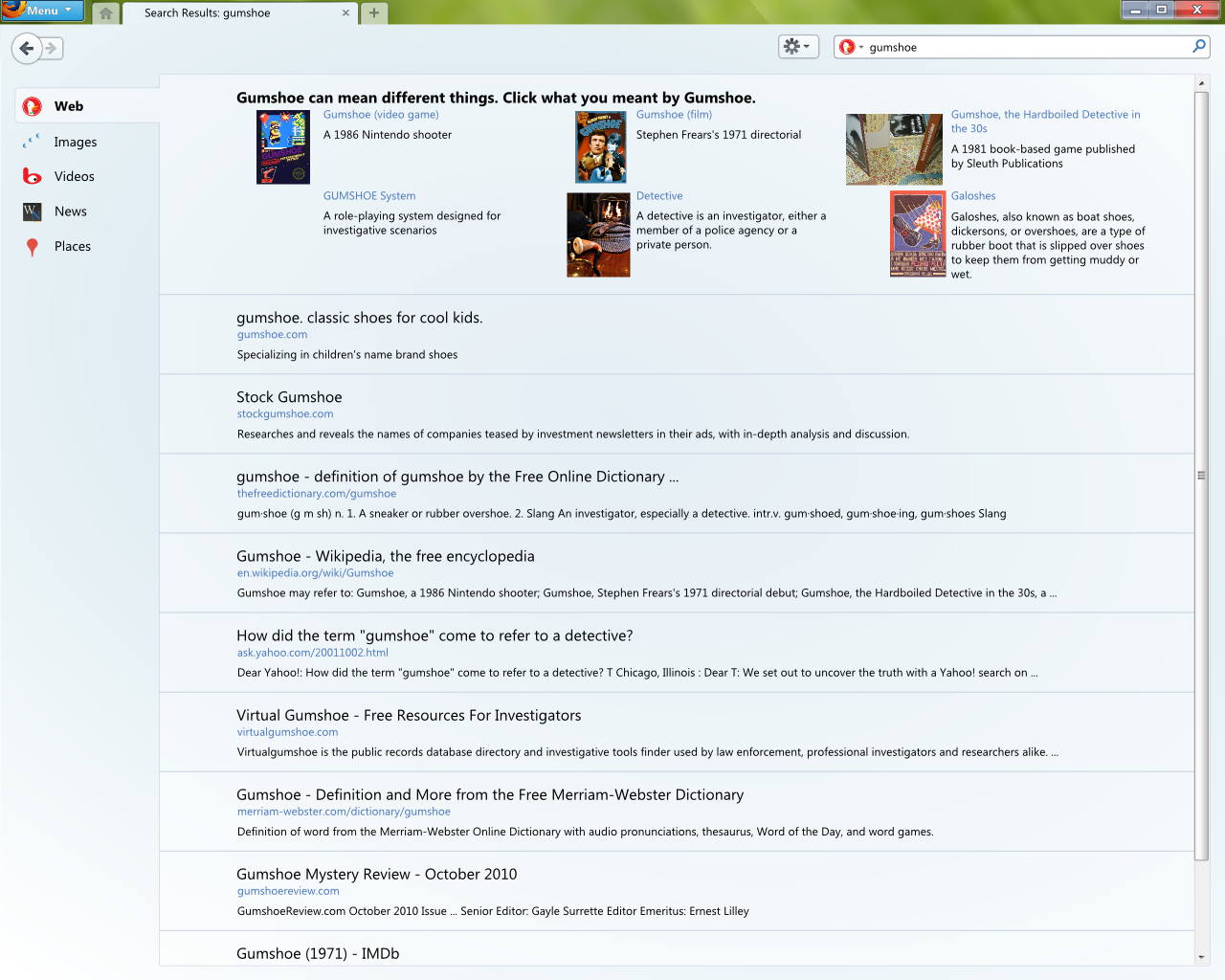
Enfin, les résultats sont prêts à être affichés. Le titre et l’url de la page sont affichés, avec les mots de la requête en gras. Un court résumé est généré et affiché après chaque lien. Le résumé met en évidence les passages importants du document. Pour cela, des phrases sont utilisées à partir des titres, de la description des métadonnées ou du texte qui correspond le mieux à la requête. Si tous les termes de la requête apparaissent dans le titre, ils ne sont pas répétés dans le résumé2. Les phrases sont également sélectionnées en fonction de leur lisibilité.
Des publicités appropriées sont ajoutées aux résultats. La publicité est la façon dont la plupart des moteurs de recherche génèrent des revenus. Dans certains moteurs de recherche, elles sont clairement marquées comme contenu sponsorisé, alors que dans d’autres, elles ne le sont pas. Étant donné que de nombreux utilisateurs ne regardent que les premiers résultats, les publicités apportent un changement substantiel à la totalité du parcours.
Les publicités sont choisies en fonction du contexte de la requête et du modèle d’utilisateur. Les fabricants de moteurs de recherche maintiennent une base de données d’annonces qu’ils utilisent pour trouver les annonces les plus pertinentes pour une requête donnée. Les annonceurs enchérissent pour des mots-clés qui décrivent des sujets associés à leur produit. Le montant de l’enchère et la popularité d’une annonce sont des facteurs importants dans le processus de sélection2.
Pour les questions sur les faits, certains moteurs utilisent leur propre collection de faits. Le Knowledge Vault de Google contient plus d’un milliard de faits indexés à partir de différentes sources3. Les résultats sont regroupés par des algorithmes d’apprentissage automatique dans des groupes appropriés. Enfin, des alternatives à la requête sont également présentées à l’utilisateur pour voir si elles correspondent mieux à son besoin réel.
Quelques références :
L’origine de Google peut être consultée dans l’article original de Brin et Paige ;
Certaines des mathématiques derrière le Pagerank se trouvent sur Wiki’s PageRank ;
Pour les esprits matheux, une belle explication du Pagerank.
1 Russell, D., What Do You Need to Know to Use a Search Engine? Why We Still Need to Teach Research Skills, AI Magazine, 36(4), 2015.
2 Croft, B., Metzler D., Strohman, T., Search Engines, Information Retrieval in Practice, 2015.
3 Spencer, S., Google Power Search: The Essential Guide to Finding Anything Online With Google, Koshkonong, Kindle Edition.
