Gérer l’éducation
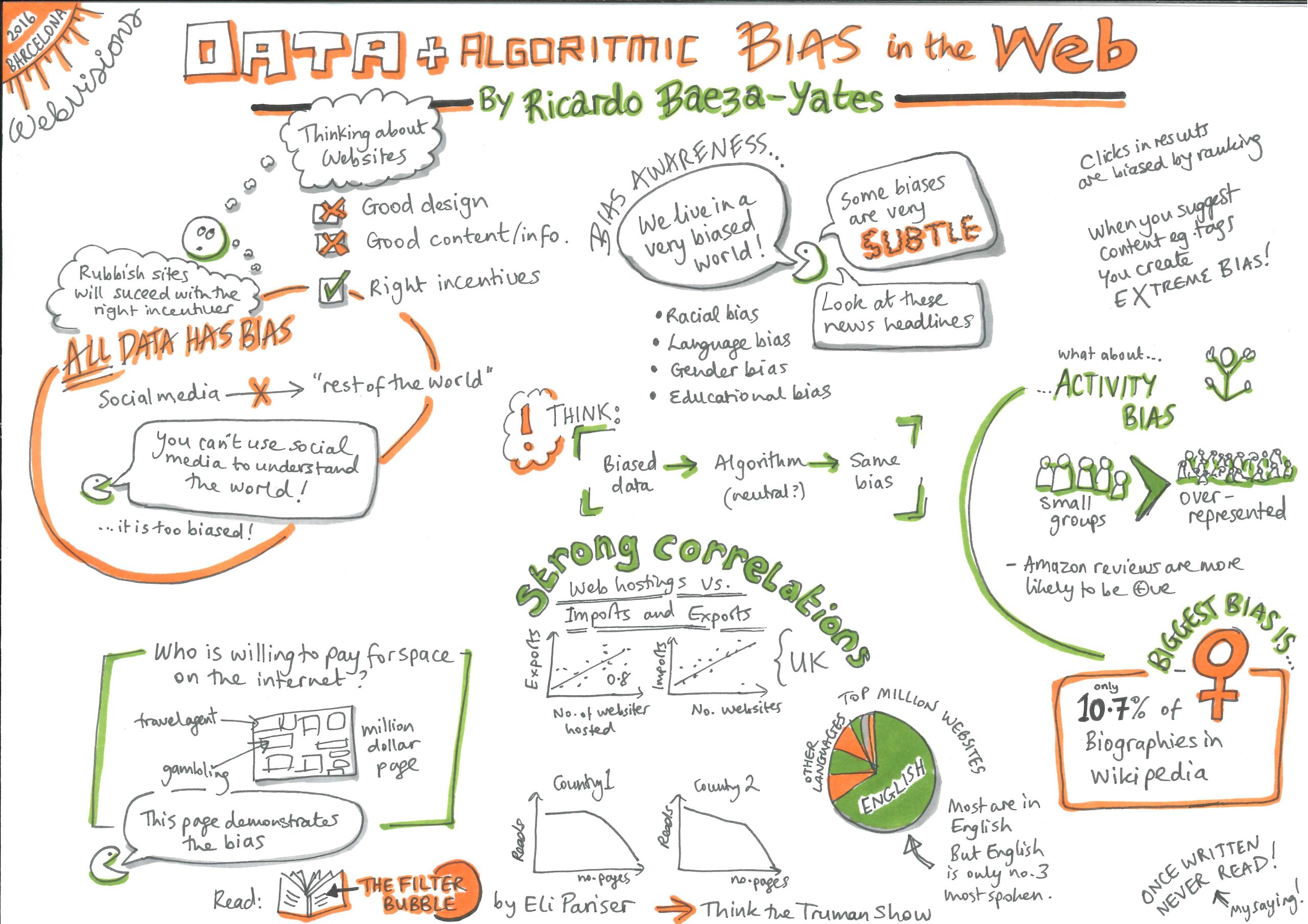
19 Problèmes liés aux données : biais et équité
Le biais est le préjugé, favorable ou défavorable, intentionnel ou involontaire, que l’on peut nourrir vis-à-vis d’une certaine identité1. L’équité est le contraire de ce biais et bien plus encore : être équitable veut dire traiter chacun manière juste, indépendamment de son identité et de sa situation. Des procédures doivent être clairement définies et doivent être respectées pour faire en sorte que chacun soit traité de manière équitable et bénéficie de l’égalité d’accès aux opportunités1.
Les systèmes basés sur l’être humain souffrent souvent de préjugés et de discriminations : chaque personne a son propre ensemble de préjugés et d’opinions. Eux aussi sont des boîtes noires, dont les décisions peuvent être souvent difficiles à comprendre, par exemple leurs critères de notation des réponses aux questionnaires. Mais, nous avons mis en place des stratégies et des structures pour détecter ces pratiques et les contester.
