Recherche d’informations
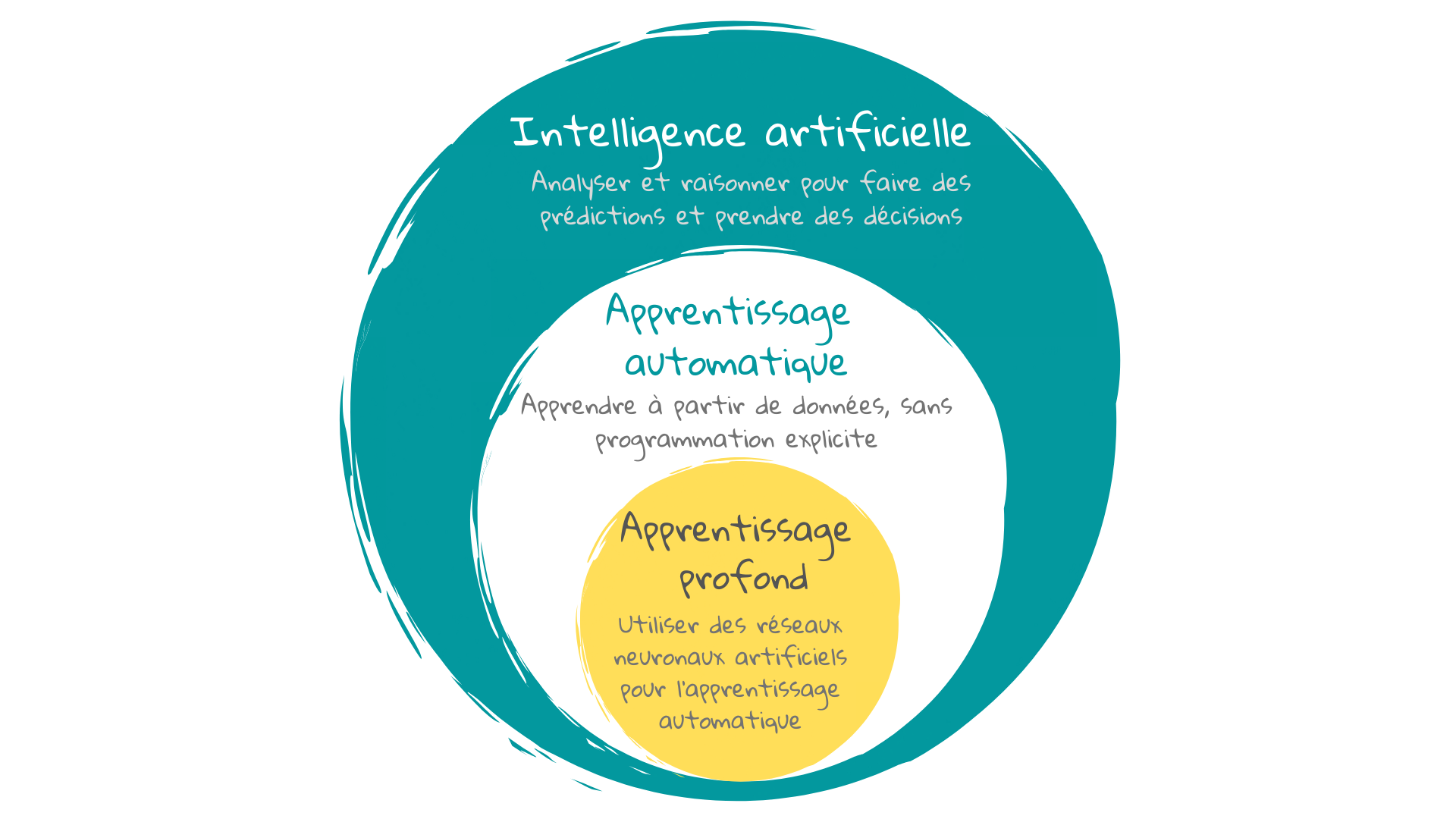
9 Parlons IA : Apprentissage automatique
Un algorithme est une séquence fixe d’instructions pour l’exécution d’une tâche. Il décompose la tâche en étapes simples et sans ambiguïté : comme une recette bien écrite.
Les langages de programmation sont des langages qu’un ordinateur peut suivre et exécuter. Ils servent de pont entre ce que nous pouvons comprendre et ce qu’une machine peut – en définitive, des interrupteurs qui s’allument et s’éteignent. Pour un ordinateur, les images, les vidéos, les instructions sont toutes des 1 (interrupteur allumé) et des 0 (interrupteur éteint).
