Contenus additionnels
Apprentissage automatique et IA à travers les expérimentations avec des données d’Orange
Blaž Zupan
Les dauphins sont-ils des mammifères et, si oui, pourquoi ?
A quelle espèce appartiennent les kiwis ?
Les zones climatiques d’Athènes et de Rome sont-elles identiques ?
Qui a peint un célèbre tableau dépeignant une femme qui crie ?
Cet artiste peint-il toujours le ciel de couleur orange ?
Peut-on deviner qui a écrit une publication sur un réseau social grâce à la manière dont la personne écrit ?
En termes de style de jeu, Luka Dončič a-t-il un équivalent au sein de la NBA ?
Peut-on deviner l’espèce d’un arbre grâce à ses feuilles ? A une photo de son écorce ?
Comment les pays du monde se regroupent-ils par caractéristiques socio-économiques ? Le monde est-il vraiment divisé, d’un point de vue socio-économique, entre pays du Nord et pays du Sud ?
Rome et Athènes appartiennent-elles à la même zone climatique ? En termes de conditions météorologiques, quelle capitale est-elle la plus similaire à Berlin ?
La data science, et notamment les méthodes d’apprentissage automatique, servent de catalyseurs du changement dans divers domaines, comme la science, l’ingénierie et la technologie, en ayant un impact significatif sur notre quotidien. Des techniques de calcul capables de faire le tri parmi d’immenses ensembles de données, d’identifier des schémas intéressants et de construire des modèles prédictifs deviennent omniprésentes. Toutefois, seuls quelques professionnels possèdent une compréhension fondamentale de la data science, et ils sont encore moins nombreux à être activement impliqués dans le développement de modèles à partir de leurs données. A une époque où les IA refaçonnent discrètement notre environnement, tout le monde doit être conscient des capacités, des avantages et des risques potentiels de ces technologies. Nous devons mettre en place des méthodes afin d’enseigner les concepts liés à la data science et de les communiquer efficacement à un vaste public. Les principes et les techniques de l’apprentissage automatique, de la data science ainsi que de l’intelligence artificielle doivent être accessibles au plus grand nombre.
Il est possible de répondre à chaque question posée au début de ce chapitre en étudiant les données concernées. Nous proposons une approche qui permet d’entrainer l’apprentissage automatique en commençant par la question, en identifiant les données pertinentes et en répondant à la question grâce à des schémas et des modèles de données pertinents. Dans le cadre du projet Pumice, nous développons des activités pédagogiques qui peuvent être utilisées pour enrichir diverses matières. Les données liées à chaque sujet sont utilisées et étudiées à l’aide d’approches liées aux IA et à l’apprentissage automatique. En partenariat avec des pédagogues, nous avons développé des modèles d’apprentissage et des explications approfondies à destination des enseignants et des étudiants.
Les activités et la formation de Pumice sont prises en charge par Orange, un programme d’apprentissage automatique qui propose une interface intuitive, des visualisations interactives et un système de programmation visuel. Afin de bénéficier de la simplicité nécessaire dans le cadre de la formation, et de la versatilité utile pour couvrir la plupart des principaux sujets et s’adapter aux diverses applications, il convient d’utiliser une structure modulaire des pipelines analytiques et d’exploiter l’interactivité de tous les composants (voir Fig. 1). Afin de continuer à soutenir l’enseignement et à se concentrer sur les concepts plutôt que sur les mécanismes sous-jacents, Orange garantit un accès simplifié aux données, la reproductibilité grâce à la mémorisation des flux de travail (en incluant tous les paramètres et les choix des utilisateurs) et une personnalisation optimisée grâce à la conception de nouveaux composants. Un aspect critique de la formation concerne le storytelling, par le biais de l’inspection des flux de travail et de caractéristiques spécialisées destinées à l’expérimentation, comme la constitution d’ensembles de données expérimentales ou la connaissance de la surinterprétation de la régression polynomiale linéaire. Orange est disponible en tant que logiciel Open Source et il est accompagné d’une brève vidéo de formation.