Les systèmes automatisés sont souvent présentés comme la panacée à la subjectivité humaine : les algorithmes se fondent sur les nombres, comment pourraient-ils avoir des préjugés ? Des algorithmes fondés sur des données erronées, entre autres, peuvent non seulement reprendre des préjugés existants en matière de genre, race, culture ou handicap, mais ils peuvent aussi les amplifier1,2,3. Et, pour ne rien arranger, bien qu’ils ne soient pas enfermés derrière des murs de propriété intellectuelle , ils ne peuvent pas être appelés à expliquer leurs actes en raison du manque intrinsèque d’explicabilité de certains systèmes, comme ceux fondés sur des Réseaux Neuronaux Profonds, .
Exemples de biais présents dans les systèmes AIED
- Lorsque les programmeurs codifient des systèmes basés sur des règles, ils peuvent introduire dans les systèmes des biais et des stéréotypes1.
- Un algorithme basé sur les données peut décider de ne pas proposer aux filles un parcours de carrière basé sur les STIM parce que les étudiantes semblent être moins nombreuses d’après les ensembles de données relatifs aux diplômés STIM. Le fait qu’il y ait moins de mathématiciennes est-il dû aux stéréotypes existants et aux normes sociétales ou à des caractéristiques inhérentes aux femmes ? Les algorithmes n’ont aucune possibilité de distinguer entre ces deux options. Puisque les données existantes ne font que refléter les stéréotypes existants, les algorithmes basés sur ces données reproduisent les inégalités et les dynamiques sociales existantes4. De plus, si ces recommandations sont appliquées, plus de femmes opteront pour des matières autres que les STIM et les nouvelles données reflèteront cette situation : un exemple typique de prophétie autoréalisatrice3.
- Les élèves issus d’une culture sous-représentée dans l’ensemble des données d’entraînement peuvent avoir des modèles de comportement différents et des manières différentes de manifester leur motivation. Comment un système d’analyse de l’apprentissage pourrait-il calculer des indicateurs de performance pour eux ? Si les données ne sont pas représentatives de toutes les catégories de clients, les systèmes entraînés sur ces données risquent de pénaliser la minorité dont les tendances comportementales ne correspondent pas à ce que le programme a été optimisé pour récompenser. Si nous ne faisons pas attention, les algorithmes d’apprentissage vont généraliser leur fonctionnement en fonction de la culture majoritaire, ce qui mènera à un taux d’erreur très élevé pour les minorités4,5. Ces décisions pourraient décourager ceux qui sont en mesure d’apporter de la diversité, de la créativité et des talents uniques et ceux qui possèdent des expériences, des intérêts et des motivations différents2.
- Un étudiant britannique qui serait évalué à l’aide d’un logiciel de correction américain serait pénalisé pour des fautes d’orthographe. La langue locale, les différences d’orthographe et d’accent, la géographie et la culture locales seront toujours un piège pour les systèmes qui ont été conçus et entraînés pour un autre pays et un autre contexte.
- Certains enseignants pénalisent – consciemment ou à cause d’associations biaisées de nature sociale – des expressions typiques d’une certaine classe ou d’une certaine région. Si un logiciel de notation de dissertations est entraîné sur des essais qui ont été notés par ces enseignants, il reproduira les mêmes préjugés.
- Les systèmes d’apprentissage automatique nécessitent une variable cible et des variables de substitution pour être optimisés. Supposons que les notes obtenues aux tests des écoles secondaires soient utilisées comme proxy pour la mesure de l’excellence académique. Les systèmes vont maintenant s’entraîner uniquement à mettre en avant les modèles conformes aux élèves qui sont capables d’obtenir de bons résultats sous pression et dans le contexte restreint des salles d’examen. Ces systèmes chercheront à mettre l’accent sur les résultats des tests et non pas sur le niveau de connaissances général lorsqu’il s’agira de recommander des ressources et des exercices pratiques pour les étudiants. Bien que cela puisse être également le cas dans de nombreuses salles de classe, aujourd’hui, l’approche traditionnelle permet, au moins, d’exprimer des objectifs multiples4.
- Les systèmes d’apprentissage adaptatifs suggèrent aux élèves des ressources utiles pour remédier à un manque de connaissances ou de compétences. Si ces ressources doivent être achetées ou nécessitent une connexion internet à la maison, ceci crée une injustice par rapport aux étudiants qui n’ont pas les moyens de suivre ces recommandations. “Quand un algorithme apporte des conseils ou suggère les prochaines étapes à suivre ou des ressources à un(e) élève, nous devons vérifier si l’aide proposée est équitable ou non parce qu’un certain groupe ne bénéficie systématiquement pas d’une aide utile, ce qui est discriminatoire ”2.