Une fois écrit dans un langage de programmation, un algorithme devient un programme. Les applications sont des programmes écrits pour un usager.
Les programmes classiques prennent des données et suivent les instructions pour générer une sortie. De nombreux premiers programmes d’IA étaient des programmes classiques. Comme les instructions ne peuvent pas s’adapter aux données, ces programmes n’étaient pas très performants pour certaines tâches comme la prédiction sur la base d’informations incomplètes et le traitement automatique de la langue naturelle (TALN).
 Un moteur de recherche est alimenté à la fois par des algorithmes classiques et des algorithmes d’apprentissage automatique. Contrairement aux logiciels classiques, les algorithmes ML analysent les données afin de découvrir des tendances et utilisent ces tendances ou règles pour prendre des décisions ou faire des prédictions. C’est-à-dire qu’en se basant sur des données – de bons et de mauvais exemplaires, ils trouvent leur propre recette.
Un moteur de recherche est alimenté à la fois par des algorithmes classiques et des algorithmes d’apprentissage automatique. Contrairement aux logiciels classiques, les algorithmes ML analysent les données afin de découvrir des tendances et utilisent ces tendances ou règles pour prendre des décisions ou faire des prédictions. C’est-à-dire qu’en se basant sur des données – de bons et de mauvais exemplaires, ils trouvent leur propre recette.
De tels algorithmes sont bien adaptés aux situations très complexes et aux données manquantes. Ils peuvent également surveiller leurs performances et utiliser ce retour pour s’améliorer à l’usage.
Ce n’est pas très éloigné de ce que font les êtres humains, notamment les bébés qui développent des compétences en dehors du système éducatif conventionnel. Les bébés observent, répètent, apprennent, mettent en pratique leurs connaissances et s’améliorent. Si nécessaire, ils improvisent.