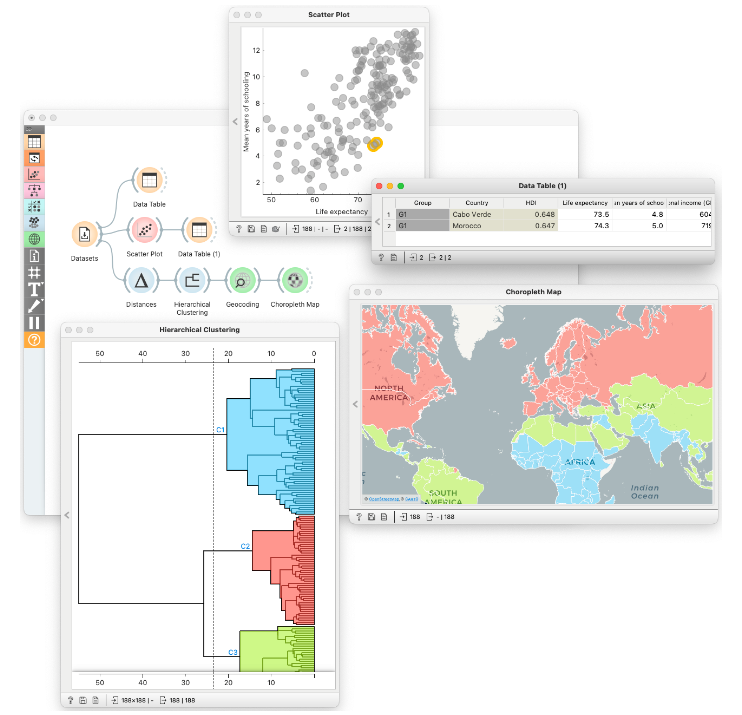
Dans la figure 1, on peut voir un flux de travail d’exploration des données type sur Orange. Le flux de travail comprend des éléments qui chargent les données, calculent les distances, visualisent les données ou les modèles qui en résultent, ou qui exécutent toute tâche nécessaire pour identifier et visualiser des tendances dans les données. Dans ce flux de travail, nous avons utilisé des données socioéconomiques du monde entier. La partie supérieure du flux de travail se penche sur deux caractéristiques et montre une corrélation entre l’espérance de vie et les années passées à étudier. Elle montre également que dans certains pays, comme le Cap Vert et le Maroc, les populations étudient peu mais vivent longtemps. En cours, les élèves peuvent développer ces réseaux afin d’identifier les pays qui sont similaires d’un point de vue socio-économique et découvrir sur la base de quels facteurs le monde est divisé, d’un point de vue socio-économique, entre nord, sud et centre, en observant la grande division entre les parties les plus développées et les moins développées du globe. Il n’est pas nécessaire de leur enseigner cela explicitement : en explorant les données grâce à Orange, les élèves vont le constater par eux-mêmes et, pour les classes supérieures, étudier ces divisions de manière autonome.
Le développement d’Orange a débuté en 2003 et le programme a grandement gagné en popularité depuis. Avec plus de 50000 utilisateurs par mois, Orange s’est imposé comme un logiciel spécialisé largement utilisé. Près de la moitié de ses utilisateurs proviennent du milieu académique. En outre, Orange a connu une hausse notable de son taux d’adoption au sein du secteur de l’enseignement. Plus de 500 universités, dans le monde entier, ont en effet intégré ce logiciel à leurs cours de data science.
Si vous êtes un enseignant et que vous souhaitez vous pencher sur la data science et l’apprentissage automatique, nous avons compilé diverses ressources offrant une présentation de ces disciplines grâce à une exploration pratique des données via Orange :
- Orange, le site web de la boite à outil.
- Une introduction à la data science, sous la forme d’un ensemble de vidéos courtes mettant en avant les méthodes d’affichage et d’ apprentissage automatique d’Orange. Vous trouverez ces vidéos sur : http :/ youtube.com/orangedatamining, dans la playlist « Intro to Data Science ».
- Pumice est un site web destiné aux enseignants, qui recense des cas d’utilisation à intégrer au sein de votre programme de formation.