- L’idée qui consiste à personnaliser l’éducation selon le niveau de connaissances et les goûts actuels d’un étudiant peut constituer, en soi, un biais1. N’empêchons-nous pas également cet élève d’explorer de nouveaux domaines et de nouvelles options ? Cette approche n’est-elle pas réductive en termes de compétences et de connaissances globales et ne restreint-elle pas l’accès à d’autres opportunités ?
Qu’est-ce qu’un enseignant peut-il faire pour réduire les effets des biais de l’AIED ?
Les chercheurs ne cessent de proposer différentes manières de réduire les biais, mais toutes les solutions ne sont pas faciles à mettre en œuvre. Sans oublier que l’équité va bien au-delà de la simple atténuation des préjugés.
Par exemple, si les données existantes sont remplies de stéréotypes “sommes-nous tenus de remettre en question les données et de concevoir nos propres systèmes pour qu’ils soient conformes à une certaine notion de comportement équitable, même si cette notion n’est pas étayée par les données actuellement disponibles ?”4. Les méthodes sont toujours en tension et en opposition les unes avec les autres, et certaines interventions visant à atténuer un certain type de biais peuvent en créer un autre !
Alors, que peut faire l’enseignant ?
- Poser une question au vendeur : avant de souscrire un abonnement à un système AIED, demandez quels types d’ensembles de données ont été utilisés pour entraîner le système, où, par et pour qui le système a été conçu et comment il a été évalué.
- Ne prenez pas pour argent comptant les indicateurs de mesure des performances qui vous sont vendus. Une précision globale, disons, de “5% d’erreur” peut cacher le fait que le système fonctionne très mal pour un groupe minoritaire4.
- Examinez la documentation : quelles mesures ont été prises pour détecter et contrer les biais et faire valoir un principe d’équité1 ?
- Obtenez des informations concernant les développeurs : s’agit-il seulement d’informaticiens spécialisés ou bien des chercheurs en pédagogie et des enseignants ont également participé à toutes les étapes du processus ? Le système est-il exclusivement basé sur l’Apprentissage Automatique ou bien des théories et des méthodes d’apprentissage ont-elles également été prises en compte2 ?
- Privilégiez des modèles d’apprentissage transparents et ouverts, qui vous permettent de passer outre les décisions2 : Beaucoup de modèles AIED possèdent une structure flexible qui permet à l’enseignant, et même à l’élève, de contrôler, demander des explications ou ignorer complètement la décision automatique.
- Vérifiez l’accessibilité du produit : est-il accessible à tout le monde de la même façon, en particulier en ce qui concerne les élèves handicapés ou qui présentent des besoins éducatifs particuliers1?
- Soyez attentifs aux effets, à long et court terme, de l’utilisation d’une technologie, sur vos élèves et dans la classe et soyez prêts à fournir votre assistance, si nécessaire.
Malgré les problèmes liés à la technologie basée sur l’IA, nous avons aussi des raisons de nous montrer optimistes quant au futur de l’AIED :
- Grâce à une plus grande sensibilisation à ces sujets, des méthodes de détection et de correction des biais font l’objet de recherches et d’essais.
- Les systèmes fondés sur les règles et les systèmes fondés sur les données avec un certain niveau d’explicabilité font ressortir des préjugés cachés dans les pratiques éducatives existantes. En nous permettant d’articuler nos pensées et nos processus, ils nous obligent à revérifier nos bases et à « faire le ménage».
- Grâce au potentiel de personnalisation des systèmes IA, nous pourrions personnaliser de nombreux aspects de l’éducation. Les ressources pourraient être adaptées aux connaissances et aux expériences de chaque élève. Elles pourraient intégrer les communautés et le patrimoine culturel locaux pour répondre à des besoins spécifiques de nature locale2.
1 Ethical guidelines on the use of artificial intelligence and data in teaching and learning for educators, European Commission, October 2022.
2 U.S. Department of Education, Office of Educational Technology, Artificial Intelligence and Future of Teaching and Learning: Insights and Recommendations, Washington, DC, 2023.
3 Kelleher, J.D, Tierney, B, Data Science, MIT Press, London, 2018.
4 Barocas, S., Hardt, M., Narayanan, A., Fairness and machine learning Limitations and Opportunities, 2022.
5 Milano, S., Taddeo, M., Floridi, L., Recommender systems and their ethical challenges, AI & Soc 35, 957–967, 2020.