Mais la similarité entre les machines et les humains est très peu profonde. « Apprendre » d’un point de vue humain est bien différent, et bien plus nuancé et compliqué que « l’apprentissage » pour la machine.
Un problème de classement
Une des tâches courantes d’une application ML est le classement – Est-ce la photo d’un chien ou d’un chat ? Cet étudiant a-t-il des difficultés ou a-t-il réussi son examen ? Il y a deux ou plusieurs groupes. Et l’application doit classer les nouvelles données dans l’un de ces groupes.
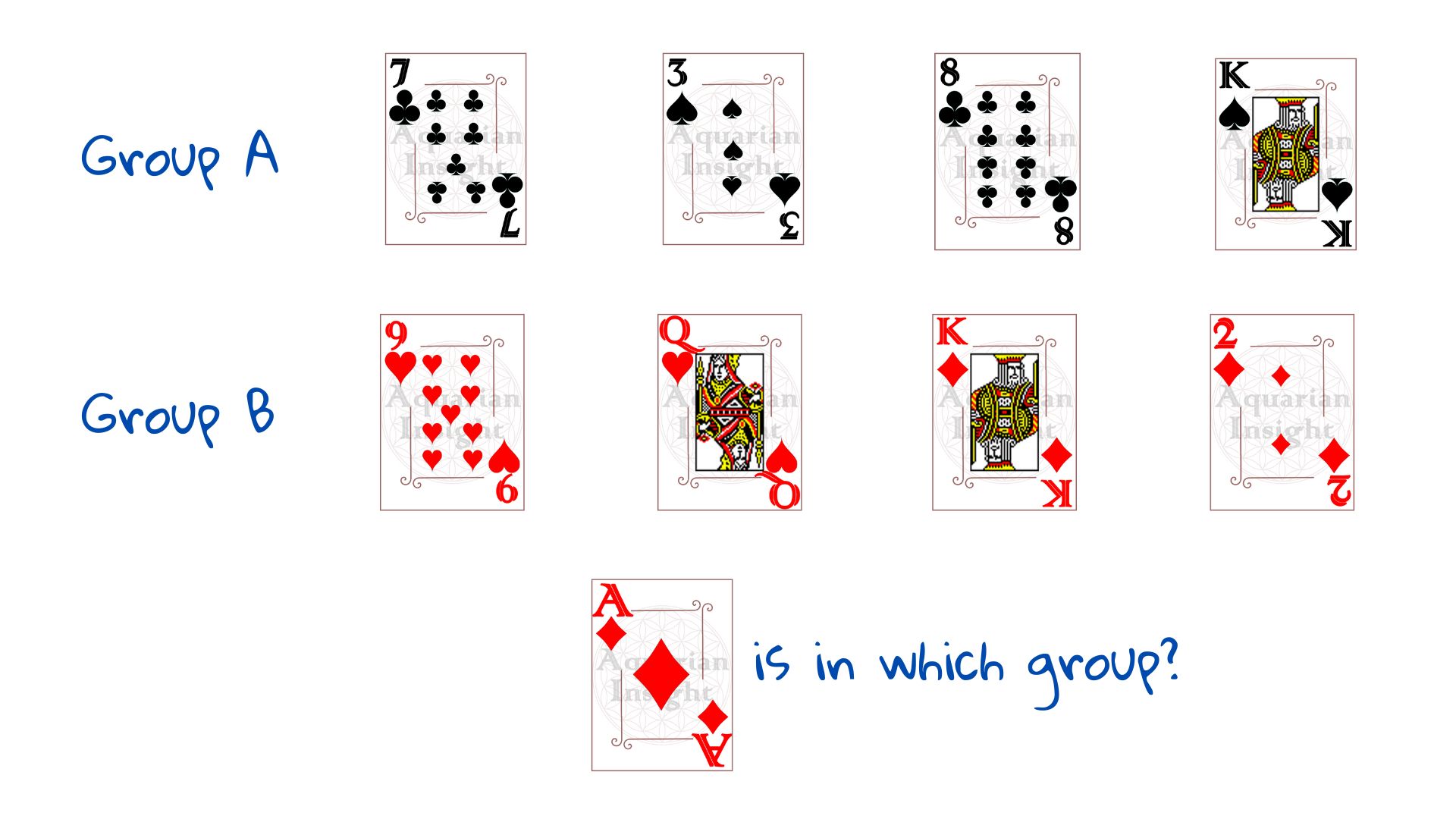
Prenons l’exemple des cartes à jouer divisées en deux piles – Groupe A et Groupe B, suivant un certain modèle. Nous devons classer une nouvelle carte, l’as de carreau, dans le groupe A ou le groupe B.
Tout d’abord, nous devons comprendre comment les groupes sont répartis – nous avons besoin des exemples. Tirons quatre cartes du groupe A et quatre du groupe B. Ces huit exemples constituent notre ensemble d’apprentissage – des données qui nous aident à percevoir le schéma – ce qui nous « apprend » à constater le résultat.
Dès qu’on nous montre la répartition à droite, la plupart d’entre nous devinent que l’As de carreau appartient au groupe B. Nous n’avons pas besoin d’instructions, le cerveau humain est une merveille de détection de modèles. Comment une machine ferait-elle cela ?
Les algorithmes d’apprentissage automatique reposent sur de puissantes théories statistiques. Les différents algorithmes sont basés sur différentes équations mathématiques qui doivent être choisies avec soin pour s’adapter à la tâche à effectuer. C’est le travail du programmeur de choisir les données, d’analyser quelles caractéristiques des données sont pertinentes pour le problème particulier et de choisir l’algorithme approprié.
L’importance des données
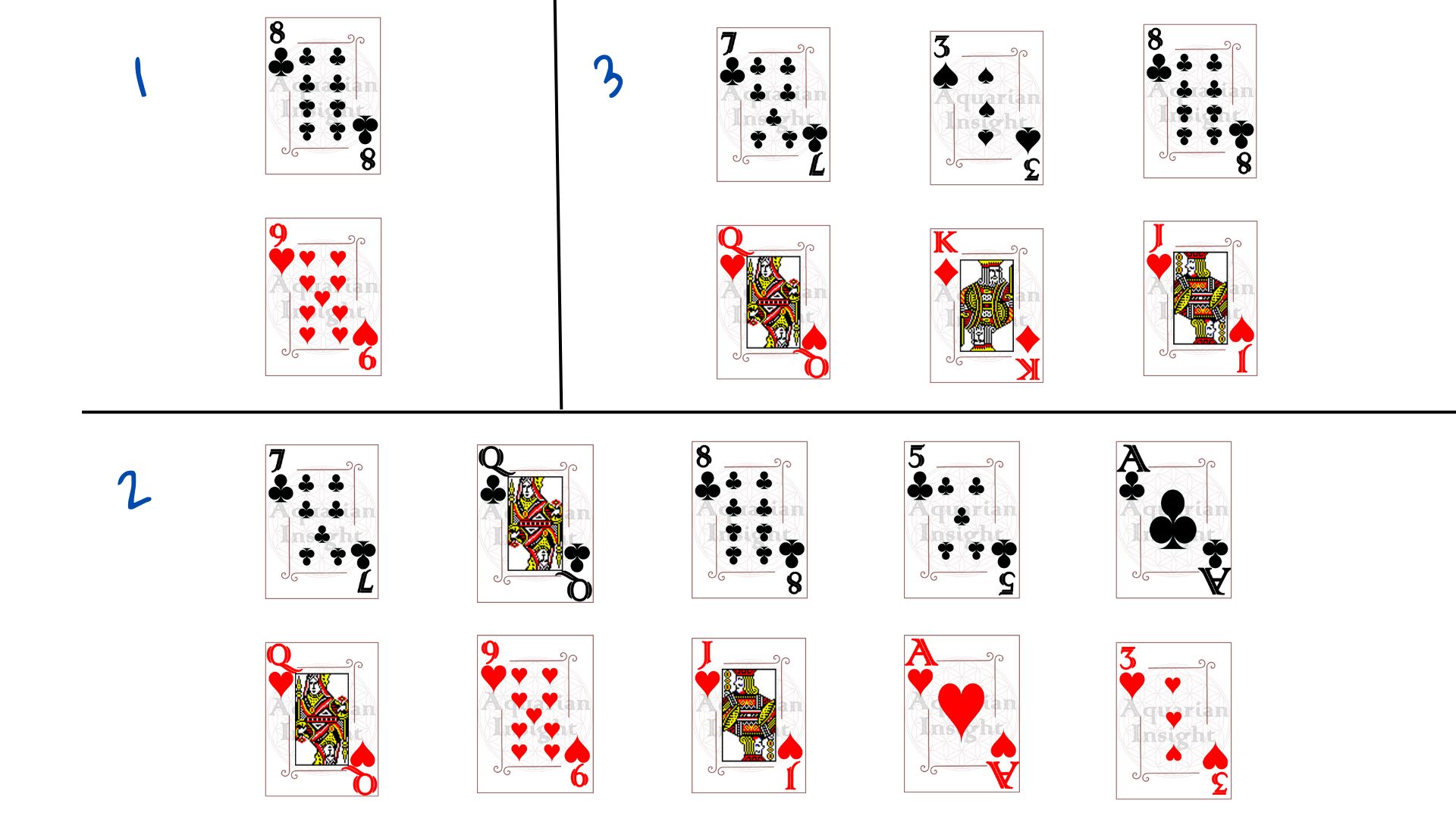
Le tirage de la carte ci-dessus aurait pu échouer de plusieurs façons. Veuillez vous référer à l’image. 1 a trop peu de cartes, aucune déduction ne serait possible. 2 a plus de cartes mais toutes de la même famille – aucun moyen de savoir où irait le carreau. Si les groupes n’étaient pas de la même taille, 3 pourrait très bien signifier que les cartes de chiffres sont dans le groupe A et les cartes d’image dans le groupe B.
En général, les tâches d’apprentissage automatique sont plus ouvertes et impliquent des ensembles de données bien plus importants qu’un jeu de cartes. Les ensembles d’apprentissage doivent être choisis à l’aide de l’analyse statistique, sinon des erreurs apparaissent. Une meilleure sélection des données est cruciale pour une bonne application d’apprentissage automatique, plus que pour d’autres types de logiciels. L’apprentissage automatique a besoin d’un grand nombre de données pertinentes. Au minimum absolu, un modèle d’apprentissage automatique de base devrait contenir dix fois plus de points de données que le nombre total de traits1. Cependant, l’apprentissage automatique est aussi particulièrement bien équipé pour traiter des données bruyantes, désordonnées et contradictoires.
Extraction de traits
Lorsque vous avez vu les exemples du groupe A et du groupe B ci-dessus, la première chose que vous avez peut-être remarquée est la couleur des cartes. Puis le numéro ou la lettre et la couleur. Pour un algorithme, toutes ces caractéristiques doivent être saisies explicitement. Il ne peut pas savoir automatiquement ce qui est important pour le résultat du problème.
En choisissant les traits d’intérêt, les programmeurs doivent se poser de nombreuses questions. Combien de traits sont trop peu nombreux pour être utiles ? Combien de traits sont trop nombreux ? Quelles caractéristiques sont pertinentes pour la tâche ? Quelle est la relation entre les éléments choisis – un aspect dépend-il d’un autre ? Avec les traits choisis, est-il possible que la sortie soit précise ?
Le Processus
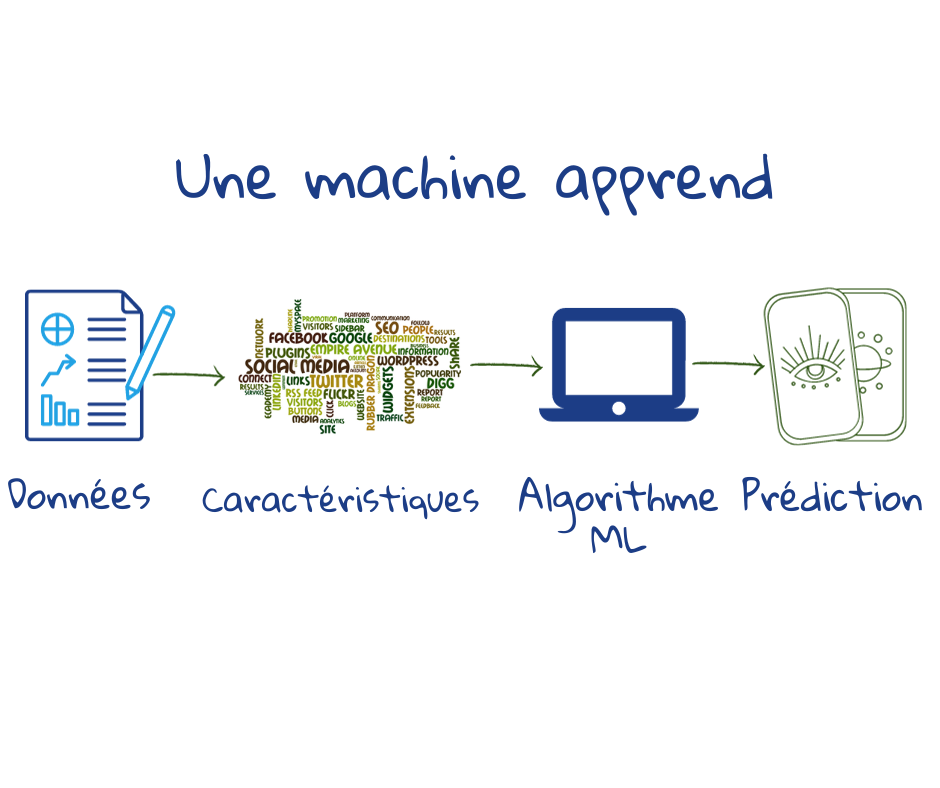
Lorsque le programmeur crée l’application – il prend des données, en extrait des traits, choisit un algorithme d’apprentissage automatique pertinent (fonction mathématique qui définit le processus), et l’entraîne en utilisant des données étiquetées (dans le cas où la sortie est connue – comme le groupe A ou le groupe B) afin que la machine comprenne le modèle qui se cache derrière le résultat.
Pour une machine la compréhension prend la forme d’un ensemble de chiffres – les poids – qu’elle attribue à chaque trait. Avec la bonne attribution des poids, elle peut calculer la probabilité qu’une nouvelle carte se trouve dans le groupe A ou le groupe B. Généralement, pendant la phase d’apprentissage, le programmeur aide la machine en modifiant manuellement certaines valeurs – c’est ce qu’on appelle le tuning ou réglage de l’application.
Une fois cela fait, le logiciel doit être testé avant d’être mis en service. Pour cela, les données étiquetées qui n’ont pas été utilisées pour l’apprentissage seront fournies. C’est ce qu’on appelle les données de test. La performance de la machine à prédire la sortie sera alors évaluée. Une fois qu’il est satisfaisant, le logiciel peut être mis en service : il est prêt à prendre de nouvelles données et à en tirer une décision ou une prédiction.
Un modèle peut-il fonctionner différemment sur les ensembles de données d’apprentissage et de test ? Comment le nombre de caractéristiques affecte-t-il les performances dans les deux cas ? Regardez cette vidéo pour le savoir.
La performance en temps réel est ensuite surveillée et améliorée en permanence (les poids des traits sont ajustés pour obtenir de meilleurs résultats). Souvent, les performances en temps réel donnent des résultats différents de ceux obtenus lorsque l’apprentissage automatique est testé avec des données déjà disponibles. Étant donné que l’expérimentation avec de vrais utilisateurs est coûteuse, exige un effort important et est souvent risquée, les algorithmes sont toujours testés à l’aide de données utilisateurs historiques, qui ne permettent pas toujours d’évaluer l’impact sur le comportement des utilisateurs1. C’est pourquoi il est primordial une évaluation complète des outils d’apprentissage automatique une fois utilisés :
Envie de mettre la main à la pâte sur l’apprentissage automatique ? Essayez cette activité.
1 Theobald, O. Machine Learning For Absolute Beginners: A Plain English Introduction (Second Edition) (Machine Learning From Scratch Book 1) (p. 24). Scatterplot Press. Kindle Edition.
2 Konstan, J., Terveen, L., Human-centered recommender systems: Origins, advances, challenges, and opportunities, AI Magazine, 42(3), 31-42, 2021.

{kind=link}
.jpg){kind=link}